1 Introduction
Obtaining quantitative measurements of brain grey matter microstructure with a dedicated soma representation is a growing field of interest in the diffusion MRI (dMRI) community (Palombo et al., 2020; Jelescu et al., 2021). Unlike histology, dMRI permits to quantify brain tissue characteristics non-invasively and could, for example, help understanding dementia and cognitive deficits (Douaud et al., 2013). However, current methods require demanding acquisitions with several -shells (equivalently -shells) and rely on non-linear models for which several parameter values may yield the same observation, also known as parameter indeterminacy (Jelescu et al., 2016; Novikov et al., 2018b). This leads to numerically unstable solutions which are hard to interpret. Another major challenge is the fact that quantifying brain tissue microstructure directly from the dMRI signal is an inherently difficult task, because of the large dimensionality of the collected data and its stochastic nature (Fick et al., 2016).
Many works have tackled the non-linear inverse problem of inferring brain tissue parameters from dMRI signal. A popular solution is NODDI (Zhang et al., 2012), which stabilises the solution by imposing constraints on model parameters that are not biologically plausible (Novikov et al., 2018b). This has the effect of biasing the parameter estimation and the inverse problem remains largely degenerate (Jelescu et al., 2016). There has also been some interest in applying methods from the machine learning literature to solve the inverse problem. This is the case of the SANDI model (Palombo et al., 2020), in which the authors employ random forest regressors. Although the method provides rather acceptable accuracy in real-case scenarios, it can only output one set of tissue parameters for a given observed dMRI signal, masking, therefore, other biologically plausible solutions that could generate the same observed signal. Furthermore, the parameter estimates are obtained following a deterministic approach, so no description in terms of confidence interval are available. Also, the code for SANDI is not standard in the literature nor available in the internet yet.
To overcome such limitations, we present three contributions. First, we use a three-compartment model for brain tissue composed of neurites, somas, and extra-cellular space, and introduce a new parameter that jointly encodes soma radius and intracellular diffusivity without imposing constraints on these values. This new parameter reduces indeterminacies in the model and has relevant physiological interpretations. Second, we present a method to fit the model through summary features of the dMRI signal based on a large and small -value analysis using boundary approximations. These rotationally-invariant features relate directly to the tissue parameters and enable us to invert the model without manipulating the raw dMRI signals. Such summary statistics ensure a stable solution of the parameter estimations, as opposed to the indeterminate models used in Zhang et al. (2012); Palombo et al. (2020). Third, we employ modern tools from Bayesian analysis known as likelihood-free inference (LFI, (Cranmer et al., 2020)) to solve our non-linear inverse problem under a probabilistic framework and determine the posterior distribution of the fitted parameters. Such approach offers a full description of the solution landscape and can point out degeneracies, as opposed to the usual deterministic least-squares based solution (Jelescu et al., 2016; Novikov et al., 2018b).
2 Related Works
Current brain tissue models are predominantly based on the two compartment Standard Model (SM) (Zhang et al., 2012; Novikov et al., 2018a). Recent evidence shows that the SM, mainly used in white matter, does not hold for grey matter microstructure analysis (Veraart et al., 2020). Several assumptions aim at explaining this issue such as increased permeability in neurite membranes (Veraart et al., 2020), or curvy projections along with longer pulse duration (Novikov et al., 2018a). We follow the hypothesis that the SM doesn’t hold due to an abundance of cell bodies in grey matter (Palombo et al., 2020). Our proposed biophysical model is then based on three compartments (Palombo et al., 2020): neurites, somas, and extra-cellular space (ECS). Despite its increased complexity, the main advantage of such model is the possibility to jointly estimate the characteristic features of each compartment.
Inferring parameters of the brain tissue model directly from dMRI signals has proven to be a very challenging task and has motivated the development of new approaches to reduce the dimensionality of the data to be processed. For instance, Novikov et al. (2018b) proposes the LEMONADE system of equations, based on a Taylor expansion of the diffusion signal and a set of rotationally invariant moments. In this work, we extend the LEMONADE equations to a setting with a three compartment model and further develop the method so to extract more features from the observed signal. We call the resulting vector of features defined by these quantities the ‘summary statistics’ of the dMRI signal.
The usual way of applying a Bayesian approach to solve non-linear inverse problems (Stuart, 2010) is to define two quantities: a prior distribution encoding initial knowledge of the parameter values (e.g. intervals which are physiologically relevant) and the likelihood function of the forward model being studied. One can then either obtain an analytic expression of the posterior distribution via Bayes’ formula or use a Markov-Chain Monte Carlo (MCMC) procedure to numerically sample the posterior distribution (Gelman et al., 2013). However, the likelihood function of complex models such as the one that we consider here is often very hard to obtain and makes the Bayesian approach rather challenging to use. Likelihood-free inference (LFI) bypasses this bottleneck by recurring to several simulations of the forward model using different parameters and learning an approximation to the posterior distribution from these examples (Cranmer et al., 2020).
The first contributions on LFI are also known as approximate Bayesian computation (ABC) and have been applied to invert models from ecology, population genetics, and epidemiology (Sisson, 2018). Some of the limitations of these techniques include the large number of simulations required for the posterior estimations and the need of defining a distance function to compare the results of two simulations. Recently, there has been a growing interest in the machine learning community in improving the limitations of ABC methods through deep generative modeling, i.e. neural network architectures specially tailored to approximate probability density functions from a set of examples (Goodfellow et al., 2016). Normalizing flows (Papamakarios et al., 2019) are a particular class of such neural networks that have demonstrated promising results for likelihood-free inference in different research fields (Cranmer et al., 2020; Gonçalves et al., 2020; Greenberg et al., 2019).
3 Theory
In this section, we present the theoretical background underlying our three main contributions. Section 3.1 describes the three-compartment model for brain grey matter. We also introduce a new parameter that captures both soma radius and intracellular diffusivity and avoids the usual indeterminacy in estimating them separately. Section 3.2 presents the summary statistics used to reduce the dimensionality of the dMRI signal into a 7-dimensional feature vector that can be used to determine the physiological parameters of interest. Section 3.3 describes the Bayesian approach used to solve our non-linear inverse problem and obtain a posterior distribution for the physiological parameters that best describe a given dMRI signal.
3.1 Modeling the Brain grey Matter with a 3-compartment Model
To characterize cortical cytoarchitecture, we propose a method that relates the diffusion MRI signal to specific tissue parameters. To that aim, we first define a forward model based on a biophysical modeling of brain grey matter.
Research in histology has demonstrated that grey matter is composed of neurons embedded in a fluid environment. Each neuron is composed of a soma, corresponding to the cellular body, surrounded by neurites connecting neurons together. Following this tissue biophysical composition, we model the grey matter tissue as three-compartmental (Palombo et al., 2020), moving away from the usual standard model (SM) designed for white matter. We further assume that our acquisition protocol is insensitive to exchanges between the compartments, i.e. molecules moving from one compartment to another have a negligible influence on the signal (Palombo et al., 2020). Many works include also a dot compartment into the SM with zero apparent diffusivity and no exchange. However, we have not considered such assumption, because its presence has been considered very unlikely in grey matter by previous works (Veraart et al., 2019; Tax et al., 2020). The observed diffusion signal is considered as a convex mixture of signals arising from somas, neurites, and extra-cellular space (ECS). Unlike white matter-centric methods (Jelescu and Budde, 2017), we are not interested in the fiber orientation and only estimate orientation-independent parameters. This enables us to work on the direction-averaged dMRI signal, denoted , known as the powder averaged signal. This consideration mainly matters for neurites, as their signal is not isotropic, as opposed to the proposed model for somas and ECS. Our direction-averaged grey matter signal model is then:
| (1) |
In this equation, , , and represent signal fractions for neurites, somas, and ECS respectively (). Note that the relative signal fractions do not correspond to the relative volume fractions of the tissue compartments as they are also modulated by different T2 values (Novikov et al., 2018a). corresponds to axial diffusivity inside neurites, while and correspond to somas and extra-cellular diffusivities. is the average soma radius within a voxel. This model is the same as the model SANDI proposed by Palombo et al. (2020), with , and . We use -values for more readability and harmonization throughout the paper, but a direct conversion to -values is also possible, using with .
