

1 Introduction
Riemannian manifolds are often used to model the sample space in which features derived from the raw data encountered in many medical imaging applications live. Common examples include the diffusion tensors (DTs) in diffusion tensor imaging (DTI) (Basser et al., 1994), the ensemble average propagator (EAP) (Callaghan, 1993). Both DTs and EAP are used to capture the diffusional properties of water molecules in the central nervous system by non-invasively imaging the tissue via diffusion weighted magnetic resonance imaging. In DTI, diffusion at a voxel is captured by a DT, which is a symmetric positive-definite matrix, whereas EAP is a probability distribution characterizing the local diffusion at a voxel, which can be parametrized as a point on the Hilbert sphere. Another example is the shape space used to represent shapes in shape analysis. There are many ways to represent a shape, and the most simple one is to use landmarks. For the landmark-based representation, the shape space is called Kendall’s shape space (Kendall, 1984). Kendall’s shape space is in general a stratified space (Goresky and MacPherson, 1988; Feragen et al., 2014), but for the special case of planar shapes, the shape space is the complex projective space, which is a complex Grassmann manifold. The examples mentioned above are often high-dimensional: a DTI scan usually contains half a million DTs; the shape of the Corpus Callosum (which is used in our experiments) is represented by a several hundreds of boundary points in . Thus, in these cases, dimension reduction techniques, if applied appropriately, can benefit the subsequent statistical analysis.
For data on Riemannian manifolds, the most widely used dimensionality reduction method is the principal geodesic analysis (PGA) (Fletcher et al., 2004), which generalizes the principal component analysis (PCA) to manifold-valued data. In fact, there are many variants of PGA. Fletcher et al. (2004) proposed to find the geodesic submanifold of a certain dimension that maximizes the projected variance and computationally, it was achieved via a linear approximation, i.e., applying PCA on the tangent space at the intrinsic mean. This is sometimes referred to as the tangent PCA. Note that this approximation requires the data to be clustered around the intrinsic mean, otherwise the tangent space approximation to the manifold leads to inaccuracies. Later on, Sommer et al. (2010) proposed the Exact PGA (EPGA), which does not use any linear approximation. However, EPGA is computationally expensive as it requires two non-linear optimizations steps per iteration (projection to the geodesic submanifold and finding the new geodesic direction such that the loss of information is minimized). Chakraborty et al. (2016) partially solved this problem for manifolds with constant sectional curvature (spheres and hyperbolic spaces) by deriving closed form formulae for the projection. Other variants of PGA include but are not limited to sparse exact PGA (Banerjee et al., 2017), geodesic PCA (Huckemann et al., 2010), and probabilistic PGA (Zhang and Fletcher, 2013). All these methods focus on projecting data to a geodesic submanifold as in PCA where one projects data to a vector subspace. Instead, one can also project data to a submanifold that minimizes the reconstruction error without any further restrictions, e.g. being geodesic. This is the generalization of the principal curve (Hastie and Stuetzle, 1989) to Riemannian manifolds presented in Hauberg (2016).
Another feature of PCA is that it produces a sequence of nested vector subspaces. From this observation, Jung et al. (2012) proposed the principal nested spheres (PNS) by embedding an -sphere into an -sphere, and the embedding is not necessarily isometric. Hence PNS is more general than PGA in that PNS is not required to be geodesic. Similarly, for the manifold of SPD matrices, Harandi et al. (2018) proposed a geometry-aware dimension reduction by projecting data in to for some . They also applied the nested for the supervised dimensionality reduction problem. Damon and Marron (2014) considered a nested sequence of relations which determine a nested sequence of submanifolds that are not necessarily geodesic. They showed various examples, including Euclidean space and the -sphere, depicting how the nested relations generalized PCA and PNS. However, for an arbitrary Riemannian manifold, it is not clear how to construct a nested submanifold. Another generalization of PGA was proposed by Pennec et al. (2018), called the exponential barycentric subspace (EBS). A -dimensional EBS is defined as the locus of weighted exponential barycenters of affinely independent reference points. The EBSs are naturally nested by removing or adding reference points.
Unlike PGA which can be applied to any Riemannian manifolds, the construction of the nested manifolds relies heavily on the geometry of the specific manifold, and there is no general principle for such a construction. All the examples described above (spheres and ) and several others such as the Grassmannian, Stiefel etc. are homogeneous Riemannian manifolds (Helgason, 1979), which intuitively means that all points on the manifold ’look’ the same. In this work, we propose a general framework for constructing a nested sequence of homogeneous Riemannian manifolds, and, via some simple algebraic computation, show that the nested sphere and the nested can indeed be derived within this framework. We will then apply this framework to the Grassmann manifolds, called the nested Grassmann manifolds (NG). The Grassmann manifold is the manifold of all -dimensional subspaces of the vector space where . Usually or . An important example is Kendall’s shape space of 2D shapes. The space of all shapes determined by landmarks in is denoted by , and Kendall (1984) showed that it is isomorphic to the complex projective space . In many applications, the number of landmarks is large, and so is the dimension of . The core of the proposed dimensionality reduction involves projecting data on to with . The main contributions of this work are as follows: (i) We propose a general framework for constructing a nested sequence of homogeneous Riemannian manifolds unifying the recently proposed nested spheres (Jung et al., 2012) and nested SPD manifolds (Harandi et al., 2018). (ii) We present novel dimensionality reduction techniques based on the concept of NG in both supervised and unsupervised settings respectively. (iii) We demonstrate via several simulation studies and real data experiments, that the proposed NG can achieve a higher ratio of expressed variance compared to PGA.
The rest of the paper is organized as follows. In Section 2, we briefly review the definition of homogeneous Riemannian manifolds and present the recipe for the construction of nested homogeneous Riemannian manifolds. In Section 3, we first review the geometry of the Grassmannian. By applying the procedure developed in Section 2, we present the nested Grassmann manifolds representation and discuss some of its properties in details. Then we describe algorithms for our unsupervised and supervised dimensionality reduction techniques, called the Principal Nested Grassmanns (PNG), in Section 4. In Section 5, we present several simulation studies and experimental results showing how the PNG technique performs compared to PGA under different settings. Finally, we draw conclusions in Section 6.
2 Nested Homogeneous Spaces
In this section, we introduce the structure of nested homogeneous Riemannian manifolds. A Riemannian manifold is homogeneous if the group of isometries admitted by the manifold acts transitively on (Helgason, 1979), i.e., for , there exists such that . In this case, can be identified with where is an isotropy subgroup of at some point , i.e. . Examples of homogeneous Riemannian manifolds include but are not limited to, the -spheres , the SPD manifolds , the Stiefel manifolds , and the Grassmann manifolds .
In this paper, we focus on the case where is either a real or a complex matrix Lie group, i.e. is a subgroup of or . The main idea behind the construction of nested homogeneous spaces is simple: augmenting the matrix in in an appropriate way. With an embedding of the isometry group , the embedding of the homogeneous space follows naturally from the quotient structure.
Let and be two connected Lie groups such that and be an embedding. For a closed connected subgroup of , let . Since is an embedding, is also a closed subgroup of . Now the canonical embedding of in is defined by for . It is easy to see that is well-defined. Let be such that for some . Then
Now for the homogeneous Riemannian manifolds and , denote the left--invariant, right--invariant metric on (resp. left--invariant, right--invariant metric on ) by and , respectively (see Cheeger and Ebin (1975, Prop. 3.16(4))).
