1 Introduction
The analysis of medical imaging datasets requires the joint modeling of multiple views (or modalities), such as clinical scores and multi-modal medical imaging data. For example, in dataset from neurological studies, views are generated through different medical imaging data acquisition processes, as for instance Magnetic Resonance Imaging (MRI) or Positron Emission Tomography (PET). Each view provides specific information about the pathology, and the joint analysis of all views is necessary to improve diagnosis, for the discovery of pathological relationships or for predicting disease evolution. Nevertheless, the integration of multi-views data, accounting for their mutual interactions and their joint variability, presents a number of challenges.
When dealing with high dimensional and noisy data it is crucial to be able to extract an informative lower dimensional representation to disentangle the relationships among observations, accounting for the intrinsic heterogeneity of the original complex data structure. From a statistical perspective, this implies the estimation of a model of the joint variability across views, or equivalently the development of a joint generative model, assuming the existence of a common latent representation generating all views.
Several data assimilation methods based on dimensionality reduction have been developed (Cunningham and Ghahramani, 2015), and successfully applied to a variety of domains. The main goal of these methods is to identify a suitable lower dimensional latent space, where meaningful statistical properties of the original dataset are identified after projection. The most basic among such methods is Principal Component Analysis (PCA) (Jolliffe, 1986), where data are projected over the axes of maximal variability. More flexible approaches based on non-linear representation of the data variability are Auto-Encoders (Kramer, 1991; Goodfellow et al., 2016), enabling to learn a low-dimensional representation minimizing the reconstruction error. In the medical imaging community, non-linear counterparts of PCA have been also proposed by extending the notion of principal components and variability to the Riemannian setting (Sommer et al., 2010; Banerjee et al., 2017).
In some cases, Bayesian counterparts of the original dimensionality reduction methods have been developed, such as Probabilistic Principal Component Analysis (PPCA) (Tipping and Bishop, 1999), based on factor analysis, or, more recently, Variational Auto-Encoders (VAEs) (Kingma and Welling, 2019), and Bayesian principal geodesic analysis (Zhang and Fletcher, 2013; Hromatka et al., 2015; Fletcher and Zhang, 2016). In particular, VAEs are machine learning algorithms based on a generative function which allows probabilistic data reconstruction from the latent space. Encoder and decoder can be flexibly parametrized by neural networks (NNs), and efficiently optimized through Stochastic Gradient Descent (SGD). The added values of Bayesian methods is to provide a tool for sampling new observations from the estimated data distribution, and quantify the uncertainty of data and parameters. In addition, Bayesian model selection criteria, such as the Watanabe-Akaike Information Criteria (WAIC) (Gelman et al., 2014), allow to perform automatic model selection.
Multi-centric biomedical studies offer a great opportunity to significantly increase the quantity and quality of available data, hence to improve the statistical reliability of their analysis. Nevertheless, in this context, three main data-related challenges should be considered. 1) Statistical heterogeneity of local datasets (i.e. center-specific datasets): observations may be non-identically distributed across centers with respect to some characteristics affecting the output (e.g. diagnosis). Additional variability in local datasets can also come from data collection and acquisition bias (Kalter et al., 2019). 2) Missing views: not all views are usually available for each center, due for example to heterogeneous data acquisition and processing pipelines. 3) Privacy concerns: privacy-preserving laws are currently enforced to ensure protection of personal data (e.g. the European General Data Protection Regulation - GDPR111https://gdpr-info.eu/), often preventing the centralized analysis of data collected in multiple centers (Iyengar et al., 2018; Chassang, 2017). These limitations impose the need for extending currently available data assimilation methods to handle decentralized heterogeneous data and missing views in local datasets.
Federated learning (FL) is an emerging analysis paradigm specifically developed for the decentralized training of machine learning models. The standard aggregation method in FL is Federated Averaging (FedAvg) (McMahan et al., 2017a), which combines locally trained models via weighted averaging. This aggregation scheme is generally sensitive to statistical heterogeneity, which naturally arises in federated datasets (Li et al., 2020), for example when dealing with multi-view data, or when data are not uniformly represented across data centers (e.g. non-iid distributed). In this case a faithful representation of the variability across centers is not guaranteed.
In order to guarantee data governance, FL methods are conceived to avoid sensitive data transfer among centers: raw data are processed within each center, and only local parameters are shared with the master. Nevertheless, no formal privacy guarantees are provided on the shared statistics, which may still reveal sensitive information about individual data points used to train the model. Differential privacy (DP) is an established framework to provide theoretical guarantees about the anonymity of the shared statistics with respect to the training data points. Recent works (Abadi et al., 2016; Geyer et al., 2017; Triastcyn and Faltings, 2019) show the importance of combining FL and DP to prevent potential information leakage form the shared parameters, while providing theoretical privacy guarantees for both clients and server.

We present here Federated multi-view PPCA (Fed-mv-PPCA), a novel FL framework for data assimilation of heterogeneous multi-view datasets. Our framework is designed to account for the heterogeneity of federated datasets through a fully Bayesian formulation. Fed-mv-PPCA is based on a hierarchical dependency of the model’s parameters to handle different sources of variability in the federated dataset (Figure 1). The method is based on a linear generative model, assuming Gaussian latent variables and noise, and allows to account for missing views and observations across datasets. In practice, we assume that there exists an ideal global distribution of each parameter, from which local parameters are generated to account for the local data distribution for each center. We show, in addition, that the privacy of the shared parameters of Fed-mv-PPCA can be explicitly quantified and guaranteed by means of DP. The code developed in Python is publicly available at https://gitlab.inria.fr/epione/federated-multi-views-ppca.
The paper is organized as follows: in Section 2 we provide a brief overview of the state-of-the-art and highlight the advancements introduced with Fed-mv-PPCA. In Section 3 we describe Fed-mv-PPCA, while its extension to improve privacy preservation through DP is provided in Section 3.2. In Section 4 we show results with applications to synthetic data and to data from the Alzheimer’s Disease Neuroimaging Initiative dataset (ADNI). Section 5 concludes the paper with a brief discussion.
2 Related Works
Several methods for dimensionality reduction based on generative models have been developed in the past years, starting from the seminal work of PPCA by Tipping and Bishop (1999), to Bayesian Canonical Correlation Analysis (CCA) (Klami et al., 2013), which Matsuura et al. (2018) extended to include multiple views and missing modalities, up to more complex methods based on multi-variate association models (Shen and Thompson, 2019), developed, for example, to integrate multi-modal brain imaging data and high-throughput genomics data. Other works with interesting applications to medical imaging data are based on Riemannian approaches to better deal with non linearity (Sommer et al., 2010; Banerjee et al., 2017), and have been extended to a latent variable formulation (Probabilistic Principal Geodesic Analysis - PPGA - by Zhang and Fletcher (2013)).