We now review the model for each compartment, to make explicit the impact of each parameter on the diffusion MRI signal. Note that the use of such a model supposes each voxel contains a single type of neuron.
3.1.1 Neurite compartment.
Neurites, as in the SM, are modeled as 0-radius impermeable cylinders (“sticks”), with effective diffusion along the parallel axis, and a negligible radial intra-neurite diffusivity. In our acquisition setting, this model has been shown to hold (Veraart et al., 2020). Its direction averaged signal is (Veraart et al., 2020):
| (2) |
3.1.2 Soma compartment.
Somas are modeled as spheres, whose signal can be computed using the Gaussian phase distribution approximation (Balinov et al., 1993):
| (3) |
We exploit this relation here to extract a parameter which, at fixed diffusivity , is modulated by the radius of the soma :
where is the th root of , with the Bessel functions of the first kind. In certain specific cases, has a simpler and more interpretable expression. For instance, when we consider a narrow pulse regime, with small or large , loses its dependence on (Balinov et al., 1993) and we obtain:
| (4) |
In the Neuman (wide pulse) regime, i.e. when and , becomes only dependent on the soma radius (Murday and Cotts, 1968):
| (5) |
These two approximations permits us to better interpret the parameter .
3.1.3 Extra-cellular space compartment.
We approximate the extra-cellular space with isotropic Gaussian diffusion, i.e. a mono-exponential diffusion signal with a scalar diffusion constant , which reflects the molecular viscosity of the fluid. This approximation assumes that the ECS is fully connected. The approximation is therefore:
| (6) |
Because of the geometry of the problem, we estimate as equal to one third of the diffusivity in the ventricles (considered as free diffusivity), given the same metabolic composition of the extracellular fluid and ventricles (Vincent et al., 2021).
3.2 An Invertible 3-compartment Model: dMRI Summary Statistics
The tissue model presented in Section 3.1 enables us to relate the dMRI signal with parameters representing grey matter tissue microstructure. However, solving the inverse problem directly from Eq. (1) is a difficult task, leading to indeterminacies and poorly estimated parameters with large variability. Current methods addressing this issue have not studied its stability (Palombo et al., 2020) but simpler models with only two compartments have been shown to be indeterminate (Novikov et al., 2018a).
To produce a method which addresses this indeterminacy, we introduce rotationally invariant summary statistics to describe the dMRI signal. The goal is to reduce the dimensionality of the data at hand and representing all the relevant information for statistical inference with a few features. We then solve the inverse problem efficiently using Bayesian inference as described in Section 3.3. These dMRI-based summary statistics are extracted from our proposed model presented in Section 3.1 via the following analysis of the dMRI signal on the boundaries of large and small -value cases.
3.2.1 Large -value approximation: RTOP.
We compute a -bounded return-to-the-origin probability (RTOP), which measures the restrictions of the diffusing fluid molecule motion and gives us information about the structure of the media (Mitra et al., 1995):
| (7) |
For large enough, the RTOP in our 3-compartment model in Eq. (1) yields a soma and extra-cellular signal which converges towards a constant value in , while the neurites’ contribution becomes quadratic in . In this case, RTOP becomes:
| (8) |
in which the last term of the equation, , is a nuisance parameter that describes a constant noise in the direction averaged signal. By accurately estimating the second derivative of at large enough, we can solve the coefficients of interest of the polynomial in Eq. (8): and . We do this efficiently by casting it as an overdetermined ordinary least squares problem which has a unique solution.
3.2.2 Small -value approximation: Spiked LEMONADE111Please note that the ‘spiked’ adjective used here is simply an allusion to our method being a variation of the LEMONADE method..
We propose a second approximation, based on a moment decomposition for small -values (Novikov et al., 2018b):
| (9) |
where are the directional basis of the tensors , , and the unit direction of the dMRI acquisition. From the moment tensors of this decomposition, LEMONADE (Novikov et al., 2018b) extracts rotational invariant scalar indices These quantify white matter microstructure by plugging the 2-compartment SM into Eq. (9) (see Novikov et al., 2018b, app. C).
In this work, we extended LEMONADE to our 3-compartment model presented in Section 3.1 by plugging Eq. (1) into Eq. (9) and performing tedious arithmetic. This results in the following equation system, which now includes the soma parameter , relating the dMRI signal to grey matter microstructure:
| (10) |
where is a scalar measure of neurite orientation dispersion (Novikov et al., 2018b).
Note that only the shells with are used, to get an unbiased estimation of the rotational invariant moments , , and .
3.2.3 Complete system.
Combining equations (8) and (10) and adding the constraint that the fractions for the three compartments sum to one, we obtain a non-linear system of 7 equations and 7 unknowns. Following Menon et al. (2020), we assume nearly-constant per subject acquisition and estimated it as one third of the mean diffusivity in the subject’s ventricles (Vincent et al., 2021). This assumption allows us to drop an unknown from the system, use as a reference diffusivity and turn our system of equations unitless with and , which gives:
| Spiked LEMONADE | RTOP |
| Small -values | Large -values |
3.3 Inverting the model with Bayesian inference
Our main goal is to determine the values of the parameter vector
that best explain a given observed dMRI signal. Because of the high-dimensionality of this kind of signal and the difficulties in obtaining stable estimates of directly from it, we recur to the set of summary features defined in Section 3.2,
and make the assumption that it carries all the information necessary for determining the having generated a given dMRI signal . We denote the relation between these quantities as
| (11) |
where is a multivariate function that implements the system of equations described in Section 3.2 and is an additive noise capturing the imperfections of our modelling procedure, the limitations of the summary statistics, and the measurement noise.
3.3.1 The Bayesian formalism.
We interpret the inverse problem of inferring the parameters that best describe a given observed summary feature vector as that of determining the posterior distribution of given an observation . By first choosing a prior distribution describing our initial knowledge of the parameter values, we may use Bayes’ theorem to write
| (12) |
where is the likelihood of the observed data point and is a normalizing constant, commonly referred to as the evidence of the data. Note that such a probabilistic approach returns not only which best fits the observed data (i.e. the parameter that maximizes the posterior distribution), but the full posterior distribution . The latter can be possibly multimodal or flat, which would indicate the difficulty of summarizing it with a unique maximum.
3.3.2 Bypassing the likelihood function.
Despite its apparent simplicity, it is usually difficult to use Eq. (12) to determine the posterior distribution, since the likelihood function for data points generated by complex non-linear models is often hard to write. To avoid such difficulty, we directly approximate the posterior distribution using a conditional density estimator, i.e. a family of conditional p.d.f. approximators parametrized by and that takes (the parameter) and (the observation) as input arguments. Our posterior approximation is then obtained by minimizing its average Kullback-Leibler divergence with respect to the conditional density estimator for different choices of , as per (Papamakarios and Murray, 2016)
| (13) |
which can be rewritten as
| (14) |
where is a constant that does not depend on . Note, however, that in practice we actually consider a -sample Monte-Carlo approximation of the loss function given by
| (15) |
where the data points are sampled from the joint distribution with and . We can then use stochastic gradient descent to obtain a set of parameters which minimizes . If the class of conditional density estimators is sufficiently expressive, it is possible to show that the minimizer of Eq. (15) converges to when (Greenberg et al., 2019). Note, also, that the parametrization that we obtain by the end of the optimization procedure yields a posterior which is amortized for different choices of . Thus, for a specific observation we may simply write to get an approximation of .
3.3.3 Neural density estimators.
In this work, our conditional p.d.f. approximators belong to a class of neural networks called normalizing flows (Papamakarios et al., 2019). These flows are invertible functions capable of transforming vectors generated by a simple base distribution (e.g. the standard multivariate Gaussian distribution) into an approximation of the true posterior distribution. An important advantage of normalizing flow versus other p.d.f. approximators such as generative adversarial network (GAN (Goodfellow et al., 2014)) and variational auto-encoders (VAE (Kingma and Welling, 2019)) is that it provides both the likelihood of any sample point of interest and it is also straightforward to sample new data points from it. Furthermore, certain classes of normalizing flows can be shown to be universal approximators of probability density functions. We refer the reader to Papamakarios et al. (2019) for more information on the different types of normalizing flows.
4 Materials and methods
This section presents the technical details on how we have implemented our theoretical contributions and describes the simulated and real datasets used in the numerical illustrations.