Proposition 1
If is isometric, then so is .
Proof Denote the Riemannian submersions by and . Let and be vector fields on and and be their horizontal lifts respectively, i.e. and . By the definition of Riemannian submersions, is isometric on the horizontal spaces, i.e. . Since is isometric, we have . By the definition of , we also have , which implies . Hence,
where the third equality follows from the isometry of .
Proposition 1 simply says that if the isometry group is isometrically embedded, then the associated homogeneous Riemannian manifolds will also be isometrically embedded. Conversely, if we have a Riemannian submersion , it can easily be shown that the induced map would also be a Riemannian submersion where . The construction above can be applied to a sequence of homogeneous spaces , i.e. the embedding can be induced from the embedding of the isometry groups where provided for . See Figure 1 for the structure of nested homogeneous spaces.
3 Nested Grassmann Manifolds
In this section, we will apply the theory of nested homogeneous space from the previous section to the Grassmann manifolds. First, we briefly review the geometry of the Grassmann manifolds in Section 3.1. With the theory in Section 2, we derive the nested Grassmann manifolds in Section 3.2, and the derivation for nested spheres and nested SPD manifolds are carried out in Section 3.3.
3.1 The Riemannian Geometry of Grassmann Manifolds
To simplify the notation, we assume and write . All the results presented in this section can be easily extended to the case of by replacing transposition with conjugate transposition and orthogonal groups with unitary groups. The Grassmann manifold is the manifold of all -dimensional subspaces of , and for a subspace , we write where the columns of form an orthonormal basis for . The space of all matrices such that is called the Stiefel manifold, denoted by . Special cases of Stiefel manifolds are the Lie group of all orthogonal matrices, , and the -sphere, . The Stiefel manifold with the induced Euclidean metric (i.e. for , ) is a homogeneous Riemannian manifold, . A canonical Riemannian metric on the Grassmann manifold can be inherited from the metric on since it is invariant to the left multiplication by elements of (Absil et al., 2004; Edelman et al., 1998). The Grassmann manifold with this metric is also homogeneous, .
With this canonical metric on the Grassmann manifolds, the geodesic can be expressed in closed form. Let where and be an matrix. Then the geodesic with and is given by where is the compact singular value decomposition (Edelman et al., 1998, Theorem 2.3). The exponential map at is a map from to defined by . If is invertible, the geodesic distance between and is given by where , , , and . The diagonal entries of are known as the principal angles between and .
3.2 Embedding of in
Let , . The map , for , defined by
is an embedding and it is easy to check that this embedding is isometric (Ye and Lim, 2016, Eq. (8)). However, for the dimensionality reduction problem, the above embedding is insufficient as it is not flexible enough to encompass other possible embeddings. To design flexible embeddings, we apply the framework proposed in Section 2. We consider for which the isometry groups are and .
In this paper, we consider the embedding given by,
| (3) |
where , , , , , and is the Gram-Schmidt process. Since the Riemannian submersion is defined by where and is the matrix containing the first columns of , the induced embedding is given by,
where , , contains the first columns of (which means ), is the last column of , and . It is easy to see that for and , this gives the natural embedding described in Ye and Lim (2016) and at the beginning of this section.
Proposition 2
If , then is an isometric embedding.
Proof With Proposition 1, it suffices to show that is isometric when . Note that as is independent of and in the definition of , we can assume and without loss of generality. If , simplifies to
where . The Riemannian distance on given the induced Euclidean metric is . Then for ,
Therefore is an isometric embedding, and so is by Proposition 1.
With the embedding , we can construct the corresponding projection using the following proposition.
Proposition 3
The projection corresponding to is given by .
Proof First, let and be such that . Then for some . Therefore, and . Hence, the projection is given by . This completes the proof.
Note that for , where and . The nested relation can be extended inductively and we refer to this construction as the nested Grassmann structure:
Thus the embedding from into can be constructed inductively by and similarly for the corresponding projection. The explicit forms of the embedding and the projection are given in the following proposition.
Proposition 4
The embedding of into for is given by where and such that . The corresponding projection from to is given by .
Proof By the definition, and thus the embedding can be simplified as
where , is such that , , , and is an matrix. It is easy to see that . Similar to Proposition 3, the projection is then given by . This completes the proof.
From Proposition 2, if then is an isometric embedding. Hence, our nested Grassmann structure is more flexible than PGA as it allows one to project the data onto a non-geodesic submanifold. An illustration is shown in Figure 2. The results discussed in this subsection can be generalized to any homogeneous space in principle. For a given homogeneous space, once the embedding of the groups of isometries (e.g., Eq. (3)) is determined, the induced embedding and the corresponding projection can be derived akin to the case of Grassmann manifolds.
3.3 Connections to Other Nested Structures
The nested homogeneous spaces proposed in this work (see Figure 1) actually provides a unified framework within which, the nested spheres (Jung et al., 2012) and the nested SPD manifolds (Harandi et al., 2018) are special cases.
The -Sphere Example: Since the -sphere can be identified with a homogeneous space , with the embedding (3), the induced embedding of into is
where , , and . This is precisely the nested sphere proposed in Jung et al. (2012, Eq. (2)).
The SPD Manifold Example: For the -dimensional SPD manifold denoted by , and . Consider the embedding given by
where , and the corresponding projection is
where contains the first columns of (i.e., and ). The submersion is given by . Hence the induced embedding and projection are
which is the projection map used in Harandi et al. (2018, Eq. (13)). However, Harandi et al. (2018) did not perform any embedding or construct a nested family of SPD manifolds. Recently, it came to our attention that Jaquier and Rozo (2020) derived a similar nested family of SPD manifolds based on the projection maps in Harandi et al. (2018) described above.
4 Dimensionality Reduction with Nested Grassmanns
In this section, we discuss how to apply the nested Grassmann structure to the problem of dimension reduction. In Section 4.1 and 4.2, we describe the unsupervised and supervised dimension reduction based on the nested Grassmann manifolds. In Section 4.3, we will discuss the choice of distance metrics required by the dimensionality reduction algorithm and present some technical details regarding the implementation. Analysis of principal nested Grassmann (PNG) will be introduced and discussed in Section 4.4 and Section 4.5.
4.1 Unsupervised Dimensionality Reduction
We can now apply the nested Grassmann structure to the problem of unsupervised dimensionality reduction. Suppose that we are given the points, . We would like to have lower dimensional representations in for with . The desired projection map that we seek is obtained by the minimizing the reconstruction error, i.e.
where is a distance metric on . It is clear that has a -symmetry in the first argument, i.e. for . Hence, the optimization is performed over the space when optimizing with respect to this particular loss function. Now we can apply the Riemannian gradient descent algorithm (Edelman et al., 1998) to obtain and by optimizing over and such that . Note that the restriction simply means that the columns of are in the null space of , denoted . Hence in practice this restriction can be handled as follows. For arbitrary , project on to , i.e. where is the projection from to . Thus, the loss function can be written as
and it is optimized over . Note that since we represent a subspace by its orthonormal basis, when , we can use the isomorphism to further reduce the computational burden. This will be particularly useful when as in Section 4.4. Under this isomorphism , the corresponding subspace of is where is an matrix such that is an orthogonal matrix. Hence the loss function can alternatively be expressed as
Remark 1
The reduction of the space of all possible projections from to is a consequence of the choice of the loss function . With a different loss function, one might have a different space of possible projections.