More recent methods for the probabilistic analysis of multi-views datasests include the multi channel Variational Autoencoder (mc-VAE) by Antelmi et al. (2019) and Multi-Omics Factor Analysis (MOFA) by Argelaguet et al. (2018). MOFA generalizes PPCA for the analysis of multi-omics data types, supporting different noise models to adapt to continuous, binary and count data, while mc-VAE extends the classic VAE (Kingma and Welling, 2014) to jointly account for multi-views data. Additionally, mc-VAE can handle sparse datasets: data reconstruction in testing can be inferred from available views, if some are missing.
Despite the possibility offered by the above methods for performing data assimilation and integrating multiple views, these approaches have not been conceived to handle federated datasets.
Statistical heterogeneity is a key challenge in FL and, more generally, in multi-centric studies (Li et al., 2020). To tackle this problem, Li et al. (2018) proposed the FedProx algorithm, which improves FedAvg by allowing for partial local work (i.e. adapting the number of local epochs) and by introducing a proximal term to the local objective function to avoid divergence due to data heterogeneity. Other methods have been developed under the Bayesian non-parametric formalism, such as probabilistic neural matching (Yurochkin et al., 2019), where the local parameters of NNs are federated depending on neurons similarities.
Since the development of FedAvg, researchers have been focusing in developing FL frameworks robust to the statistical heterogeneity across clients (Sattler et al., 2019; Liang et al., 2020). Most of these frameworks are however formulated for training schemes based on stochastic gradient descent, with principal applications to NNs models. Nevertheless, beyond applications taylored around NNs, we still lack of a consistent and privacy-compliant Bayesian framework for the estimation of local and global data variability, as part of a global optimization model, while accounting for data heterogeneity. In particular, FL alone does not provide clear theoretical guarantees for privacy preservation, leaving the door open to potential data leakage from malicious clients or the central server, such as through model inversion (Fredrikson et al., 2015), and researchers are currently focusing to adapt FL schemes to account for DP mechanisms (McMahan et al., 2017b).
All these considerations ultimately motivate for the development of Fed-mv-PPCA and its differential private extension. The main contributions of the work presented in this paper are the following:
- •
we theoretically develop a novel Bayesian hierarchical framework, Fed-mv-PPCA, for data assimilation from heterogeneous multi-views private federated datasets;
- •
we investigate the improvement our framework’s security against data leakage by coupling it with differential privacy, and propose DP-Fed-mv-PPCA;
- •
We apply both models to synthetic data and real multi-modal imaging data and clinical scores form the Alzheimer’s Disease Neuroimaging Initiative, demonstrating the robustness of our framework against non-iid data distribution across centers and missing modalities.
3 Methods
3.1 Federated multi-views PPCA
3.1.1 Problem setup
We consider independent centers. Each center owns a private local dataset , where we denote by the data row for subject in center , with . We assume that a total of distinct views have been measured across all centers, and we allow missing views in some local dataset (i.e. some local dataset could be incomplete, including only measurements for views). For every , the dimension of the -view (i.e. the number of features defining the -view) is , and we define . We denote by the raw data of subject in center corresponding to the -view, hence .
3.1.2 Modeling assumptions
The main assumption at the basis of Fed-mv-PPCA is the existence of a hierarchical structure underlying the data distribution. In particular, we assume that there exist global parameters , following a distribution , able to describe the global data variability, i.e. the ensemble of local datasets. For each center, local parameters are generated from , to account for the specific variability of the local dataset. Finally, local data are obtained from their local distribution . Given the federated datasets, Fed-mv-PPCA provides a consistent Bayesian framework to solve the inverse problem and estimate the model’s parameters across the entire hierarchy.
We assume that in each center , the local data of subject corresponding to the -view, , follows the generative model:
| (1) |
where is a -dimensional latent variable, and is the dimension of the latent-space. provides the linear mapping between latent space and observations for the -view, is the offset of the data corresponding to view , and is the Gaussian noise for the -view. This formulation induces a Gaussian distribution over , implying:
| (2) |
where . Finally, a compact formulation for (i.e. considering all views concatenated) can be derived from Equation (1):
| (3) |
where are obtained by concatenating all , and is a block diagonal matrix, where the -block is given by . The local parameters describing the center-specific dataset thus are . According to our hierarchical formulation, we assume that each local parameter in is a realization of a common global prior distribution described by . In particular we assume that and are normally distributed, while the variance of the Gaussian error, , follows an inverse-gamma distribution. Formally:
| (4) | |||||
| (5) | |||||
| (6) |
where denotes the matrix normal distribution of dimension .
3.1.3 Proposed framework
The assumptions made in Section 3.1.2 allow to naturally define an optimization scheme based on Expectation Maximization (EM) locally, and on Maximum Likelihood estimation (ML) at the master level (Algorithm 1). Figure 2 shows the graphical model of Fed-mv-PPCA.
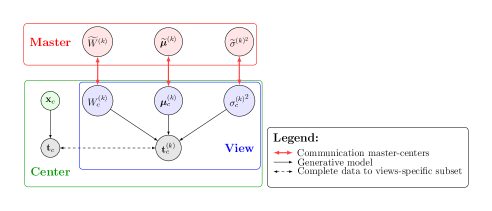
With reference to Algorithm 1, the optimization of Fed-mv-PPCA is as follows:
Optimization.
The master collects the local parameters for and estimates the ML updated global parameters characterizing the prior distributions of Equations (4) to (6). Updated global parameters are returned to each center, and serve as priors to update the MAP estimation of the local parameters , through the M step on the functional , where:
and
Initialization at round r=1.
The latent-space dimension , the number of local iterations and the number of communication rounds (i.e. number of complete cycles centers-master) are user-defined parameters. For the sake of simplicity, we set here the same number of local iterations for every center. Note that this constraint can be easily adapted to take into account systems heterogeneity among centers, as well as the size of each local dataset. At the first round, local parameters initialization, hence optimization, can be performed in two distinct ways: 1) each center can initialize randomly every local parameter, then perform EM through iterations, maximizing the functional ; 2) the master can provide priors for at least some parameters, which will be optimized using MAP estimation as described above. In case of a random initialization of local parameters, the number of EM iterations for the first round can be increased: this can be seen as an exploratory phase.
The reader can refer to Appendix A for further details on the theoretical formulation of Fed-mv-PPCA and the corresponding optimization scheme.