4.1 The likelihood-free inference setup
Using a likelihood-free inference approach for inverting the 3-compartment model relating tissue parameters and dMRI summary statistics relies on four important aspects:
- (1)
The forward model. As explained in Section 3.3, we obtain an approximation of the amortized posterior distribution using a dataset containing several paired examples of a parameter and its corresponding summary statistics . In what follows, we adopt the usual assumptions from the inverse problems literature and consider the additive noise from Eq. (11) small enough to be ignored in the data generation, so that we have .
- (2)
Prior distribution. The simplest way of defining a prior distribution in our setting is to use an uniform distribution with limits within physiologically relevant intervals for each parameter. From Section 3.1, we know that the fractions , , and have values between 0 and 1 and all sum up to one. To encode this information in , we define new parameters and and relate them with the fractions by
(16) In this way, whenever we want to generate a prior sample for we first generate a sample of and then transform them according to (16) to get a set of fractions which is uniformly sampled in the region . We follow the usual assumption that the diffusivity of the compartments are inferior or equal to the self-diffusion coefficient of free water, which is (Li et al., 2016). We fix, therefore, the interval for neurite diffusivity () as between and . The newly introduced parameter is parametrized by soma radius and diffusivity. To account for a soma radius comprised between 2 and (Palombo et al., 2021) and a diffusivity range as previously defined, we used the interval [50, 2500] . Parameter , which measures the dispersion of neurites orientation, is comprised in the interval [0,1], with 1 indicating an anisotropic orientation distribution function.
- (3)
Posterior approximator. We use an autoregressive architecture for normalizing flows implemented via the masked autoencoder for distribution estimation (MADE) (Germain et al., 2015). We follow the same setup from Greenberg et al. (2019) for LFI problems, stacking five MADEs, each with two hidden layers of 50 units, and a standard normal base distribution. This choice provides a sufficiently flexible function capable of approximating complex posterior distributions.
- (4)
Training procedure. The parametrization of our normalizing flow is obtained by minimizing the loss function (15) using the ADAM optimizer (Kingma and Ba, 2014) with default parameters, a learning rate of and a batch size of 100. Except for a few validation experiments, we have used simulated data points to approximate the posterior distribution.
4.2 Simulated dMRI data
We first validate our proposed method using simulated dMRI data. For this, we fix a parameter vector based on a plausible biophysical configuration (Palombo et al., 2021) and generate a simulated observation associated to it. Our goal, then, is to check whether the posterior distribution concentrates around the ground truth parameter, i.e. if it is peaked around the true values of the parameters in . If this is the case, we can assert that the LFI procedure is capable of inverting our non-linear model successfully.
The simplest way of generating an observation from the ground truth parameter would be to use the forward model defined in Section 4.1, which yields very good results, since the posterior approximation is trained on data points generated in the same way. We have also considered a more challenging situation, in which the dMRI signals are simulated following a setup that is closer to what we would expect from real experimental experiments. This is based on two steps. Firstly, we use the dmipy simulator (Fick et al., 2019) to simulate the three-compartment model described in Section 3.1 and obtain a dMRI signal . Then, we calculate the summary statistics of this signal as defined in Section 3.2 to reduce the dimensionality of the observation and obtain a feature vector .
We have carried out our simulations on dmipy considering three different kinds of acquisition setup. They all have -shells with 128 uniformly distributed directions, but they differ in their -values and acquisition times:
- –
Setup Ideal corresponds to a rather “confortable” case with 10 -values between 0 and . We use = as in the HCP MGH database.
- –
Setup HCP MGH reproduces the setup from the HCP MGH dataset, with 5 -values: 0, 1, 3, 5, and and = . Since the Spiked LEMONADE approximation (3.2.2) requires at least three -values inferior to , we extrapolated an extra -shell at using MAPL (Fick et al., 2016), a method for modeling multi-shell q-space signals.
- –
Setup HCP 1200 reproduces the setup from the HCP 1200 dataset, with only 4 -values: 0, 1, 2, and and = An extra b-shell at has been interpolated to be used in the RTOP approximation.
Note that in the simulations with all setups we have used the three -shells with the lowest -values for the small -value approximation (Spiked LEMONADE), and the three largest -values for the RTOP approximation.
4.3 HCP MGH dataset
After validating our proposal on different simulated settings, we carried out our analysis on two publicly available databases. Our goal was to estimate the tissue parameters for each voxel in the dMRI acquisitions corresponding to the grey matter and determine how these parameters vary. We segmented the brain grey matter using FreeSurfer before applying our pipeline to the selected voxels. Because of the probabilistic framework that we use, these estimates are accompanied of credible intervals that can be used to inform our degree of confidence of these estimates.
Our first analysis was on the HCP MGH Adult Diffusion database (Setsompop et al., 2013). This database is composed of 35 subjects with and = 1, 3, 5, . We used the 3, 5 and -values for the RTOP approximation (i.e. the large -value analysis), and 0, 0.1 and for the Spiked LEMONADE approximation. We used MAPL with the 0, 1 and -values to reduce noise and interpolate a -value of to improve the estimations. was estimated as of the mean diffusivity in the ventricles.
The spatial distribution of the estimated parameters were mapped to the MNI template, averaged over all subjects, and then projected onto an inflated cortical surface using FreeSurfer. We have then evaluated whether such distributions seemed physiologically plausible by using the Brodmann atlas (Brodmann, 1909; Zilles, 2018), which is a parcellation of the brain based on cytoarchitecture features. In addition, we compared qualitatively the results of soma estimations with Nissl-stained histological images of cytoarchitecture (Allman et al., 2010; Amunts et al., 1999; Geyer et al., 1999).
4.4 HCP 1200
We proceeded with our analysis on real data using a more challenging database, in which the dMRI signals were acquired with only a few small -values. Our goal was to demonstrate that the credible regions obtained via the posterior approximation can be used to inform which parameters remain possible to estimate even in very challenging situations. Note that this unlocks the door to the analysis of any dMRI database, since the estimates always come with a “quality certificate”.
We applied our pipeline to a subset of the HCP 1200 database. We randomly picked 30 subjects, to have an identical number of subjects to that in our analysis of the HCP MGH database. The data were acquired for -values equal to 1, 2 and , with . Using MAPL, we interpolated a b-shell at to improve the computation of the summary statistics. We used all the three lowest -values for the Spiked LEMONADE approximation, and = 2, 2.8 and for the high -value approximation based on RTOP. Similarly to the HCP MGH dataset, we have averaged the parameter estimations in a common space (MNI) and then projected the resulting parametric maps onto an inflated cortical surface.
4.5 Software
All our experiments have been implemented with Python (Van Rossum and Drake, 2009) using several scientific packages: dMRI signals were simulated with the package dmipy (Fick et al., 2019) and processed using dipy (Garyfallidis et al., 2014) or custom implementations based on numpy (Harris et al., 2020). We used the sbi (Tejero-Cantero et al., 2020) and nflows (Durkan et al., 2020) packages for carrying out the LFI procedures and combined them with data structures and functions from pyTorch (Paszke et al., 2019). The figures of results on real experimental data were generated with mayavi (Ramachandran and Varoquaux, 2011).
5 Results
In this section, we describe our results obtained on simulated data and two real datasets.
5.1 Simulated data
5.1.1 Validating the LFI pipeline.
In this first round of experiments, our aim was to check whether the LFI pipeline worked correctly on a setting where we knew the true values of the parameter (ground truth) generating the observed data . Furthermore, we wanted to confirm whether the use of summary statistics for the dMRI signal actually conveyed any improvements in the parameter estimation. We have considered, therefore, three different cases:
- –
Case 1. Generate directly from using the forward model defined in Section 4.1. This is a rather favorable case for our posterior approximation, since it is applied on a data point generated in the same way as the dataset in which it was trained.
- –
Case 2. Generate a dMRI signal from using dmipy and then obtain by calculating the summary statistics presented in Section 3.2. We use the same posterior approximator from Case 1, meaning that the data point in inference time is generated differently from those for the training procedure. This is the actual realistic case that interests us the most.