4.2 Supervised Dimensionality Reduction
If in addition to , we are given the associated labels , then we would like to use this extra information to sharpen the result of dimensionality reduction. Specifically, we expect that after reducing the dimension, points from the same class preserve their proximity while points from different classes are well separated. We use an affinity function to encode the structure of the data as suggested by Harandi et al. (2018, Sec 3.1, Eq. (14)-(16)). For completeness, we repeat the definition of the affinity function here. The affinity function is defined as where
The set consists of nearest neighbors of that have the same labels as , and the set consists of nearest neighbors of that have different labels from . The nearest neighbors can be computed using the geodesic distance.
The desired projection map that we seek is obtained by the minimizing the following loss function
where is a distance metric on . Note that if the distance metric has -symmetry, e.g. the geodesic distance, so does . In this case the optimization can be done on . Otherwise it is on . This supervised dimensionality reduction is termed as, supervised nested Grassmann (sNG).
4.3 Choice of the distance function
The loss functions and depend on the choice of the distance . Besides the geodesic distance, there are many widely used distances on the Grassmann manifold, see, for example, Edelman et al. (1998, p. 337) and Ye and Lim (2016, Table 2). In this work, we use two different distance metrics: (1) the geodesic distance and (2) the projection distance, which is also called the chordal distance in Ye and Lim (2016) and the projection -norm in Edelman et al. (1998). The geodesic distance was defined in Section 3.1 and the projection distance is defined as follows. For , denote the projection matrices onto and by and respectively. Then, the distance between and is given by where are the principal angles of and . If , then . It is also easy to see the the projection distance has -symmetry. We choose the projection distance mainly for its computational efficiency as it involves only matrix multiplication which has a time complexity whereas the geodesic distance requires an SVD which has a time complexity of .
4.4 Analysis of Principal Nested Grassmannians
To determine the dimension of the nested submanifold that fits the data well enough, we can choose and estimate the projection onto these nested Grassmann manifolds. The ratio of expressed variance for each projection is the ratio of the variance of the projected data and the variance of the original data. With these ratios, we can choose the desired dimension according to the pre-specified percentage of expressed variance as one would do for choosing the number of principal components in PCA.
Alternatively, one can have a full analysis of principal nested Grassmanns (PNG) as follows. Starting from , one can reduce the dimension down to . Using the diffeomorphism between and , we have , and hence we can continue reducing the dimension down to . The resulting sequence will be
Furthermore, we can reduce the points on , which is a 1-dimensional manifold, to a 0-dimensional manifold, which is simply a point, by computing the Fréchet mean (FM). We call this FM the nested Grassmannian mean (NGM) of . The NGM is unique since can be identified as the half circle in and the FM is unique in this case. Note that in general, the NGM will not be the same as the FM of since the embedding/projection need not be isometric. The supervised PNG (sPNG) can be obtained similarly by replacing each projection with it supervised counterpart.
4.5 Principal Scores