3.2 Fed-mv-PPCA with Differential Privacy
Despite the Bayesian federated learning scheme deployed prevents data transfer, it does not provide theoretical privacy guarantees on the shared statistics. Differential privacy (DP) (Dwork et al., 2014; Abadi et al., 2016) is a standard framework for privacy-preserving computations allowing to quantify a privacy protection budget attached to a given operation, and to sanitize model parameters through output perturbation machanisms based on the addition of a random noise. The noise strength has to be tuned to ensure a good balance between privacy and utility of the outputs.
In Section 3.2.1 we recall the standard definition of differential privacy and established results on classical random perturbation mechanisms, as well as the composition theorem (Dwork et al., 2014). A differentially private version of Fed-mv-PPCA (DP-Fed-mv-PPCA) is subsequently derived in Section 3.2.2.
3.2.1 Differential privacy: background
We denote by two datasets: and are said to be neighboring or adjacent datasets if they only differ by a datapoint , . In this case we write , where denotes the cardinality of a given set.
Definition 1
A randomized algorithm with domain and range is -differentially private if for any s.t. and for any :
When , we simply say that the algorithm is -differentially private.
A common mechanism to approximate a deterministic function or a query with differential privacy is the addition of a random noise calibrated on the sensitivity of .
Definition 2
The -sensitivity of a function is defined as:
Classical mechanisms used for perturbation are the Laplace mechanism and the Gaussian mechanism. A Laplace (resp. Gaussian) mechanism is simply obtained by computing , hence perturbing it with noise added from a Laplace (resp. Gaussian) distribution centered in the origin and with variance depending on the sensitivity of :
where (resp. ).
Hereafter we recall the condition of a Laplace (resp. Gaussian) mechanism to preserve -DP.
Theorem 3
Given any function and , the Laplace mechanism defined as
where are iid drawn from , preserves -DP.
Theorem 4
Given any function and , the Gaussian mechanism defined as
preserves -DP.
An improved Gaussian mechanism is further described by Zhao et al. (2019), with the advantages of 1) remaining valid for given , and 2) adding a smaller noise as compared to the result of Theorem 4 in the case .
Theorem 5
Given any function , , and , the Gaussian mechanism defined as
where , preserves -DP.
It is worth noting that Theorems 4 and 5 can be naturally extended to queries mapping to and matrix normal mechanisms:
Corollary 6
Given any function , , and , the matrix normal mechanism defined as
where , preserves -DP.
We conclude this section by recalling the well known composition theorem (Dwork et al., 2014), which will be useful to quantify the global privacy budget for each center in the next sections.
Theorem 7
For , let be an -differentially private algorithm, and defined as . Then is -differentially private.
3.2.2 Differential privacy for local parameters
In this section we propose a novel federated learning scheme for Fed-mv-PPCA with DP to protect client-level privacy and avoid potential private information leakage from the shared local parameters.
We are interested in preserving the privacy of the shared local parameters , which can be done by the addition of some properly tuned random noise, as detailed in Section 3.2.1. Nevertheless, the client-level optimization scheme in Fed-mv-PPCA is based on an iterative algorithm: therefore we do not have a closed formula to evaluate the sensitivity of each local parameter (i.e. the queries), nor an upper bound. To overcome this problem, we propose to perform difference clipping (Geyer et al., 2017; Zhang et al., 2021), one of the clipping strategies proposed for differentially private SGD models. Algorithm 2 outlines the optimization scheme for the DP-Fed-mv-PPCA framework.
Difference clipping and perturbation.
With respect to Algorithm 1, difference clipping and perturbation are performed at the client level compatibly with the probabilistic formulation of the model:
- 1.
The client computes the difference between the current local update and the initial prior (i.e. the corresponding global parameter obtained at the previous communication round, ):
- 2.
The updated difference is clipped according to the standard deviation of the prior:
where , and the multiplicative constant is fixed by the user. This clipping mechanism enforces the norm of to be at most . Consequently, the sensitivity of is bounded by .
- 3.
- 4.
The client adds again the prior and finally sends to the master .
Conversely to model clipping (Abadi et al., 2016; Wei et al., 2020), where the parameter update is directly clipped and perturbed, difference clipping has the advantage to allow reducing the magnitude of the perturbation: indeed, we expect the norm of the difference to be small compared to the norm of . Moreover, our framework provides a natural way to define the clipping parameter according to the prior. Indeed, the clipping parameter is defined here as the standard deviation of global parameters. Hence, from a conceptual viewpoint, we are enforcing local parameters updates to remain closer to the global ones by some ratio of their standard deviation. This allows to obfuscate the participation of the individual centers at the expense of a reduction of the ability of the framework in capturing the between-centers variability.
Privacy budget
Theorem 8
For sake of simplicity, let us choose the same for all mechanisms considered above (a generalization to a parameter-specific choice of is straightforward). The total privacy budget for the outputs of Algorithm 2 is , where is the total number of views.
Proof The proof of Theorem 8 follows from Theorems 3-5 and Corollary 6, and by noting that data in each center are disjoint. In all centers, we are dealing with the mechanism , where for all , and are -differentially private, while for all , is -differentially private. The result follows thanks to composition Theorem 7 and the invariance of differential privacy under post-processing.
Corollary 9
If for local parameter the client-specific differential parameters are , then the total privacy budget for the corresponding global parameter is bounded by .
3.3 Computational complexity and communication cost
The computational complexity of local parameters optimization in Fed-mv-PPCA (with or without the introduction of the DP mechanism depicted in Section 3.2) can be derived from the complexity of standard PPCA (Chen et al., 2009). We recall that performing simple PPCA locally in center implies a computational complexity of , where and are respectively the number of samples and dimensions in center , while is the chosen latent dimension. In the multi-view extension here considered, the total dimension is decomposed across views, meaning that , where is the set of observed views in center , and the dimension of view . The complete data log-likelihood to be maximized in the M step of the expectation-maximization algorithm, can consequently be written as a sum over the number of samples and number of observed views in center (see Section 3.1.3 and Appendix A.). For each , the computational complexity to optimize all -specific local parameters is . This finally implies a computational complexity of when .
The communication cost of both (DP-)Fed-mv-PPCA can be derived as well from the communication cost of distributed PPCA (Elgamal et al., 2015), by considering that each center will communicate to the central server the parameter set: . For every , the communication cost of is . Consequently, the global communication cost of will be , which is the same communication cost of standard PPCA for a -dimensional dataset.
4 Applications
4.1 Materials
In the preparation of this article we used two datasets.
Synthetic dataset (SD): using the generative model described in Section 3.1.2, we generated 400 observations consisting of views of dimension respectively. Each view was generated from a common 5-dimensional latent space. We randomly chose parameters . Finally, to simulate heterogeneity, a randomly chosen sub-sample composed by 250 observations was shifted in the latent space by a randomly generated vector: this allowed to simulate the existence of two distinct groups in the population.