- –
Case 3. Generate a dMRI signal from using dmipy and do not use any summary statistics for the model inversion, i.e. consider . Note that the posterior approximator has to be trained on a dataset with observations consisting of dMRI signals, so it is different from the approximators in Case 1 and Case 2. Depending on how the LFI pipeline behaves on this case, the use of summary statistics can be justified or not.
All simulations were carried out with setup Ideal, which corresponds to an ideal dMRI acquisition scheme, and the posterior approximators were trained with simulated data points. While we have validated the LFI pipeline on multiple choices of physiologically relevant ground truth parameters , Figure 1 portrays the results only for
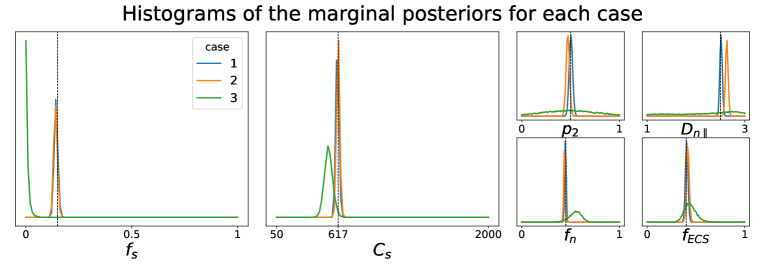
This choice of parameters represent a sample tissue containing pyramidal neurons of radius (Palombo et al., 2021) and diffusivity . The three compartment proportions were chosen in accordance to reported values from histology of human grey matter tissue (Shapson-Coe et al., 2021). Results are presented in Figure 1. We see that in Case 1 the marginals of the posterior distribution are well concentrated around the values of the ground truth parameter . This confirms that the posterior approximator successfully inverts the non-linear model using the examples in the training set. We also see that the parameter estimation in Case 2 captures very well most of the true values of the parameters, indicating both that our posterior approximator is robust to observed data generated differently from its training set and that our summary statistics are descriptive enough to synthesize each tissue configuration. Finally, the poor results in the estimation for Case 3 reflect the largely indeterminate system of equations that results from trying to infer the tissue parameters directly from the dMRI signals. This behavior was expected, as similar degeneracies were shown for a simpler model in Novikov et al. (2018a).
5.1.2 Influence of the number of -values.
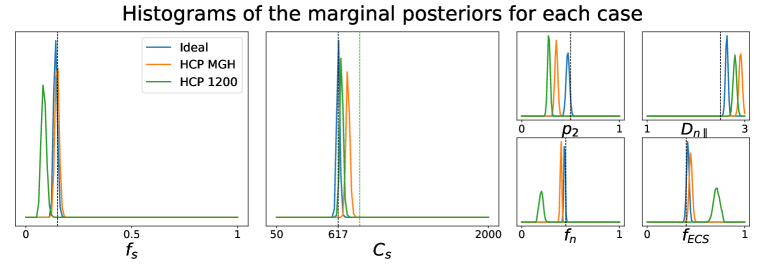
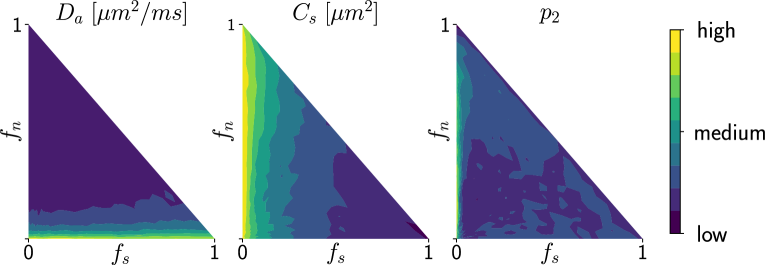
We have also investigated how different choices of -values in the acquisition scheme affect the quality of the parameter estimation using the posterior approximation. Note that these choices have no influence on how the posterior approximator is obtained, since it is trained on data generated directly from the relations between tissue parameters and the diffusion summary statistics, in which the -values do not interact. In fact, the different acquisition setups that we consider have only an impact over the observed data point generated via dmipy. Figure 2 portrays the marginal posterior distributions for each tissue parameter in setups Ideal, HCP MGH, and HCP 1200. We see that estimations in the Ideal setup (equivalent to Case 2 in Figure 1) are very much concentrated around the true values of the parameters. For HCP MGH and HCP 1200 the estimations of the soma-related parameters are rather good, but a small bias is present for the other parameters in HCP MGH and even more for HCP 1200. Note that the Ideal and HCP MGH ground truth value of (vertical black dashed line) is different from the one of the HCP 1200 setup (vertical green dashed line), because of their different diffusion times. These simulations allow us to have a fair confidence in the estimations on real data, presented in Sections 5.2 and 5.3.
5.1.3 Our new parameter avoids model indeterminacy.
In Section 3.1, we introduce the parameter , which serves as a proxy of the soma radius and provides key information on the soma compartment. In this experiment, we illustrate the results of our model inversion if we had not defined parameter .
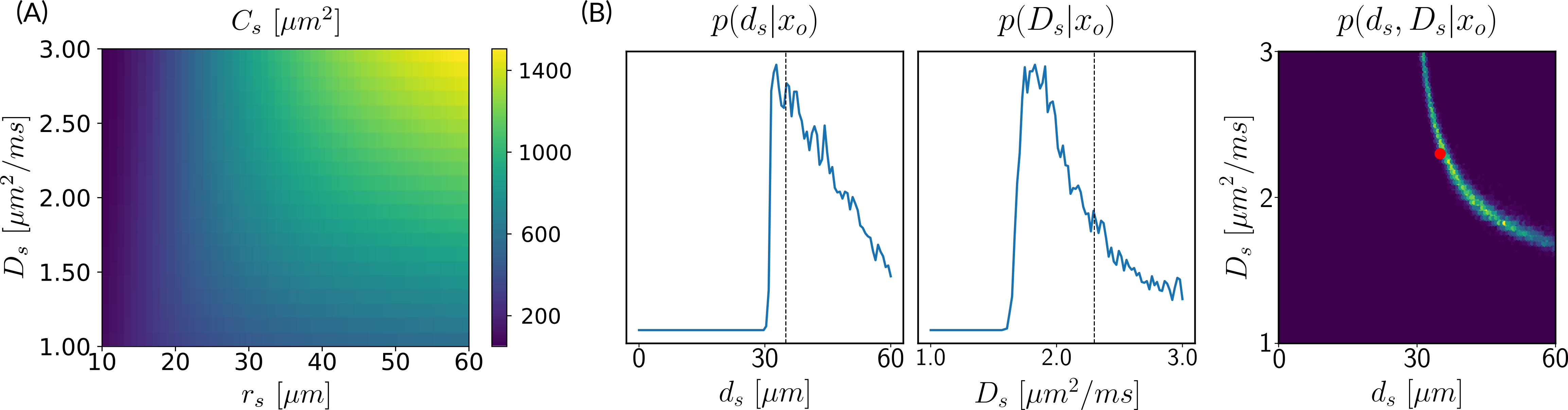
Figure 3 presents the marginal posterior distributions of and as well as their joint distribution using the setup Ideal. To obtain these results, we have altered our LFI pipeline so to consider an extended parameter vector including and . The prior distribution reflects our assumption that and and we consider ground truth parameters and . We note that in addition to larger marginal posterior distributions for each parameter, the joint posterior has a valley of large values for the pair, including the ground truth parameters. This result is typical of non-injective models, i.e. models for which several input parameters may yield the same output observation, and is an important asset of a probabilistic framework such as ours.
5.1.4 Assessing the variances of estimated parameters.
Deriving the posterior distributions of the parameter vectors allows us to report the values of the most likely tissue parameters for a given observation, along with our certitude regarding our inference. Figure 4 presents the logarithm of the standard deviation of the marginal posterior samples for different ground truth parameter choices (varying and ) under setup Ideal. These values indicate how sharp a posterior distribution is and, therefore, quantify the quality of the fit. We observe larger standard deviations in the absence (or weak presence) of soma compartments in the mixture signal, e.g., the standard deviation of is large when few or no somas are present (). This is to be expected, since the lack of contribution from the somas in the diffusion signal makes it difficult to estimate parameters related to them.