Whenever we apply a projection to the data, we might lose some information contained in the data. More specifically, since we project data on a -dimensional manifold to a -dimensional manifold, we need to describe this dimensional information loss during the projection. In PCA, this is done by computing the scores of each principal component, which are the transformed coordinates of each sample in the eigenspace of the covariance matrix. We can generalize the notion of principal scores to the nested Grassmanns as follows: For each , denote by , the fiber of , i.e. , which is a -dimensional submanifold of . An illustration of this fiber is given in Figure 3(a). Let and let the unit tangent vector be the geodesic direction from to . Given a suitable basis on , can be realized as a -dimensional vector, and this will be the score vector of associated with the projection .
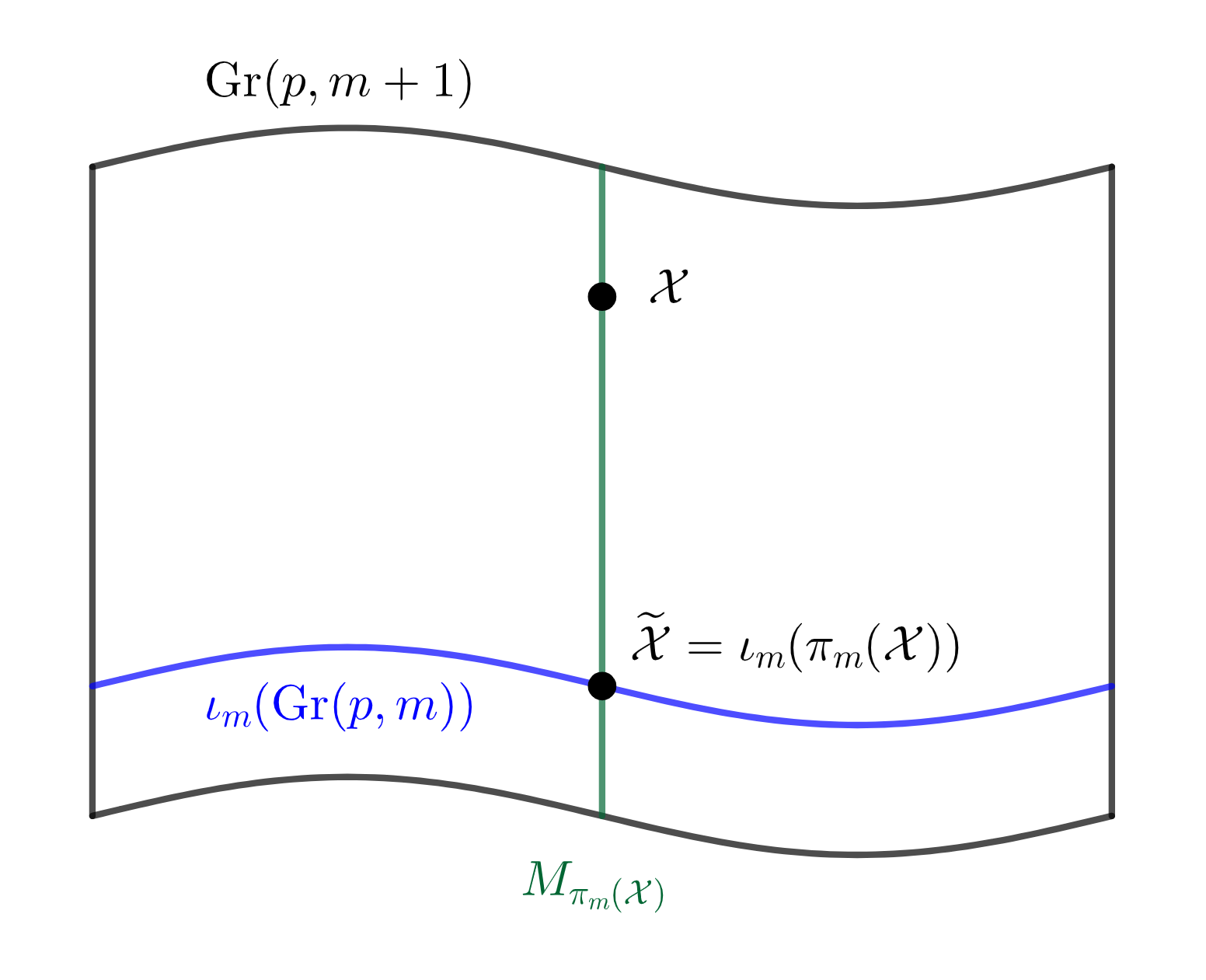
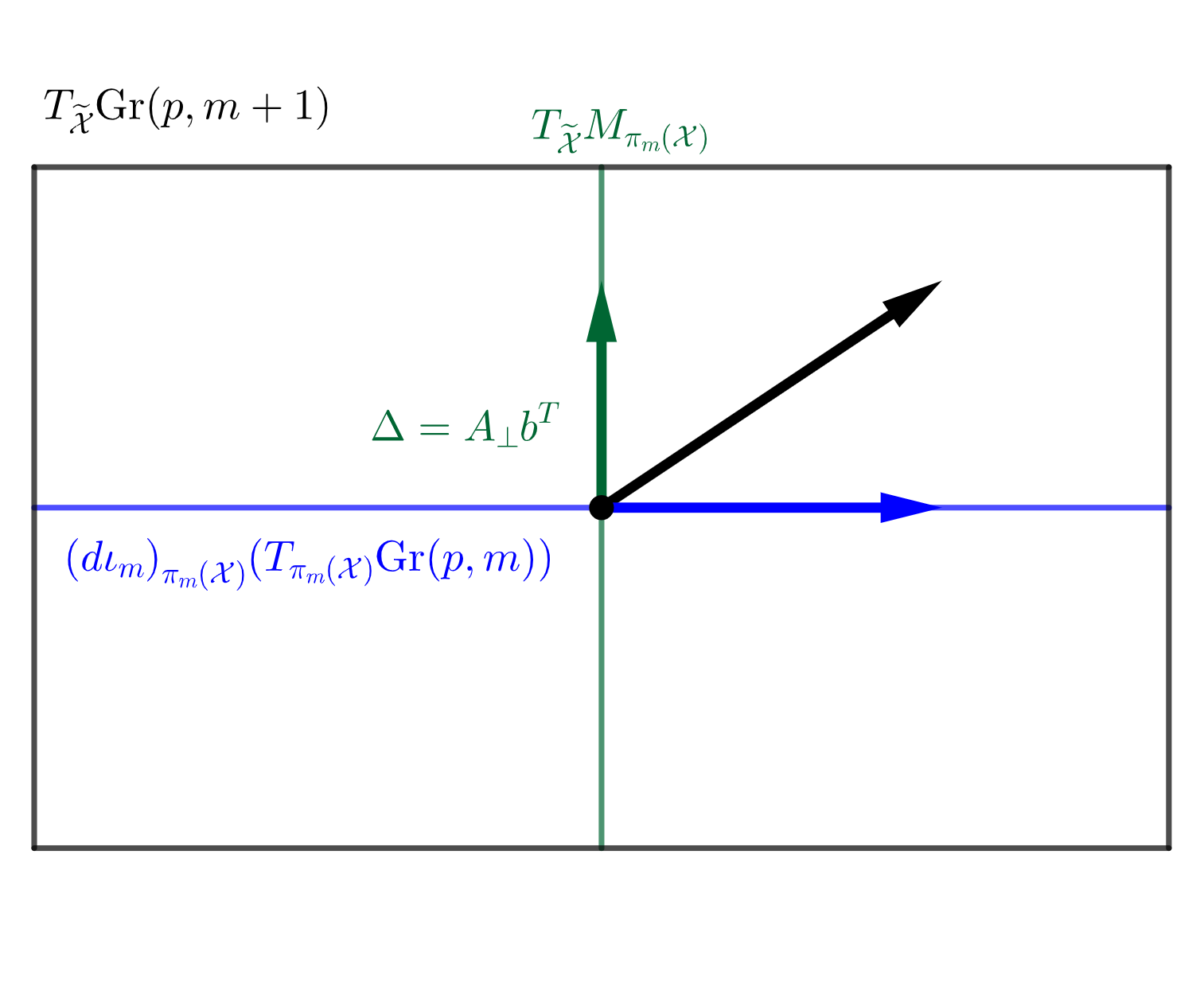
By the definition of , we have the following decomposition of the tangent space of at into the horizontal space and the vertical space induced by ,
An illustration of this decomposition is given in Figure 3(b). A tangent vector of at is of the form where is any -dim vector such that is orthogonal and . It is easy to check that . Hence a natural coordinate for the tangent vector is , and the geodesic direction from to would be . It is easy to see that since has orthonormal columns. To reflect the distance between and , i.e. the reconstruction error, we define as the score vector for associated with . In the case of , we use the sign distance to the NGM as the score. For complex nested Grassmanns however, the principal score associated with each projection is a -dimensional complex vector. For the sake of visualization, we transform this -dimensional complex vector to a -dimensional real vector. The procedure for computing the PNG and the principal scores is summarized in Algorithm 1.
Remark 2
Note that this definition of principal score is not intrinsic as it depends on the choice of basis. Indeed, it is impossible to choose a -dimensional vector for the projection in an intrinsic way, since the only property of a map that is independent of bases is the rank of the map. A reasonable choice of basis is made by viewing the Grassmann as a quotient manifold of , which is a submanifold in . This is how we define the principal score for nested Grassmanns.
5 Experiments
In this section, we will demonstrate the performance of the proposed dimensionality reduction technique, i.e. PNG and sPNG, via experiments on synthetic and real data. The implementation111Our code is available at https://github.com/cvgmi/NestedGrassmann. is based on the python library pymanopt (Townsend et al., 2016) and we use the steepest descent algorithm for the optimization (with default parameters in pymanopt). The optimization was performed on a desktop with 3.6GHz Intel i7 processors and took about 30 seconds to converge.
5.1 Synthetic Data
In this subsection, we compare the performance of the projection and the geodesic distances respectively. The questions we will answer are the following. (1) From Section 4.3, we see that using projection distance is more efficient than using the geodesic distance. But how do they perform compared to each other under varying dimension and variance level ? (2) Is our method of dimensionality reduction ”better” than PGA? Under what conditions does our method outperform PGA?
5.1.1 Projection and Geodesic Distance Comparisons
The procedure we used to generate random points on for the synthetic data experiments is as follows: First, we generate points from a uniform distribution on (Chikuse, 2003, Ch. 2.5), generate from the uniform distribution on , and generate as an matrix with i.i.d entries from . Then we compute . Finally, we compute , where and , to include some perturbation.