Alzheimer’s Disease Neuroimaging Initiative dataset (ADNI)222The ADNI project was launched in 2003 as a public-private partnership, led by Principal Investigator Michael W. Weiner, MD. The primary goal of ADNI was to test whether serial magnetic resonance imaging (MRI), positron emission tomography (PET), other biological markers, and clinical and neuropsychological assessments can be combined to measure the progression of early Alzheimer’s disease (AD) (see www.adni-info.org for up-to-date information).: we consider 311 participants extracted from the ADNI dataset, among cognitively normal (NL) (104 subjects) and patients diagnosed with AD (207 subjects). All participants are associated with multiple data views: cognitive scores including MMSE, CDR-SB, ADAS-Cog-11 and RAVLT (CLINIC), Magnetic resonance imaging (MRI), Fluorodeoxyglucose-PET (FDG) and AV45-Amyloid PET (AV45) images. MRI morphometrical biomarkers were obtained as regional volumes using the cross-sectional pipeline of FreeSurfer v6.0 and the Desikan-Killiany parcellation (Fischl, 2012). Measurements from AV45-PET and FDG-PET were estimated by co-registering each modality to their respective MRI space, normalizing by the cerebellum uptake and by computing regional amyloid load and glucose hypometabolism using PetSurfer pipeline (Greve et al., 2014) and the same parcellation. Features were corrected beforehand with respect to intra-cranial volume, sex and age using a multivariate linear model. Data dimensions for each view are: , , and . Further details on the demographics of the ADNI sample are provided in Appendix B, Table 3.
4.2 Benchmark
We compare our method to two state-of-the art data assimilation methods: Variational Autoencoder (VAE) (Kingma and Welling, 2014) and multi-channel VAE (mc-VAE) (Antelmi et al., 2019). To maintain the modeling setup consistent across methods, both auto-encoders were tested by considering linear encoding and decoding mappings. In order to obtain the federated version of VAE and mc-VAE we use FedAvg (McMahan et al., 2017a), which is specifically conceived for stochastic gradient descent optimization. Additional tests were performed by considering non-linear VAEs (2-layers for both encoding and decoding architectures), and FedProx as additional regularized FL aggregation method (results in Supp. Table 7 and Supp. Figure 11). For all optimization methods and federation schemes we set to 100 the total number of communication rounds, of 15 epochs each, with the default learning rate ().
4.3 Results
We apply Fed-mv-PPCA to both SD and ADNI datasets, and quantify the quality of reconstruction and identification of the latent space with respect to the increasing number of centers, , and the increasing data heterogeneity. We investigate also the ability of Fed-mv-PPCA in estimating the data variability and predicting the distribution of missing views. To this end, we consider 4 different scenarios of data distribution across multiple centers, detailed in Table 1.
| Scenario | Description |
| IID | Data are iid distributed across centers with respect to groups and for all subjects a complete data raw is provided |
| G | Data are non-iid distributed with respect to groups across centers: centers includes subjects from both groups; centers only subjects from group 1 (AD in the ADNI case); centers only subjects from group 2 (NL for ADNI). All views have been measured in each center. |
| K | centers contribute with observations for all views; in centers the second view (MRI for ADNI) is missing; in centers the third view (FDG for ADNI) is missing. Data are iid distributed across centers with respect to groups. |
| G/K | Data are non-iid distributed (scenario G) and there are missing views (scenario K). |
For each experiment considered hereafter with Fed-mv-PPCA, we perform 3-fold Cross Validation (3CV) tests. For every test, local parameters are initialized randomly (i.e. no prior is provided by the master at the beginning), and the number of rounds is set to 100. Each round consists of 15 iterations for local MAP optimization, except the initialization round, which consists of 30 EM iterations. Finally, when a centralized setting is tested, the number of rounds is set to 1 and the number of EM iterations to 800.
4.3.1 Model selection
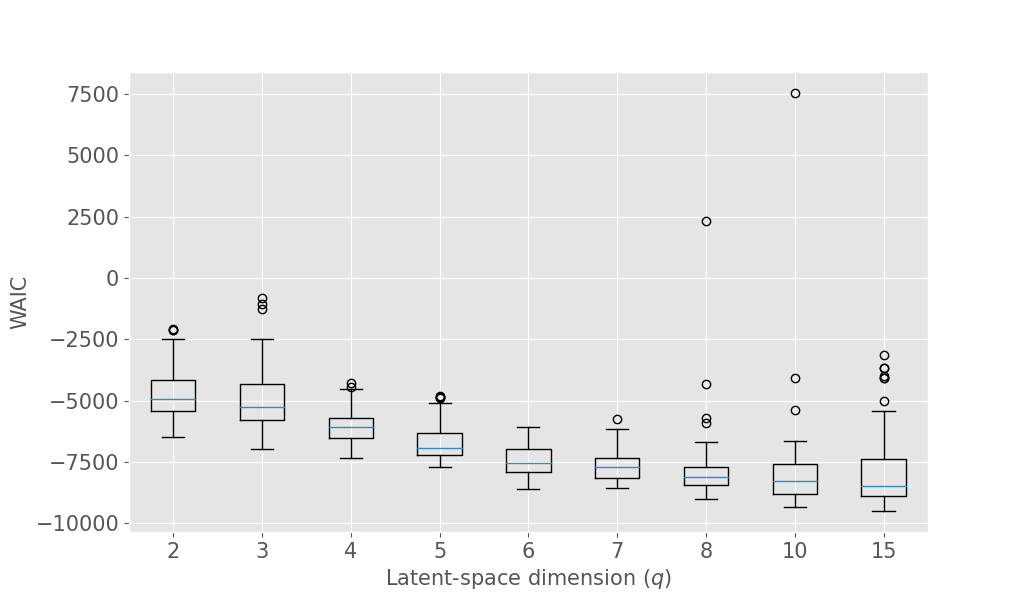
The latent space dimension is an user defined parameter, with the only constraint . To assess the optimal , we consider the IID scenario and let vary. We perform 10 times a 3-fold Cross Validation (3-CV), and split the train dataset across 3 centers. The resulting models are compared using the WAIC criterion (Gelman et al., 2014). In addition, we consider the Mean Absolute reconstruction Error (MAE) in an hold-out test dataset: the MAE is obtained by evaluating the mean absolute distance between real data and data reconstructed using the global distribution. Figure 3 shows the evolution of WAIC and MAE with respect to the latent space dimension.