5.2 HCP MGH
Our results on simulated data show that, although we manage to invert very well the brain tissue parameter on settings for which the dMRI signal is obtained with several -values, the estimates for more realistic settings are less robust and demand a more subtle analysis. Indeed, we have observed that for both setups HCP MGH and HCP 1200 the soma parameters seem to be rather well estimated without too much bias, which has lead us to consider mainly these parameters in our interpretations of the results.
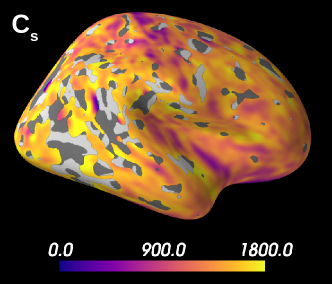
Figure 5 presents the results on the HCP MGH dataset. The inference takes approximately one hour per subject using 20 CPUs, and the estimation of the seven parameters for every voxel in the grey matter is about 3 hours per subject, when computed in parallel on 20 CPUs. We have masked our results so to show only areas where parameters were deemed stable, i.e. when the values were larger than 2 times the LFI-obtained standard deviations of the fitted posterior, indicating that the posterior distribution is narrow and centered around its mean value. We observe a lack of stability on small sections including the auditory cortex and the precentral gyrus fundus. Our figure assesses qualitatively the results on soma size by comparing with Nissl-stained histological studies (Allman et al., 2010; Amunts et al., 1999; Geyer et al., 1999). Our comparison shows good agreement between different cortical areas and the parameter , which, under nearly-constant intra-soma diffusion , is modulated by soma size. Note that we modeled brain gray matter as homogeneous per voxel. That is, we suppose only one type of neuron is present in each voxel. The most probable one is returned by the LFI approach.
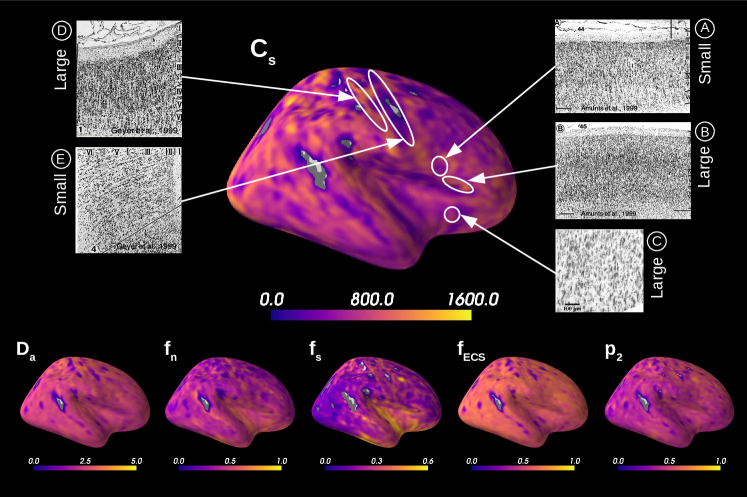
Interestingly, most regions of Figure 6 in which the parameter estimation has low confidence are located in the fundus of the sulci. Two main hypothesis could explain such behavior. Firstly, brain regions which are very curved may be more prone to mixing between tissue layers and CSF, which generates noisier signals. Thus, the estimation of summary statistics becomes more biased and the posterior distributions tend to be wider. Another possible explanation, based on cytoarchitecture considerations, points out the fact that the fundus of sulci is where sharp changes in cellular populations happen (Brodmann, 1909; Pandya et al., 2015). A mixing of several types of neurons in one voxel could generate multi-modal posterior distributions, and hence a region with large variance.
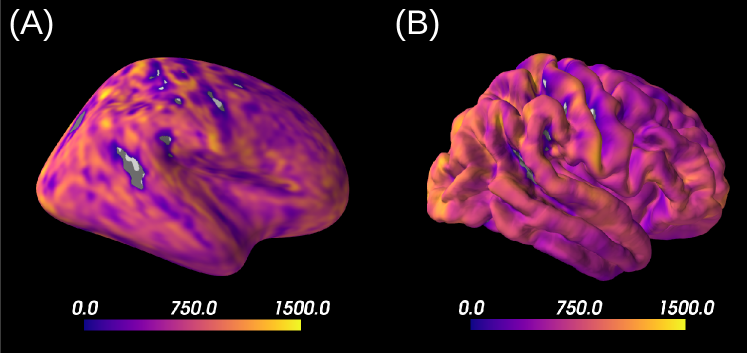
Figure 7A reports the soma proportion (parameter ) averaged over 31 HCP MGH subjects, masking unstable results. Mean soma signal proportion in the cortex equals (mean computed in trusted estimations only). These results are coherent with the mean volume occupancy of observed in grey matter (Shapson-Coe et al., 2021). To interpret the results at a region-based level, we have superimposed the soma proportion estimations with the Brodmann atlas. We observe a general agreement between the estimations and the atlas, and more particularly in the somatosensory and Broca’s areas. A clear difference in soma proportion can be observed in the 12 regions, as presented in the barplot.
Despite the parameter being useful for avoiding indeterminacies in the model inversion, its biological interpretation remains difficult. With the goal of relating our estimation with physiological insight, we estimated soma radius by fixing soma diffusivity. Similarly to the SANDI method, we fixed soma diffusivity to the value of the self-diffusion coefficient of free water (). Note that this value could be adjusted for each voxel, and is only used here in a matter of comparison and interpretation. Using a fixed-point method, we computed the soma radius from the averaged map obtained from our posterior distribution. The results are portrayed in Figure 7B. We see that the estimated soma radius vary between and , which is in accordance with histology (Palombo et al., 2021). Mean values are presented in the barplot beneath the soma radius estimations in the different Brodmann regions.
5.3 HCP 1200
Figure 8 shows the results obtained on a database with only three -shells. We see that 55 % of the estimations on brain grey matter is considered unstable and is, therefore, masked. Indeed, our -bounded RTOP approximation relies on high -values, where the signal is expected to have converged towards a value that depends on the radius of the soma. The larger the soma, the sooner the -bounded RTOP converges. However, the largest -value contained in this database equals , which is not enough for the signal to have converged. Thus, the poor quality of the summary statistics estimation leads to rather wide posterior distributions, resulting in unreliable results, as shown in simulations. Note, however, that estimations of the superior temporal gyrus for example are not masked, and both data sets seem to indicate large neurones in that region. The estimation of is considered as unstable for 98.7% of the data set. This behavior was expected, given the results presented in Figure 2, for which a large bias is observed.
6 Discussion
6.1 Validation simulated data
An important aspect of our work is the thorough validation that we have carried out on simulated data, using different acquisition setups and ways of generating diffusion signals. Part of this validation had the goal of ensuring that our method gave consistent results on simple standard cases, as confirmed by the results in Figure 1. Additionally, we have demonstrated the benefits of using summary statistics for describing dMRI signals, attaining better parameter estimates when using them instead of directly manipulating the diffusion signals. Such results are very encouraging and should push other researchers into using these summary statistics for processing their dMRI signals.
Another relevant byproduct of our validation was observing that the quality of the parameter estimations depends heavily on the distribution of -values used to acquire and simulate the dMRI signals. Indeed, if only small -values are available, the summary statistics of dMRI signals are poorly estimated and the parameter estimation too. Based on this observation, we were able to apply our LFI pipeline to real datasets HCP MGH and HCP 1200 knowing in advance the limitations of our methodology; for example, we knew from which parameters we could expect good estimates (mostly soma-related ones) and which ones should not be taken into account in our analysis.
6.2 : A proxy to soma size
Estimating both soma radius () and diffusivity () with diffusion MRI is a challenging task. When trying to estimate them separately, we can expect a ‘banana-shape’ in their joint posterior distribution as shown in Figure 3. This indicates that several values of the pair (, ) can explain the observed signal with high probability and, therefore, one is confronted with model indeterminacy.
The new parameter that we introduce in this paper is modulated both by the soma radius and its diffusivity. Thus, estimating it directly avoids problems of indeterminacy, as shown in Figure 1, for example. Note, however, that avoiding such indeterminacy comes with the price of losing specificity and, therefore, physiological interpretations. Fortunately, acquisitions in the narrow or wide pulse regimes allow us to better interpret estimations of , as it only depends on or (see Section 3.1).