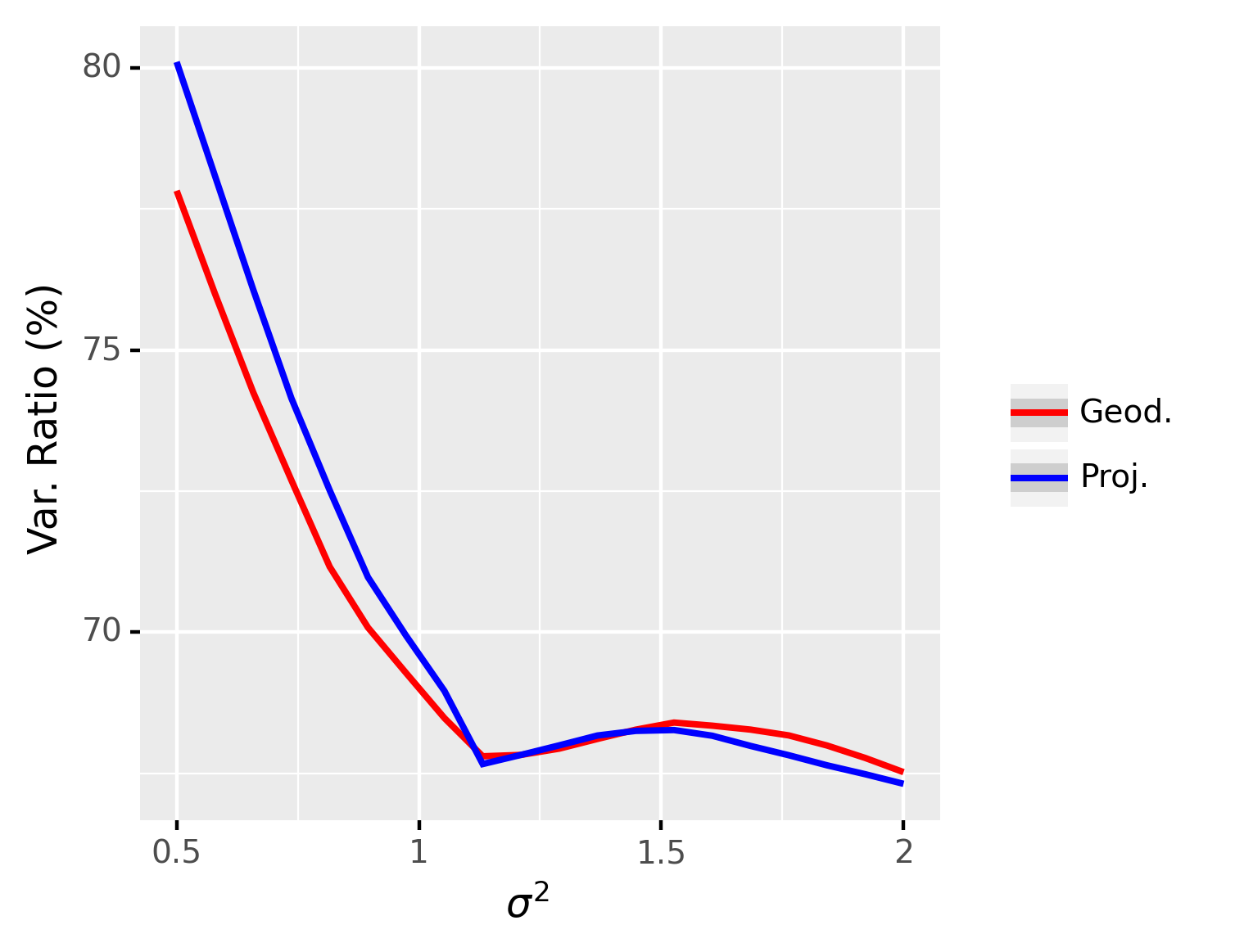
This experiment involves comparing the performance of the NG representation in terms of the explained variance, under different levels of data variance. In this experiment, we set , , , and and is ranging from 0.5 to 1. The results are averaged over repetitions and are shown in Figure 4. From these results, we can see that the explained variance for the projection distance and the geodesic distance are indistinguishable but using projection distance leads to much faster convergence than when using the geodesic distance. The reason is that when two points on the Grassmann manifold are close, the geodesic distance can be well-approximated by the projection distance. When the algorithm converges, the original point and the reconstructed point should be close and the geodesic distance can thus be well-approximated by the projection distance. Therefore, for all the experiments in the next section, we use the projection distance for the sake of efficiency.
5.1.2 Comparison of PNG and PGA
Now we compare the proposed PNG to PGA. In order to have a fair comparison between PNG and PGA, we define the principal components of PNG as the principal components of the scores obtained as in Section 4.5. Similar to the previous experiment, we set , , , , and and apply the same procedure to generate synthetic data. The results are averaged over repetitions and are shown in Figure 5.
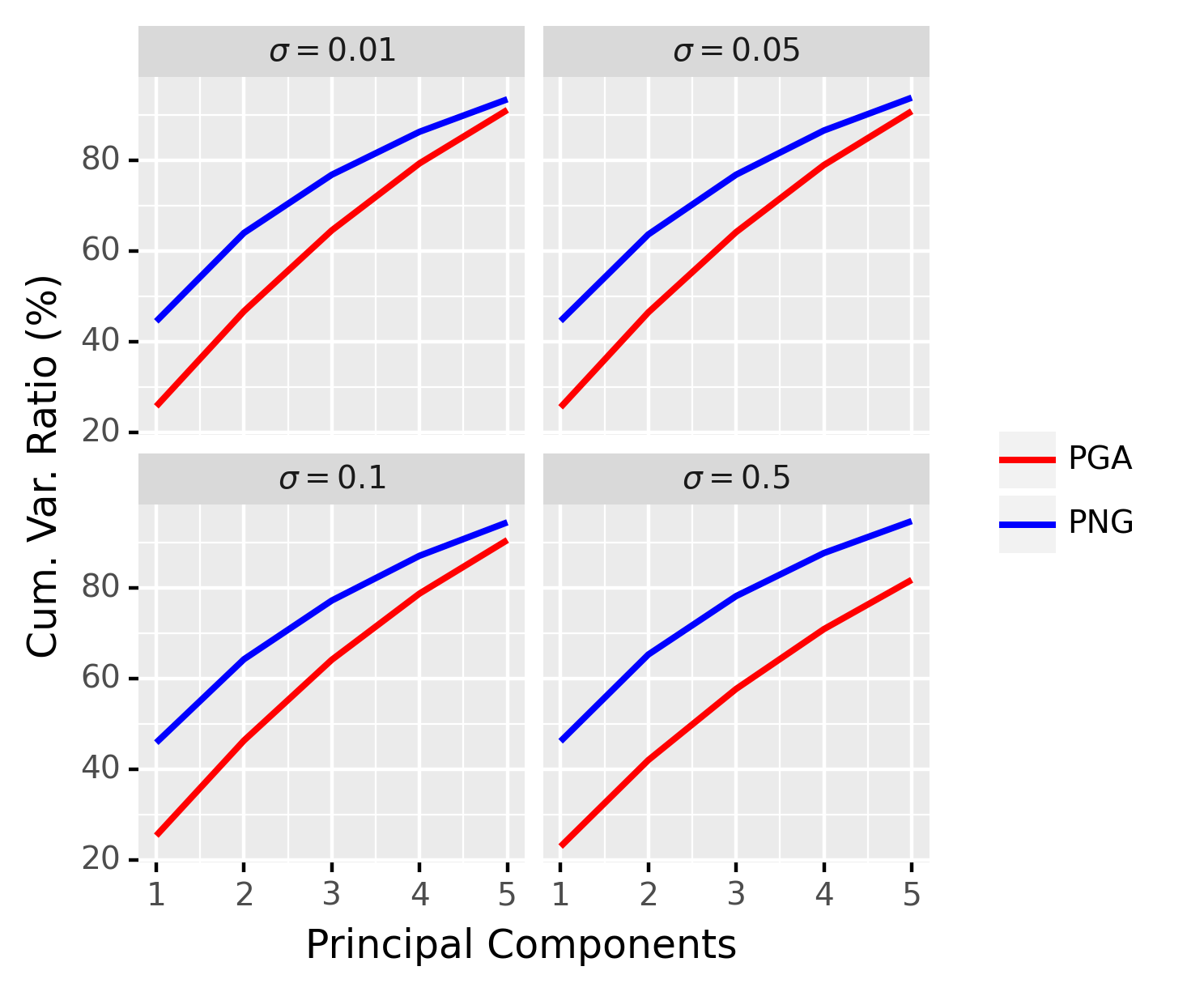
From Figure 5, we can see that our method outperforms PGA by virtue of the fact that it is able to capture a larger amount of variance contained in the data. We can see that when the variance is small, the improvement of PNG over PGA is less significant, whereas, our method is significantly better for the large data variance case (e.g. comparing and ). Note that when the variance in the data is small, i.e. the data are tightly clustered around the FM, and PGA captures the essence of the data well. However, the requirement in PGA on the geodesic submanifold to pass through the anchor point, namely the FM, is not meaningful for data with large variance as explained through the following simple example. Consider, a few data points spread out on the equator of a sphere. The FM in this case is likely to be the north pole of the sphere if we restrict ourselves to the upper hemisphere. Thus, the geodesic submanifold computed by PGA will pass through this FM. However, what is more meaningful is a submanifold corresponding to the equator, which is what a nested spheres representation (Jung et al., 2012) in this case yields. In similar vein, for data with large variance on a Grassmann manifold, our NG representation will yield a more meaningful representation than PGA.