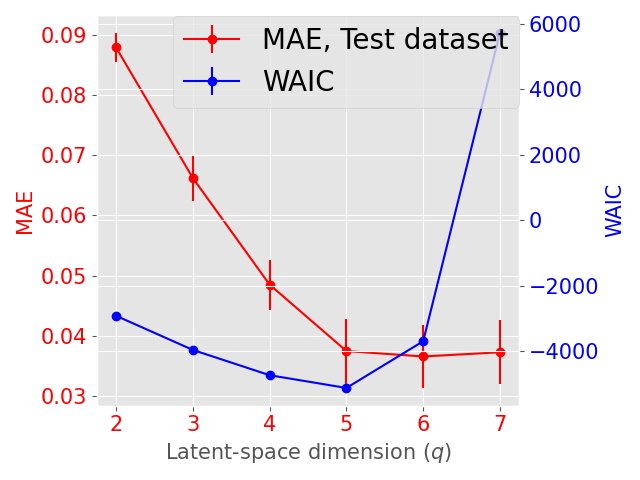
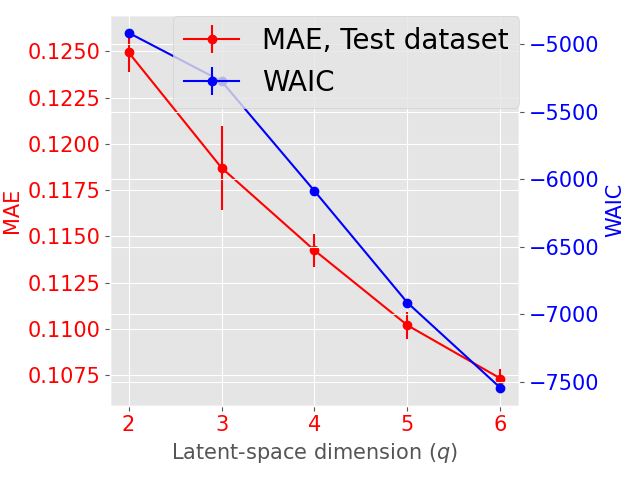
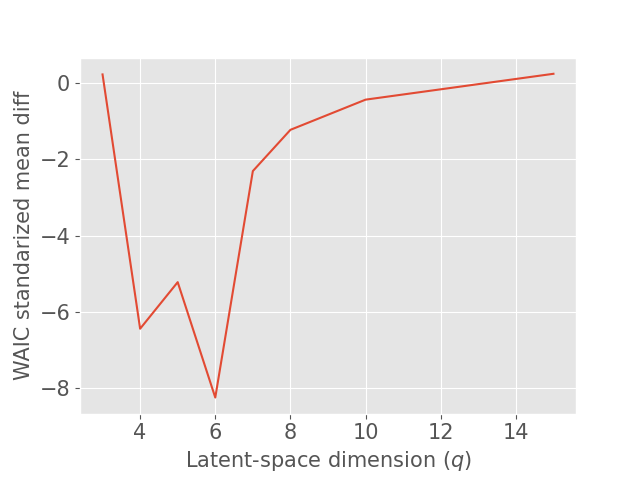
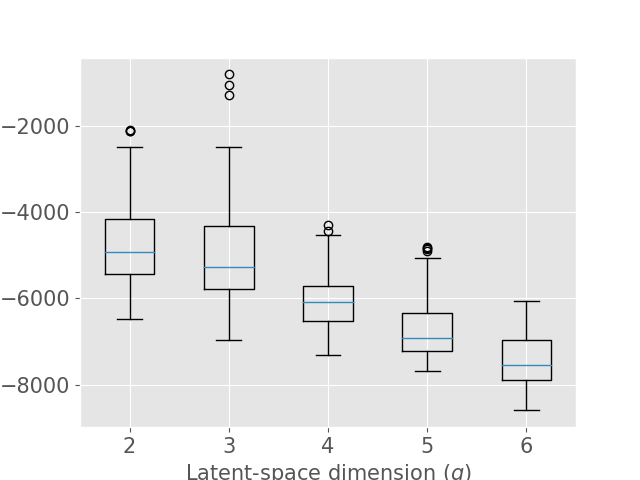
Concerning the SD dataset, the WAIC suggests latent dimensions (Figure 3 (a)), hence demonstrating the ability of Fed-mv-PPCA to correctly recover the ground truth latent space dimension used to generate the data. Analogously, the MAE improves drastically up to the dimension , and subsequently stabilizes. For ADNI, the MAE improves for increasing latent space dimensions, and we obtain the best WAIC score for . In this case, one can notice that both the WAIC and MAE keep decreasing when considering varying from 1 to 6. In Figure 4 we display the standardized mean differences of WAIC scores for : increasing the latent dimension above 6 implies a mild relative improvement of the WAIC, while requiring a computationally more complex model and higher communication costs (see Section 3.3). This ultimately indicates that the choice of is a reasonable compromise for the ADNI database, allowing to efficiently capture most data variability, while remaining coherent with the model hypotheses (cf ). Additionally, we should stress that when the -th view dimension is smaller or equal to the latent dimension ( for some ), we assumed that only the first columns of were effectively contributing for the latent projection of view , and we forced the remaining columns of to be filled of zeros. For completeness, Supplementary Figure 9 provides the evolution of WAIC for and shows that a latent dimension choice above is associated to a generally higher variance, suggesting less stable models and results.
It is worth noting that despite the agreement of MAE and WAIC for both datasets, the WAIC has the competitive advantage of providing a natural and automatic model selection measure in Bayesian models, which does not require testing data, conversely to MAE.
In the following experiments, we set the latent space dimension for the SD dataset and for the ADNI dataset.