6.3 Can I apply this approach to my data?
One of the main benefits of a probabilistic framework is that it can be applied to any data set or acquisition setup without too much hesitation, since the estimates always come with a “quality certificate” described by the credible regions derived from the posterior distribution. We have benefited from this feature when creating all figures related to databases HCP MGH and HCP 1200, since they allow us to mask regions for which the variance of the parameter estimation is too high. We can also use it as a proxy to identify regions for which the three-compartment model is adequate or not, or assessing whether the distribution of -values used to acquire the observed diffusion signal is sufficiently informative. Note, however, that it would not be realistic to expect that our method should give acceptable results on every database to which it is applied. Indeed, the distribution of -values used to acquire the data under study is a key predictor of whether the estimated posterior distribution will be useful for inverting the three-compartment model or not. For instance, if the -values are too small, then the RTOP summary statistics will be poorly estimated in most voxels, leading to unreliable estimations; only regions with larger somas will be correctly estimated. Similarly, if the acquisition uses only -values much greater than zero, the Spiked LEMONADE moments will be biased, which also leads to neurite estimations with large variability. These observations were useful when analyzing the HCP 1200 database, since the distribution of -values are concentrated at low values and, therefore, our estimations are prone to bias and have large variances.
6.4 Limitations and perspectives
There are many extensions that we could envision for the method that we propose.
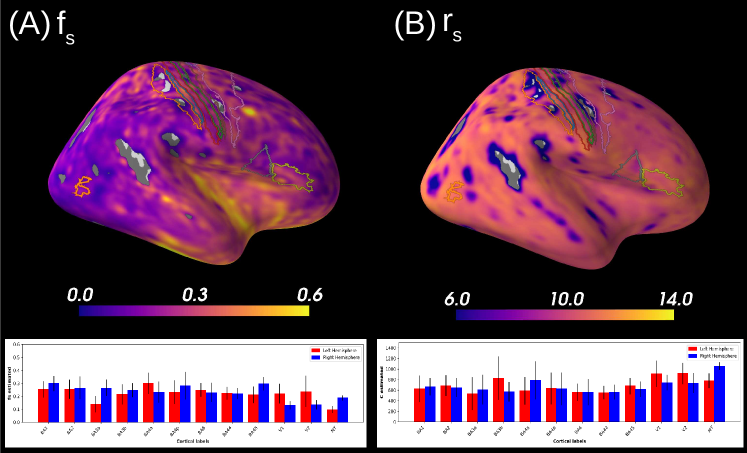
The proposed approach has been designed and applied to brain grey matter, but one could also want to apply it to brain white matter (see Supplementary Material). Results on the HCP MGH dataset indicate that the axons distribution is more anisotropic in white matter than grey matter (), with values coherent to the ones obtained with the LEMONADE framework (Novikov et al., 2018b). Somas are also less present in white matter than grey matter, as indicated by a lower signal fraction , which is expected from histology (Shapson-Coe et al., 2021). However, the ECS model used in the three-compartment model defines its diffusivity as isotropic. While this assumption seems to hold in brain gray matter, a tensor representation is usually preferred for the ECS diffusivity, as it is the case in the SM (Novikov et al., 2018a). The application of a similar LFI pipeline based on a model designed for brain white matter (such as the SM) could help improve the estimations of tissue parameters and better interpret its output thanks to the posterior distributions. As an example, this pipeline could be a new way to solve the LEMONADE system of equations proposed by Novikov et al. (2018b) within a probabilistic framework.
The three-compartment model that we use approximates well the intra-cellular signal in brain grey matter tissue by adding a sphere compartment to account for soma presence (Palombo et al., 2020). However, this is a rather simplified model and it could be improved; for instance, the geometry of ECS is very restricted and tortuous, and diffusion signals have been proven to deviate from a mono-exponential behavior (Vincent et al., 2021). A first improvement could be, as mentioned before, to deviate from modelling the ECS diffusion with a simple isotropic Gaussian and consider more complex geometric representations. Another improvement would be to consider exchanges between the neurites and the ECS (Jelescu et al., 2021; Olesen et al., 2021).
In this method, we require to have a signal with large -values to extract summary statistics using RTOP. This constraint limits the number of possible applications, as many dMRI datasets do not contain such high -values. A solution proposed by Golkov et al. (2016) is to rely on deep learning to learn a mapping between a limited number of DWIs and some microstructure scalars, assuming that all the necessary information is contained in the low-dimensional acquisition. Following this -space deep learning method, an improvement of the proposed method could be to learn the summary statistics from a dataset with less -shells using deep learning, and then apply our likelihood-free inference method to solve the inverse problem.
Finally, we could leverage the modularity of the probabilistic framework and apply our methodology to other kinds of models in medical imaging. This could be done by simply re-defining the forward model and the summary statistics defined in Section 4.1. Such flexibility confirms the generality of our approach and the potential impact that it might have in the medical imaging field.
7 Conclusion
Quantifying grey matter tissue composition is challenging. In this work, we have presented a methodology to estimate the parameters of a model that best fit an observed data point, and also their full posterior distribution. This rich description provides many useful tools, such as assessing the quality of the parameter estimation or characterizing regions in the parameter space where it is harder to invert the model. The inclusion of such “quality certificate” accompanying our parameter estimation is very useful in practice and allows one to apply the pipeline on any kind of database and know to which degree one can trust the results. Moreover, our proposal alleviates limitations from current methods in the literature by not requiring physiologically unrealistic constraints on the parameters and avoiding indeterminacies when estimating them.
To conclude, we believe that our approach based on Bayesian inference with modern tools from neural networks is a promising one that can easily be applied to other applications in the medical imaging field: one only needs to define a sufficiently rich model describing a certain phenomenon of interest and the LFI pipeline will manage to invert it and provide a related posterior distribution. We expect, therefore, that other researchers will find this contribution valuable for their own applications and see such probabilistic approach more often used in the literature.
Acknowledgments
Experiments on diffusion MRI data were made possible thanks to DiPy (Garyfallidis et al., 2014), as well as the scientific Python ecosystem: Python (Van Rossum and Drake, 2009), Matplotlib (Hunter, 2007), Numpy (Harris et al., 2020), Scipy (Virtanen et al., 2020), Mayavi (Ramachandran and Varoquaux, 2011), SBI (Tejero-Cantero et al., 2020) and PyTorch (Paszke et al., 2019).
This work was supported by grants ERC-StG NeuroLang ID:757672 and ANR-NSF NeuroRef to DW and the ANR BrAIN (ANR-20-CHIA-0016) grant to AG.
Ethical Standards
The work follows appropriate ethical standards in conducting research and writing the manuscript, following all applicable laws and regulations regarding treatment of animals or human subjects.
Conflicts of Interest
We declare we don’t have conflicts of interest.
References
- Allman et al. (2010) John M. Allman, Nicole A. Tetreault, Atiya Y. Hakeem, Kebreten F. Manaye, Katerina Semendeferi, Joseph M. Erwin, Soyoung Park, Virginie Goubert, and Patrick R. Hof. The von Economo neurons in frontoinsular and anterior cingulate cortex in great apes and humans. Brain Structure and Function, 214:495–517, June 2010.
- Amunts et al. (1999) Katrin Amunts, Axel Schleicher, Uli Bürgel, Hartmut Mohlberg, Harry B.M. Uylings, and Karl Zilles. Broca’s region revisited: Cytoarchitecture and intersubject variability. Journal of Comparative Neurology, 412(2):319–341, 1999.
- Balinov et al. (1993) Balin Balinov, Jönsson, Per Linse, and Olle Söderman. The NMR Self-Diffusion Method Applied to Restricted Diffusion. Simulation of Echo Attenuation form Molecules in Spheres and between Planes. Journal of Magnetic Resonance, Series A, 104(1):17–25, 1993.
- Brodmann (1909) Korbinian Brodmann. Vergleichende Lokalisationslehre der Grosshirnrinde in ihren Prinzipien dargestellt auf Grund des Zellenbaues. Barth, 1909.
- Cranmer et al. (2020) Kyle Cranmer, Johann Brehmer, and Gilles Louppe. The frontier of simulation-based inference. Proceedings of the National Academy of Sciences, 117(48):30055–30062, 2020.