5.2 Application to Planar Shape Analysis
We now apply our method to planar (2-dimensional) shape analysis. A planar shape can be represented as an ordered set of points in , called a -ad or a configuration. Here we assume that these points are not all identical. Denote the configuration by which is a matrix. Let be the Helmert submatrix (Dryden and Mardia, 2016, Ch. 2.5). Then is called the pre-shape of from which the information about translation and scaling is removed. The space of all pre-shapes is called the pre-shape space, denoted by . By definition, the pre-shape space is a -dimensional sphere. The shape is obtained by removing the rotation from the pre-shape, and thus the shape space is . It was shown by Kendall (1984) that is a smooth manifold and, when equipped with the quotient metric, is isometric to the complex projective space equipped with the Fubini-Study metric (up to a scale factor) which is a special case of the complex Grassmannians, i.e. . Hence, we can apply the proposed PNG to planar shapes. For planar shapes, we also compare with the recently proposed principal nested shape spaces (PNSS) (Dryden et al., 2019), which is an application of PNS on the pre-shape space. We will now demonstrate how the PNG performs compared to PGA and PNSS using some simple examples of planar shapes and the OASIS dataset.
Examples of Planar Shapes
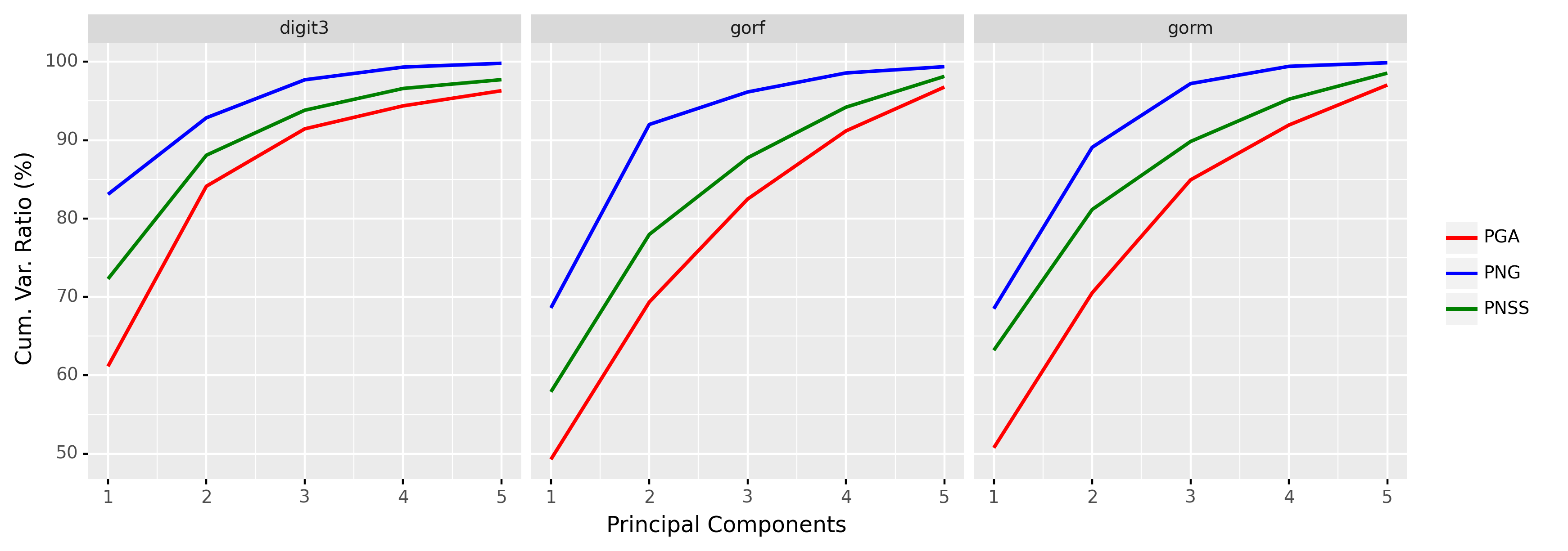
We take three datasets: digit3, gorf, and gorm, from the R package shapes (Dryden, 2021). The digit3 dataset consists of 30 shapes of the digit 3, each of which is represented by 13 points in ; the gorf dataset consists of 30 shapes of female gorilla skull, each of which is represented by 8 points in ; the gorm dataset consists of 29 shapes of male gorilla skull, each of which is represented by 8 points in . Example shapes from these three datasets are shown in Figure 6. The cumulative ratios of variance explained by the first 5 principal components222Here the principal components in PNG and PGA are complex whereas the principal components in PNSS are real. Hence, we choose 5 principal components in PNG and PGA and 10 principal components in PNSS, so that the reduced (real) dimension is 10 in all three cases. of PNG, PGA, and PNSS are shown in Figure 7. It can be seen from Figure 7 that the proposed PNG achieves higher explained variance than PGA and PNSS respectively in most cases.