4.3.2 Increasing heterogeneity across datasets
| Scenario | Centers | Method | MAE Train | MAE Test | Accuracy in LS |
| IID | 1(centralizedcase) | Fed-mv-PPCA | 0.08050.0003 | 0.11100.0011 | 0.86800.0379 |
| VAE | 0.10550.0017 | 0.13440.0019 | 0.80030.0409 | ||
| mc-VAE | 0.13820.0009 | 0.16690.0020 | 0.87270.0319 | ||
| 3 | Fed-mv-PPCA | 0.10270.0015 | 0.10730.0004 | 0.86520.0270 | |
| DP-Fed-mv-PPCA | 0.13040.0047 | 0.13040.0041 | 0.83210.0388 | ||
| VAE | 0.11720.0022 | 0.11920.0015 | 0.82890.0383 | ||
| mc-VAE | 0.16020.0035 | 0.15670.0017 | 0.88500.0262 | ||
| 6 | Fed-mv-PPCA | 0.12030.0042 | 0.10740.0007 | 0.87420.0267 | |
| DP-Fed-mv-PPCA | 0.14890.0051 | 0.12950.0029 | 0.85020.0347 | ||
| VAE | 0.13570.0042 | 0.11910.0014 | 0.82240.0377 | ||
| mc-VAE | 0.18400.0054 | 0.15630.0017 | 0.88940.0230 | ||
| G | 3 | Fed-mv-PPCA | 0.10770.0090 | 0.10960.0011 | 0.84090.0293 |
| DP-Fed-mv-PPCA | 0.13620.0117 | 0.13400.0067 | 0.79770.0480 | ||
| VAE | 0.12120.0077 | 0.12190.0015 | 0.79620.0440 | ||
| mc-VAE | 0.16770.0156 | 0.16110.0025 | 0.82100.0464 | ||
| 6 | Fed-mv-PPCA | 0.12640.0126 | 0.109120.0011 | 0.81680.0324 | |
| DP-Fed-mv-PPCA | 0.15850.0158 | 0.13400.0065 | 0.78980.0407 | ||
| VAE | 0.14010.0114 | 0.12020.0016 | 0.78820.0534 | ||
| mc-VAE | 0.19240.0219 | 0.15890.0018 | 0.80850.0464 | ||
| K | 3 | Fed-mv-PPCA | 0.09510.0086 | 0.12120.0109 | 0.86240.0303 |
| DP-Fed-mv-PPCA | 0.12080.0081 | 0.14620.0092 | 0.83570.0329 | ||
| 6 | Fed-mv-PPCA | 0.11070.0106 | 0.12930.0162 | 0.87200.0308 | |
| DP-Fed-mv-PPCA | 0.14340.0099 | 0.16040.0164 | 0.85150.0375 | ||
| G/K | 3 | Fed-mv-PPCA | 0.09950.0029 | 0.12710.0087 | 0.73380.0308 |
| DP-Fed-mv-PPCA | 0.12870.0081 | 0.15470.0125 | 0.71640.0474 | ||
| 6 | Fed-mv-PPCA | 0.11730.0061 | 0.12680.0088 | 0.74690.0202 | |
| DP-Fed-mv-PPCA | 0.14630.0088 | 0.15230.0104 | 0.71740.0387 |
To test the robustness of Fed-mv-PPCA’s results, for each scenario of Table 1, we perform 10 times 3-CV to obtain train and test datasets, hence we split the train dataset across centers. We compare our method to VAE and mc-VAE, using the same partition of train and test datasets for CV. For all methods we consider the MAE in both the train and test datasets, as well as the accuracy score in the Latent Space (LS) discriminating the groups (synthetically defined in SD or corresponding to the clinical diagnosis in ADNI). The classification was performed via Linear Discriminant Analysis (LDA) on the individual projection of test data in the latent space.