- Douaud et al. (2013) Gwenaëlle Douaud, Ricarda A. L. Menke, Achim Gass, Andreas U. Monsch, Anil Rao, Brandon Whitcher, Giovanna Zamboni, Paul M. Matthews, Marc Sollberger, and Stephen Smith. Brain microstructure reveals early abnormalities more than two years prior to clinical progression from mild cognitive impairment to alzheimer’s disease. Journal of Neuroscience, 33(5):2147–2155, 2013. ISSN 0270-6474. doi: 10.1523/JNEUROSCI.4437-12.2013. URL https://www.jneurosci.org/content/33/5/2147.
- Durkan et al. (2020) Conor Durkan, Artur Bekasov, Iain Murray, and George Papamakarios. nflows: normalizing flows in PyTorch. November 2020. doi: 10.5281/zenodo.4296287.
- Fick et al. (2019) Rutger H. J. Fick, Demian Wassermann, and Rachid Deriche. The Dmipy Toolbox: Diffusion MRI Multi-Compartment Modeling and Microstructure Recovery Made Easy. Frontiers in Neuroinformatics, 13:64, October 2019.
- Fick et al. (2016) Rutger H.J. Fick, Demian Wassermann, Emmanuel Caruyer, and Rachid Deriche. MAPL: Tissue microstructure estimation using Laplacian-regularized MAP-MRI and its application to HCP data. NeuroImage, 134:365–385, July 2016.
- Garyfallidis et al. (2014) Eleftherios Garyfallidis, Matthew Brett, Bagrat Amirbekian, Ariel Rokem, Stefan Van Der Walt, Maxime Descoteaux, and Ian Nimmo-Smith. Dipy, a library for the analysis of diffusion mri data. Frontiers in Neuroinformatics, 8:8, 2014. ISSN 1662-5196. doi: 10.3389/fninf.2014.00008. URL https://www.frontiersin.org/article/10.3389/fninf.2014.00008.
- Gelman et al. (2013) A. Gelman, J.B. Carlin, H.S. Stern, D.B. Dunson, A. Vehtari, and D.B. Rubin. Bayesian Data Analysis, Third Edition. Chapman & Hall/CRC Texts in Statistical Science. Taylor & Francis, 2013. ISBN 9781439840955. URL https://books.google.fr/books?id=ZXL6AQAAQBAJ.
- Germain et al. (2015) Mathieu Germain, Karol Gregor, Iain Murray, and Hugo Larochelle. Made: Masked autoencoder for distribution estimation. In Proceedings of the 32nd International Conference on Machine Learning, volume 37, pages 881–889. PMLR, 2015.
- Geyer et al. (1999) Stefan Geyer, Axel Schleicher, and Karl Zilles. Areas 3a, 3b, and 1 of Human Primary Somatosensory Cortex. NeuroImage, 10(1):63–83, July 1999. ISSN 10538119.
- Golkov et al. (2016) Vladimir Golkov, Alexey Dosovitskiy, Jonathan I Sperl, Marion I Menzel, Michael Czisch, Philipp Sämann, Thomas Brox, and Daniel Cremers. Q-space deep learning: twelve-fold shorter and model-free diffusion mri scans. IEEE transactions on medical imaging, 35(5):1344–1351, 2016.
- Gonçalves et al. (2020) Pedro J Gonçalves, Jan-Matthis Lueckmann, Michael Deistler, Marcel Nonnenmacher, Kaan Öcal, Giacomo Bassetto, Chaitanya Chintaluri, William F Podlaski, Sara A Haddad, Tim P Vogels, David S Greenberg, and Jakob H Macke. Training deep neural density estimators to identify mechanistic models of neural dynamics. eLife, 9, September 2020.
- Goodfellow et al. (2016) Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
- Goodfellow et al. (2014) Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks, 2014.
- Greenberg et al. (2019) David Greenberg, Marcel Nonnenmacher, and Jakob Macke. Automatic posterior transformation for likelihood-free inference. In Proceedings of the 36th International Conference on Machine Learning, volume 97, pages 2404–2414. PMLR, 2019.
- Harris et al. (2020) Charles R. Harris, K. Jarrod Millman, St’efan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fern’andez del R’ıo, Mark Wiebe, Pearu Peterson, Pierre G’erard-Marchant, Kevin Sheppard, Tyler Reddy, Warren Weckesser, Hameer Abbasi, Christoph Gohlke, and Travis E. Oliphant. Array programming with NumPy. Nature, 585(7825):357–362, September 2020. doi: 10.1038/s41586-020-2649-2. URL https://doi.org/10.1038/s41586-020-2649-2.
- Hunter (2007) John D Hunter. Matplotlib: A 2d graphics environment. Computing in science & engineering, 9(3):90–95, 2007.
- Jelescu and Budde (2017) Ileana O. Jelescu and Matthew D. Budde. Design and validation of diffusion MRI models of white matter. Frontiers in Physics, 5, November 2017. doi: 10.3389/fphy.2017.00061. URL https://doi.org/10.3389/fphy.2017.00061.
- Jelescu et al. (2016) Ileana O. Jelescu, Jelle Veraart, Els Fieremans, and Dmitry S. Novikov. Degeneracy in model parameter estimation for multi-compartmental diffusion in neuronal tissue: Degeneracy in Model Parameter Estimation of Diffusion in Neural Tissue. NMR in Biomedicine, 29(1):33–47, January 2016.
- Jelescu et al. (2021) Ileana O. Jelescu, Alexandre de Skowronski, Marco Palombo, and Dmitry S. Novikov. Neurite exchange imaging (nexi): A minimal model of diffusion in gray matter with inter-compartment water exchange, 2021.
- Kingma and Ba (2014) Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. International Conference on Learning Representations, 12 2014.
- Kingma and Welling (2019) Diederik P. Kingma and Max Welling. An introduction to variational autoencoders. Foundations and Trends® in Machine Learning, 12(4):307–392, 2019. ISSN 1935-8237. doi: 10.1561/2200000056. URL http://dx.doi.org/10.1561/2200000056.
- Li et al. (2016) Hua Li, Xiaoyu Jiang, Jingping Xie, John C. Gore, and Junzhong Xu. Impact of transcytolemmal water exchange on estimates of tissue microstructural properties derived from diffusion MRI. Magnetic Resonance in Medicine, 77(6):2239–2249, June 2016. doi: 10.1002/mrm.26309. URL https://doi.org/10.1002/mrm.26309.
- Menon et al. (2020) Vinod Menon, Guillermo Gallardo, Mark A Pinsk, Van-Dang Nguyen, Jing-Rebecca Li, Weidong Cai, and Demian Wassermann. Microstructural organization of human insula is linked to its macrofunctional circuitry and predicts cognitive control. elife, 9:e53470, 2020.
- Mitra et al. (1995) P. P. Mitra, L. L. Latour, R. L. Kleinberg, and C. H. Sotak. Pulsed-field-gradient NMR measurements of restricted diffusion and the return-to-origin probability. Journal of Magnetic Resonance, 114:47–58, 1995.
- Murday and Cotts (1968) J. S. Murday and R. M. Cotts. Self‐diffusion coefficient of liquid lithium. The Journal of Chemical Physics, 48(11):4938–4945, 1968. doi: 10.1063/1.1668160.
- Novikov et al. (2018a) Dmitry S. Novikov, Els Fieremans, Sune N. Jespersen, and Valerij G. Kiselev. Quantifying brain microstructure with diffusion MRI: Theory and parameter estimation: Brain microstructure with dMRI: Theory and parameter estimation. NMR in Biomedicine, page e3998, October 2018a. ISSN 09523480.
- Novikov et al. (2018b) Dmitry S. Novikov, Jelle Veraart, Ileana O. Jelescu, and Els Fieremans. Rotationally-invariant mapping of scalar and orientational metrics of neuronal microstructure with diffusion MRI. NeuroImage, 174:518–538, July 2018b.
- Olesen et al. (2021) Jonas L Olesen, Leif Østergaard, Noam Shemesh, and Sune N Jespersen. Diffusion time dependence, power-law scaling, and exchange in gray matter. arXiv preprint arXiv:2108.09983, 2021.
- Palombo et al. (2021) M Palombo, D Alexander, and H Zhang. Large-scale analysis of brain cell morphometry informs microstructure modelling of gray matter., May 2021. URL https://www.ismrm.org/21m/.