OASIS Corpus Callosum Data Experiment
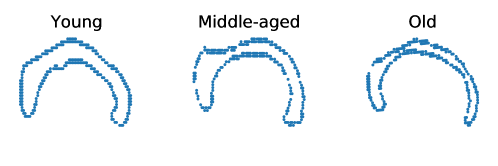
The OASIS database (Marcus et al., 2007) is a publicly available database that contains T1-MR brain scans of subjects of age ranging from 18 to 96. In particular, it includes subjects that are clinically diagnosed with mild to moderate Alzheimer’s disease. We further classify them into three groups: young (aged between 10 and 40), middle-aged (aged between 40 and 70), and old (aged above 70). For demonstration, we randomly choose 4 brain scans within each decade, totalling 36 brain scans. From each scan, the Corpus Callosum (CC) region is segmented and 250 points are taken on the boundary of the CC region. See Figure 8 for samples of the segmented corpus callosi. In this case, the shape space is . Results of application of the three methods to this data are shown in Figure 9.
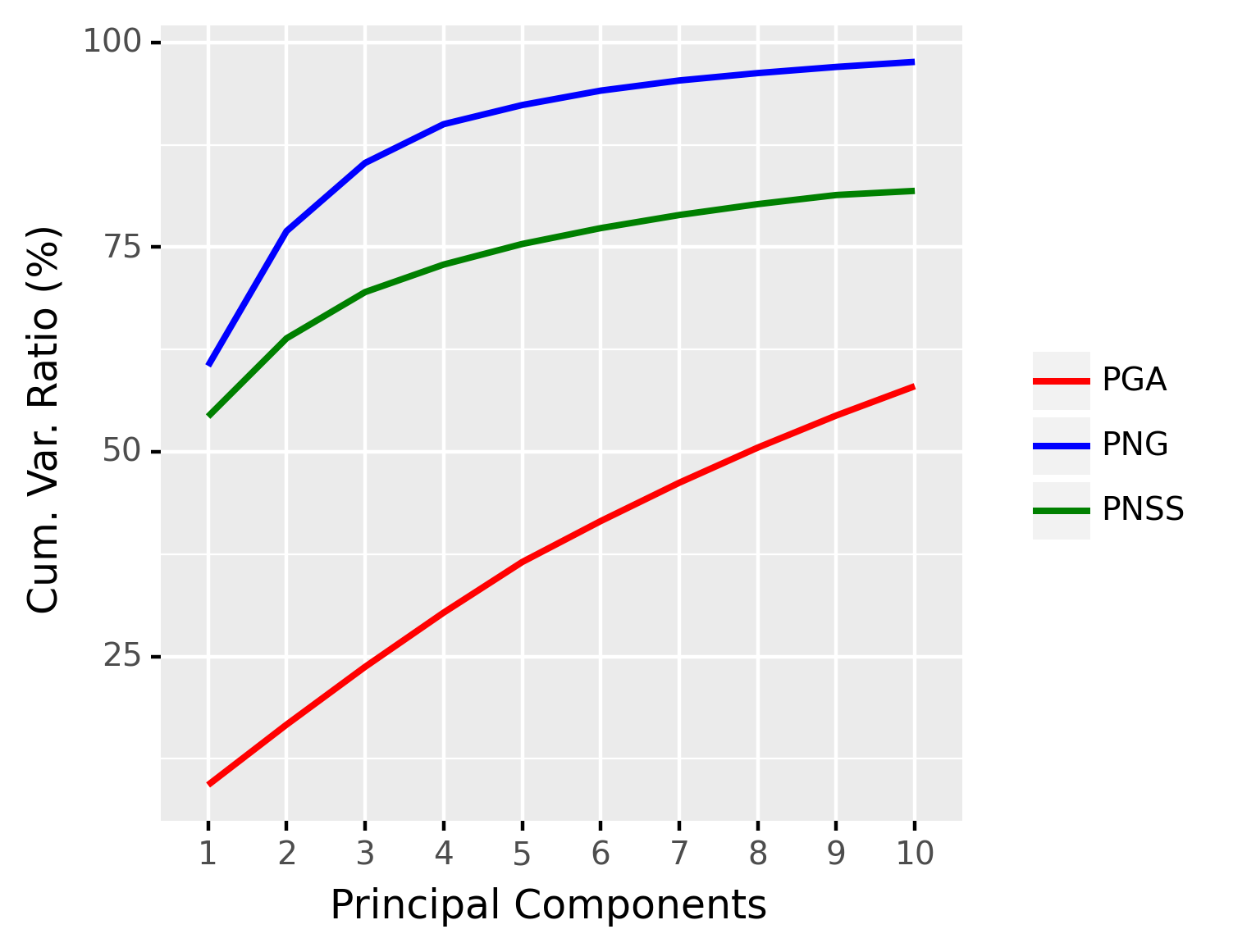
Since the data are divided into three groups (young, middle-aged, and old), we can apply the sPNG described in Section 4.2 to reduce the dimension. The purpose of this experiment is not to demonstrate state-of-the-art classification accuracy for this dataset. Instead, our goal here is to demonstrate that the proposed nested Grassmann representation in a supervised setting is much more discriminative than the competition, namely the supervised PGA. Hence, we choose a simple classifier such as the support vector machine (SVM) Vapnik (1995) to highlight the aforementioned discriminative power of the nested Grassmann over PGA.
For comparison, the PGA can be easily extended to supervised PGA (sPGA) by first diffeomorphically mapping all the data to the tangent space anchored at the FM and then performing supervised PCA Bair et al. (2006); Barshan et al. (2011) on the tangent space. However, generalizing PNSS to the supervised case is nontrivial and is beyond the scope of this paper. Therefore, we limit our comparison to the unsupervised PNSS. In this demonstration, we apply an SVM on the scores obtained from different dimension reduction algorithms, and we choose only the first three principal scores to show that even with the 3-dimensional representation of the original shapes, we can still achieve good classification results. The results are shown in Table 1. These results are in accordance with our expectation since in sPNG, we seek a projection that minimizes the within-group variance while maximizing the between-group variance. However, as we observed earlier, the constraint of requiring the geodesic submanifold to pass through the FM is not well suited for this dataset which has a large variance across the data. This accounts for why the sPNG exhibits far superior performance compared to sPGA in accuracy.
| Method | Accuracy |
|---|---|
| sPNG | 83.33% |
| PNG | 75% |
| sPGA | 66.67% |
| PGA | 63.89% |
| PNSS | 80.56% |
6 Conclusion
In this work, we proposed a novel nested geometric structure for homogeneous spaces and used this structure to achieve dimensionality reduction for data residing in Grassmann manifolds. We also discuss how this nested geometric structure served as a natural generalization of other existing nested geometric structures in literature namely, spheres and the manifold of SPD matrices. Specifically, we showed that a lower dimensional Grassmann manifold can be embedded into a higher dimensional Grassmann manifold and via this embedding we constructed a sequence of nested Grassmann manifolds. Compared to the PGA, which is designed for general Riemannian manifolds, the proposed method can capture a higher percentage of data variance after reducing the dimensionality. This is primarily because our method, unlike the PGA, does not require the submanifold to be a geodesic submanifold and to pass through the Fréchet mean of the data. Succinctly, the nested Grassmann structure allows us to fit the data to a larger class of submanifolds than PGA. We also proposed a supervised dimensionality reduction technique which simultaneously differentiates data classes while reducing dimensionality. Efficacy of our method was demonstrated on the OASIS Corpus Callosi data for dimensionality reduction and classification. We showed that our method outperforms the widely used PGA and the recently proposed PNSS by a large margin.