In what follows we present a detailed description of results corresponding to the ADNI dataset. Results for the SD dataset are in line with what we observe for ADNI (see Supplementary Table 6 in Appendix B), and confirm that our method outperforms both VAE and mc-VAE in reconstruction in all scenarios. In addition, Fed-mv-PPCA outperforms in discrimination both methods in the non-iid setting, while mc-VAE shows slightly improved discriminating ability in the IID scenario.
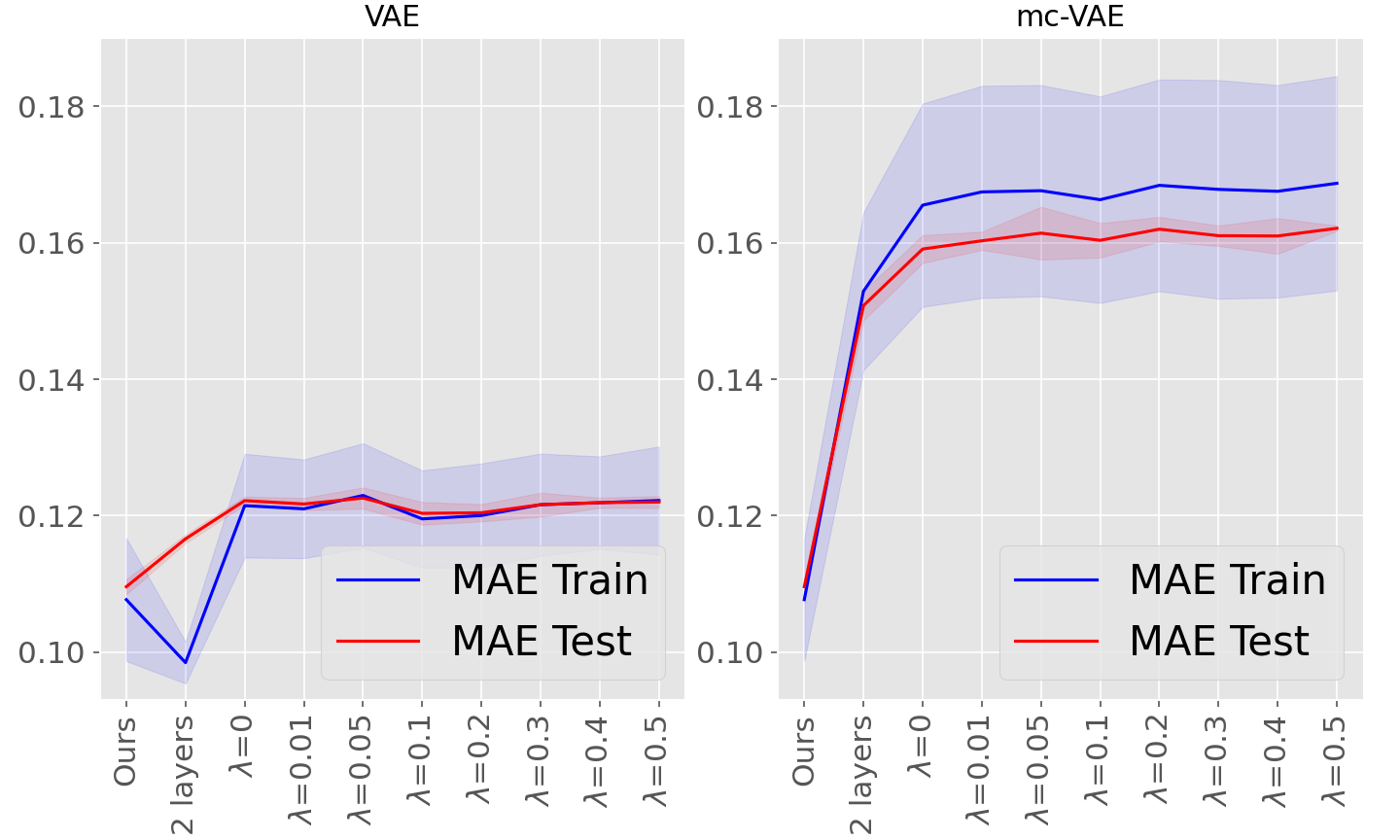
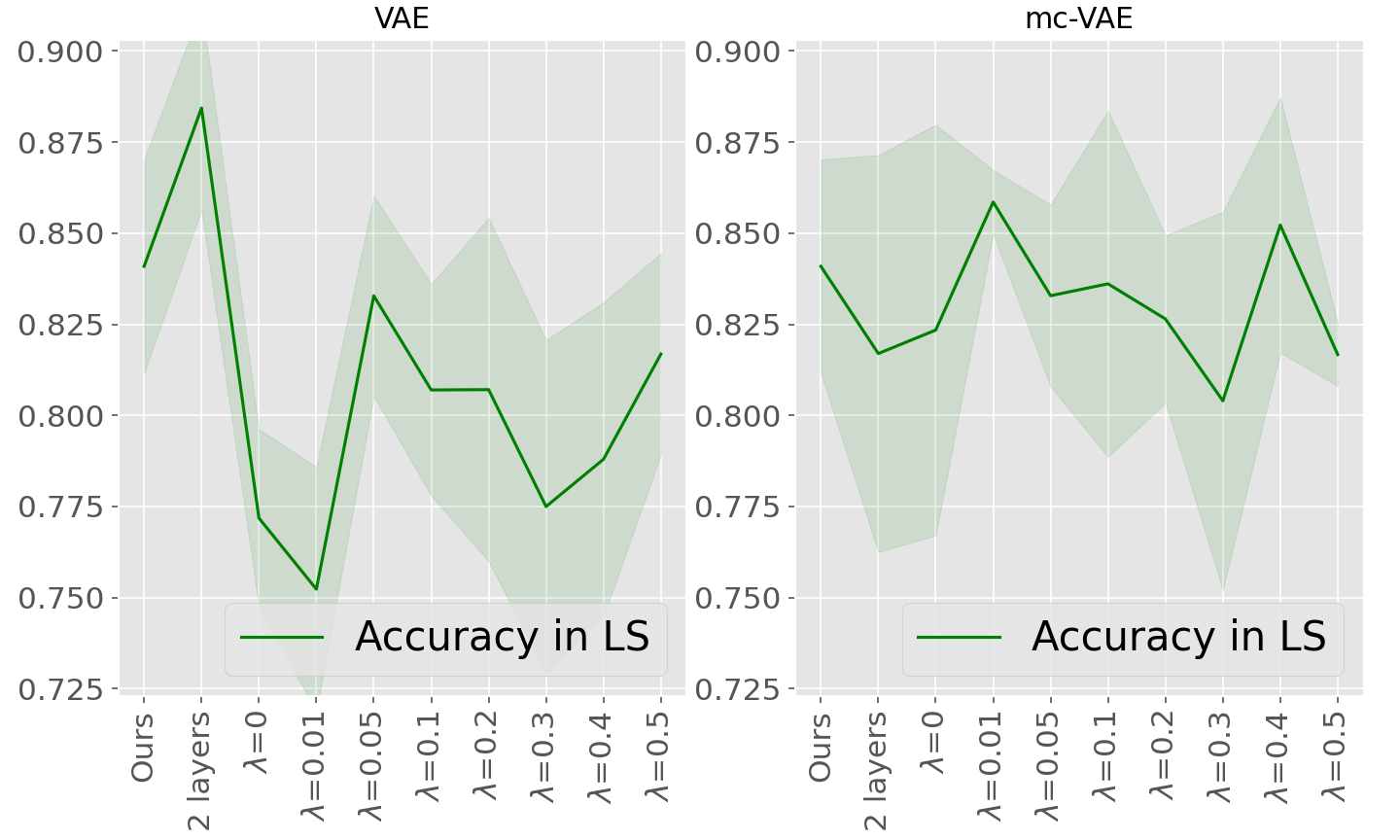
Moreover, for the sake of completeness, supplementary Table 7 and supplementary Figure 11 provide results for both VAE and mc-VAE with two layers, as well as both methods with one layer and using FedProx as robust aggregation scheme with the proximal term varying from 0.01 to 0.5: this method aims at improving convergence in case of heterogeneous data distributions. No significant improvement as been observed comparing to the FedAvg scheme for the considered datasets and settings, while non linear models are associated with a negligible improvement in testing compared to the linear variational autoencoders.
IID distribution.
We consider the IID scenario and split the train dataset across 1 to 6 centers. Table 2 shows that results from Fed-mv-PPCA are stable when moving from a centralized to a federated setting, and when considering an increasing number of centers . We only observe a degradation of the MAE in the train dataset, but this does not affect the performance of Fed-mv-PPCA in reconstructing the test data. Moreover, irrespectively from the number of training centers, Fed-mv-PPCA outperforms VAE and mc-VAE in reconstruction.
Heterogeneous distribution.
We simulate an increasing degree of heterogeneity in 3 to 6 local datasets, to further challenge the models in properly recovering the global data. In particular, we consider both a non-iid distribution of subjects across centers, and missing views in some local dataset. It is worth noting that scenarios implying datasets with missing views cannot be handled by VAE nor by mc-VAE, hence in these cases we reported only results obtained with our method.
In Table 2 we report the average MAEs and Accuracy in the latent space for each scenario, obtained over 10 tests for the ADNI dataset. Fed-mv-PPCA is robust despite an increasing degree of heterogeneity in the local datasests. We observe a slight deterioration of the MAE in the test dataset in the more challenging non-iid cases (scenarios K and G/K), while we note a drop of the classification accuracy in the most heterogeneous setup (G/K). Nevertheless, Fed-mv-PPCA demostrates to be more stable and to perform better than VAE and mc-VAE when statistical heterogeneity is introduced.