- Palombo et al. (2020) Marco Palombo, Andrada Ianus, Michele Guerreri, Daniel Nunes, Daniel C. Alexander, Noam Shemesh, and Hui Zhang. SANDI: A compartment-based model for non-invasive apparent soma and neurite imaging by diffusion MRI. NeuroImage, 215:116835, 2020.
- Pandya et al. (2015) Deepak Pandya, Michael Petrides, and Patsy Benny Cipolloni. Cerebral cortex: architecture, connections, and the dual origin concept. Oxford University Press, 2015.
- Papamakarios and Murray (2016) George Papamakarios and Iain Murray. Fast -free inference of simulation models with bayesian conditional density estimation. In Advances in Neural Information Processing Systems, volume 29, pages 1028–1036. Curran Associates, Inc., 2016.
- Papamakarios et al. (2019) George Papamakarios, Eric T. Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and inference. ArXiv, abs/1912.02762, 2019.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems (NeurIPS), page 12, Vancouver, BC, Canada, 2019.
- Ramachandran and Varoquaux (2011) P. Ramachandran and G. Varoquaux. Mayavi: 3D Visualization of Scientific Data. Computing in Science & Engineering, 13(2):40–51, 2011. ISSN 1521-9615.
- Setsompop et al. (2013) K. Setsompop, R. Kimmlingen, E. Eberlein, T. Witzel, J. Cohen-Adad, J.A. McNab, B. Keil, M.D. Tisdall, P. Hoecht, P. Dietz, S.F. Cauley, V. Tountcheva, V. Matschl, V.H. Lenz, K. Heberlein, A. Potthast, H. Thein, J. Van Horn, A. Toga, F. Schmitt, D. Lehne, B.R. Rosen, V. Wedeen, and L.L. Wald. Pushing the limits of in vivo diffusion MRI for the Human Connectome Project. NeuroImage, 80:220 – 233, 2013.
- Shapson-Coe et al. (2021) Alexander Shapson-Coe, Michał Januszewski, Daniel R. Berger, Art Pope, Yuelong Wu, Tim Blakely, Richard L. Schalek, Peter Li, Shuohong Wang, Jeremy Maitin-Shepard, Neha Karlupia, Sven Dorkenwald, Evelina Sjostedt, Laramie Leavitt, Dongil Lee, Luke Bailey, Angerica Fitzmaurice, Rohin Kar, Benjamin Field, Hank Wu, Julian Wagner-Carena, David Aley, Joanna Lau, Zudi Lin, Donglai Wei, Hanspeter Pfister, Adi Peleg, Viren Jain, and Jeff W. Lichtman. A connectomic study of a petascale fragment of human cerebral cortex. bioRxiv, 2021. doi: 10.1101/2021.05.29.446289. URL https://www.biorxiv.org/content/early/2021/05/30/2021.05.29.446289.
- Sisson (2018) Scott A. Sisson. Handbook of Approximate Bayesian Computation. Chapman and Hall/CRC, September 2018.
- Stuart (2010) A. M. Stuart. Inverse problems: A bayesian perspective. Acta Numerica, 19:451–559, 2010. doi: 10.1017/S0962492910000061.
- Tax et al. (2020) Chantal M.W. Tax, Filip Szczepankiewicz, Markus Nilsson, and Derek K. Jones. The dot-compartment revealed? diffusion mri with ultra-strong gradients and spherical tensor encoding in the living human brain. NeuroImage, 210:116534, 2020.
- Tejero-Cantero et al. (2020) Alvaro Tejero-Cantero, Jan Boelts, Michael Deistler, Jan-Matthis Lueckmann, Conor Durkan, Pedro J. Gonçalves, David S. Greenberg, and Jakob H. Macke. sbi: A toolkit for simulation-based inference. Journal of Open Source Software, 5(52):2505, 2020. doi: 10.21105/joss.02505.
- Van Rossum and Drake (2009) Guido Van Rossum and Fred L. Drake. Python 3 Reference Manual. CreateSpace, Scotts Valley, CA, 2009. ISBN 1441412697.
- Veraart et al. (2019) Jelle Veraart, Els Fieremans, and Dmitry S. Novikov. On the scaling behavior of water diffusion in human brain white matter. NeuroImage, 185:379–387, January 2019.
- Veraart et al. (2020) Jelle Veraart, Daniel Nunes, Umesh Rudrapatna, Els Fieremans, Derek K Jones, Dmitry S Novikov, and Noam Shemesh. Noninvasive quantification of axon radii using diffusion MRI. eLife, 9, February 2020.
- Vincent et al. (2021) Mélissa Vincent, Mylène Gaudin, Covadonga Lucas-Torres, Alan Wong, Carole Escartin, and Julien Valette. Characterizing extracellular diffusion properties using diffusion-weighted mrs of sucrose injected in mouse brain. NMR in Biomedicine, 34(4):e4478, 2021. doi: https://doi.org/10.1002/nbm.4478. URL https://analyticalsciencejournals.onlinelibrary.wiley.com/doi/abs/10.1002/nbm.4478.
- Virtanen et al. (2020) Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, İlhan Polat, Yu Feng, Eric W. Moore, Jake VanderPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E. A. Quintero, Charles R. Harris, Anne M. Archibald, Antônio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272, 2020. doi: 10.1038/s41592-019-0686-2.
- Zhang et al. (2012) Hui Zhang, Torben Schneider, Claudia A. Wheeler-Kingshott, and Daniel C. Alexander. NODDI: Practical in vivo neurite orientation dispersion and density imaging of the human brain. NeuroImage, 61(4):1000 – 1016, 2012.
- Zilles (2018) Karl Zilles. Brodmann: a pioneer of human brain mapping—his impact on concepts of cortical organization. Brain, 141(11):3262–3278, October 2018. doi: 10.1093/brain/awy273. URL https://doi.org/10.1093/brain/awy273.
Appendix A.
In this appendix we present additional experimental results of brain white matter microstructure estimations using the proposed method.
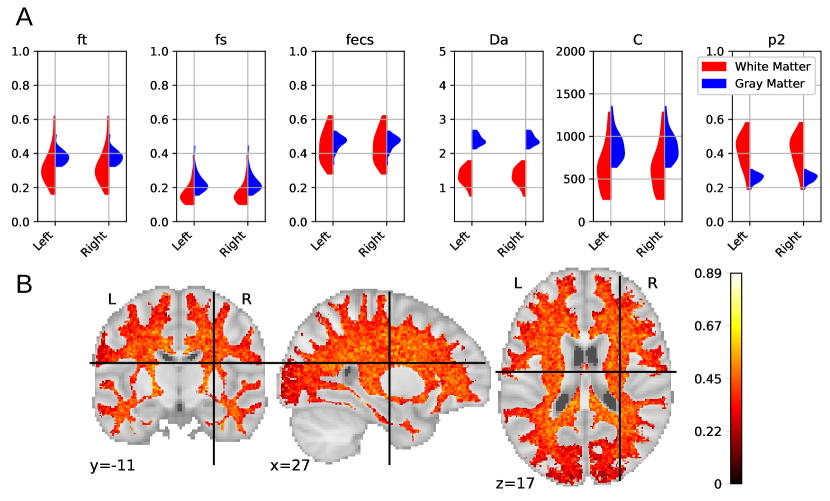
Figure 9 A presents a comparison of the mean estimations of white matter and gray matter parameters among all HCP MGH subjects, keeping only trusted voxels. We can observe a lower proportion of somas in white matter () along with smaller soma size compared with grey matter (). This weak presence of small somas in white matter is in accordance with histology. These results also indicate a more anisotropic distribution of axons is white matter than neurites in grey matter (). Obtained values are coherent to the ones obtained with the LEMONADE framework (Novikov et al., 2018b). Figure 9 B presents the mean values in white matter averaged over all subjects, keeping only trusted estimations. The center of brain white matter appears more anisotropic than at the frontier with grey matter.
In this paper we approximate the ECS with an isotropic diffusion. Models specific to brain white matter, such as the SM, usually represent ECS diffusivity as a non-isotropic tensor (Novikov et al., 2018a). Results obtained from this model should then be taken with caution, because this model does not reflect white matter tissue properly.