Acknowledgments
This research was in part funded by the NSF grant IIS-1724174, the NIH NINDS and NIA via R01NS121099 to Vemuri and the MOST grant 110-2118-M-002-005-MY3 to Yang.
Ethical Standards
The work follows appropriate ethical standards in conducting research and writing the manuscript, following all applicable laws and regulations regarding treatment of animals or human subjects.
Conflicts of Interest
We declare we don’t have conflicts of interest.
References
- Absil et al. (2004) P-A Absil, Robert Mahony, and Rodolphe Sepulchre. Riemannian geometry of Grassmann manifolds with a view on algorithmic computation. Acta Applicandae Mathematica, 80(2):199–220, 2004.
- Bair et al. (2006) Eric Bair, Trevor Hastie, Debashis Paul, and Robert Tibshirani. Prediction by supervised principal components. Journal of the American Statistical Association, 101(473):119–137, 2006.
- Banerjee et al. (2017) Monami Banerjee, Rudrasis Chakraborty, and Baba C Vemuri. Sparse exact PGA on Riemannian manifolds. In Proceedings of the IEEE International Conference on Computer Vision, pages 5010–5018, 2017.
- Barshan et al. (2011) Elnaz Barshan, Ali Ghodsi, Zohreh Azimifar, and Mansoor Zolghadri Jahromi. Supervised principal component analysis: Visualization, classification and regression on subspaces and submanifolds. Pattern Recognition, 44(7):1357–1371, 2011.
- Basser et al. (1994) Peter J Basser, James Mattiello, and Denis LeBihan. MR diffusion tensor spectroscopy and imaging. Biophysical journal, 66(1):259–267, 1994.
- Callaghan (1993) Paul T Callaghan. Principles of Nuclear Magnetic Resonance Microscopy. Oxford University Press on Demand, 1993.
- Chakraborty et al. (2016) Rudrasis Chakraborty, Dohyung Seo, and Baba C Vemuri. An efficient exact-PGA algorithm for constant curvature manifolds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3976–3984, 2016.
- Cheeger and Ebin (1975) Jeff Cheeger and David Gregory Ebin. Comparison theorems in Riemannian geometry, volume 9. North-holland Amsterdam, 1975.
- Chikuse (2003) Yasuko Chikuse. Statistics on Special Manifolds, volume 174. Springer Science & Business Media, 2003.
- Damon and Marron (2014) James Damon and JS Marron. Backwards principal component analysis and principal nested relations. Journal of Mathematical Imaging and Vision, 50(1-2):107–114, 2014.
- Dryden (2021) I. L. Dryden. shapes package. R Foundation for Statistical Computing, Vienna, Austria, 2021. URL http://www.R-project.org. Contributed package, Version 1.2.6.
- Dryden and Mardia (2016) Ian L Dryden and Kanti V Mardia. Statistical shape analysis: with applications in R, volume 995. John Wiley & Sons, 2016.
- Dryden et al. (2019) Ian L Dryden, Kwang-Rae Kim, Charles A Laughton, Huiling Le, et al. Principal nested shape space analysis of molecular dynamics data. Annals of Applied Statistics, 13(4):2213–2234, 2019.
- Edelman et al. (1998) Alan Edelman, Tomás A Arias, and Steven T Smith. The geometry of algorithms with orthogonality constraints. SIAM Journal on Matrix Analysis and Applications, 20(2):303–353, 1998.
- Feragen et al. (2014) Aasa Feragen, Mads Nielsen, Eva Bjørn Vedel Jensen, Andrew du Plessis, and François Lauze. Geometry and statistics: Manifolds and stratified spaces. Journal of Mathematical Imaging and Vision, 50(1):1–4, 2014.
- Fletcher et al. (2004) P Thomas Fletcher, Conglin Lu, Stephen M Pizer, and Sarang Joshi. Principal geodesic analysis for the study of nonlinear statistics of shape. IEEE Transactions on Medical Imaging, 23(8):995–1005, 2004.
- Goresky and MacPherson (1988) Mark Goresky and Robert MacPherson. Stratified Morse Theory. Springer, 1988.
- Harandi et al. (2018) Mehrtash Harandi, Mathieu Salzmann, and Richard Hartley. Dimensionality reduction on SPD manifolds: The emergence of geometry-aware methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(1):48–62, 2018.
- Hastie and Stuetzle (1989) Trevor Hastie and Werner Stuetzle. Principal curves. Journal of the American Statistical Association, 84(406):502–516, 1989.
- Hauberg (2016) Søren Hauberg. Principal curves on Riemannian manifolds. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(9):1915–1921, 2016.
- Helgason (1979) Sigurdur Helgason. Differential geometry, Lie groups, and symmetric spaces. Academic press, 1979.
- Huckemann et al. (2010) Stephan Huckemann, Thomas Hotz, and Axel Munk. Intrinsic shape analysis: Geodesic PCA for Riemannian manifolds modulo isometric Lie group actions. Statistica Sinica, pages 1–58, 2010.
- Jaquier and Rozo (2020) Noémie Jaquier and Leonel Rozo. High-dimensional bayesian optimization via nested riemannian manifolds. Advances in Neural Information Processing Systems, 33:20939–20951, 2020.
- Jung et al. (2012) Sungkyu Jung, Ian L Dryden, and JS Marron. Analysis of principal nested spheres. Biometrika, 99(3):551–568, 2012.
- Kendall (1984) David G Kendall. Shape manifolds, Procrustean metrics, and complex projective spaces. Bulletin of the London Mathematical Society, 16(2):81–121, 1984.
- Marcus et al. (2007) Daniel S Marcus, Tracy H Wang, Jamie Parker, John G Csernansky, John C Morris, and Randy L Buckner. Open Access Series of Imaging Studies (OASIS): cross-sectional MRI data in young, middle aged, nondemented, and demented older adults. Journal of Cognitive Neuroscience, 19(9):1498–1507, 2007.
- Pennec et al. (2018) Xavier Pennec et al. Barycentric subspace analysis on manifolds. The Annals of Statistics, 46(6A):2711–2746, 2018.
- Sommer et al. (2010) Stefan Sommer, François Lauze, Søren Hauberg, and Mads Nielsen. Manifold valued statistics, exact principal geodesic analysis and the effect of linear approximations. In European Conference on Computer Vision, pages 43–56. Springer, 2010.
- Townsend et al. (2016) James Townsend, Niklas Koep, and Sebastian Weichwald. Pymanopt: A python toolbox for optimization on manifolds using automatic differentiation. Journal of Machine Learning Research, 17(137):1–5, 2016. URL http://jmlr.org/papers/v17/16-177.html.
- Vapnik (1995) Vladimir Vapnik. The Nature of Statistical Learning Theory. Springer Science & Business Media, 1995.
- Ye and Lim (2016) Ke Ye and Lek-Heng Lim. Schubert varieties and distances between subspaces of different dimensions. SIAM Journal on Matrix Analysis and Applications, 37(3):1176–1197, 2016.
- Zhang and Fletcher (2013) Miaomiao Zhang and Tom Fletcher. Probabilistic principal geodesic analysis. In Advances in Neural Information Processing Systems, pages 1178–1186, 2013.