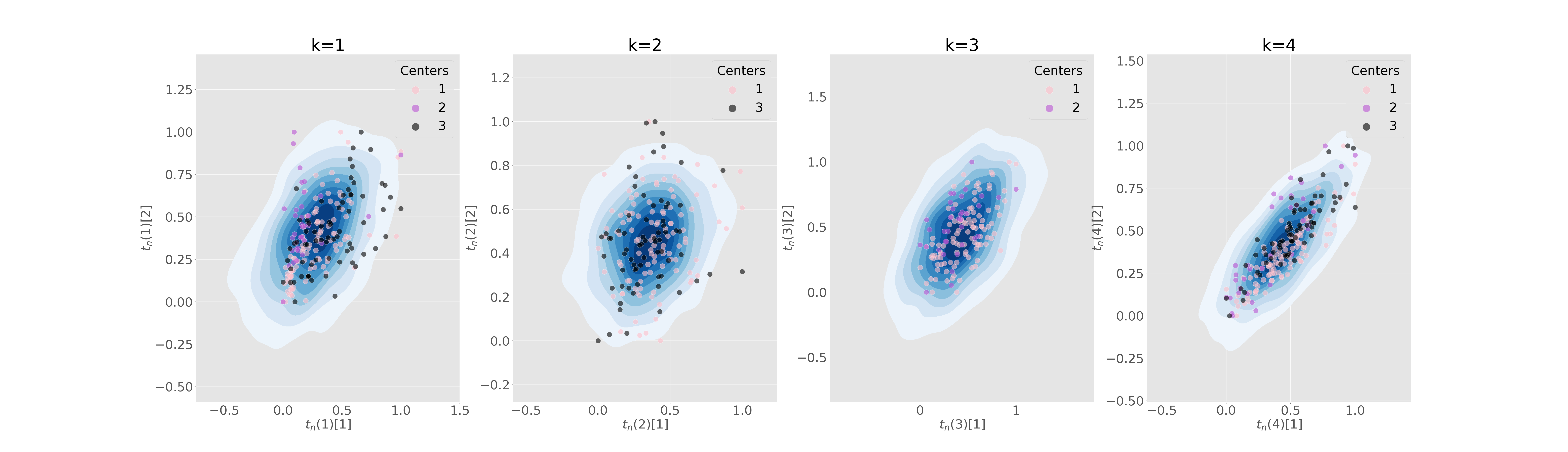
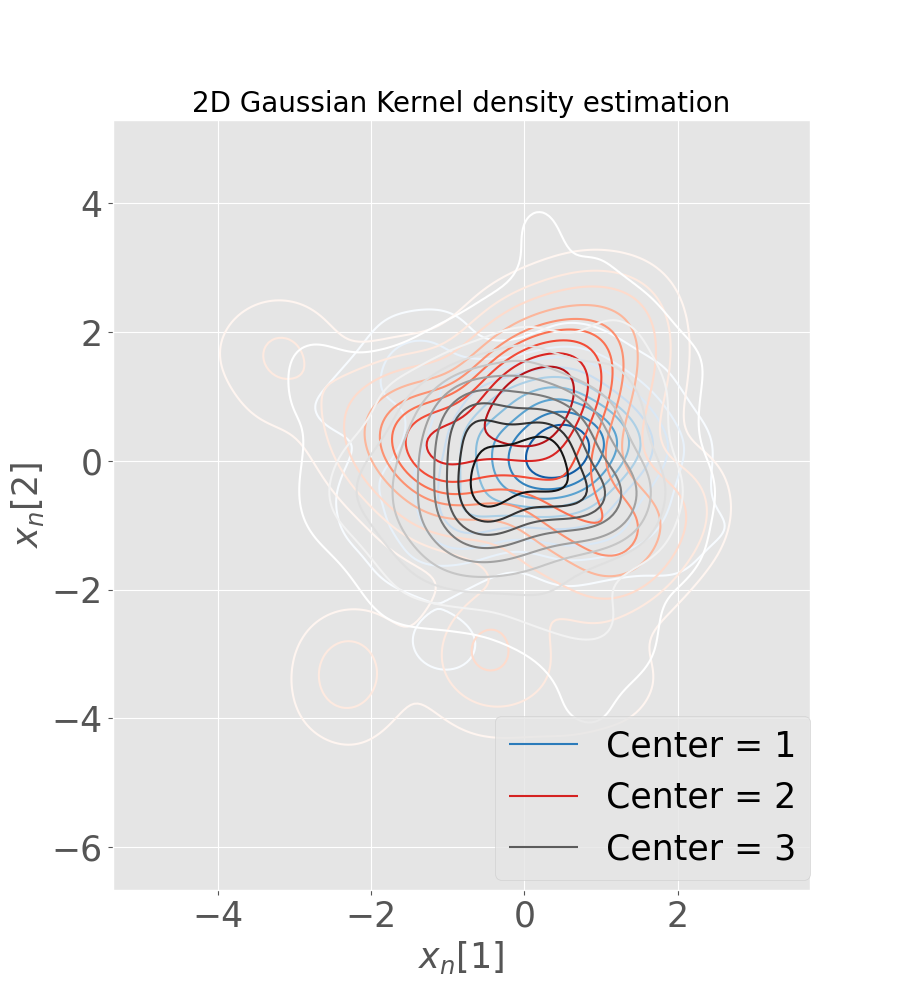
Figure 5 (a) shows the sampling posterior distribution of the latent variables, while in Figure 5 (b) we plot the predicted global distribution against observations, for the G/K scenario and considering 3 training centers. We notice that the variability of centers is well captured, in spite of the heterogeneity of the distribution in the latent space. In particular center 2 and center 3 have two clearly distinct means: this is due to the fact that subjects in these centers belong to two distinct groups (AD in center 2 and NL in center 3). Despite this, Fed-mv-PPCA is able to reconstruct correctly all views, even if 2 views are completely missing in some local datasets (MRI is missing in center 2 and FDG in center 3).
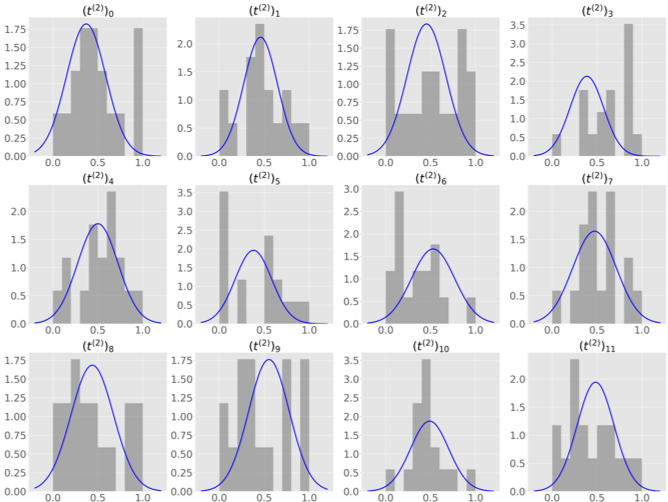
After convergence of Fed-mv-PPCA, each center is supplied with global distributions for each parameter: data corresponding to each view can therefore be simulated, even if some are missing in the local dataset. Considering the same simulation in the challenging G/K scenario, in Figure 5 (c) we plot the global distribution of some randomly selected features of a missing imaging view in the test center, against ground truth density histogram, from the original data. The global distribution provides an accurate description of the missing MRI view. Supplementary Figure 8 shows imputation for all features of the missing MRI and FDG views.
4.3.3 Differentially private Fed-mv-PPCA
We repeated all experiments described in Section 4.3.2, using Fed-mv-PPCA with differential privacy. For each parameter we set , , except when stated otherwise. Finally, to perform difference clipping (Algorithm 2), we set the maximal norm of the difference between the updated parameter at round and the prior, , to be .
DP parameters utility.
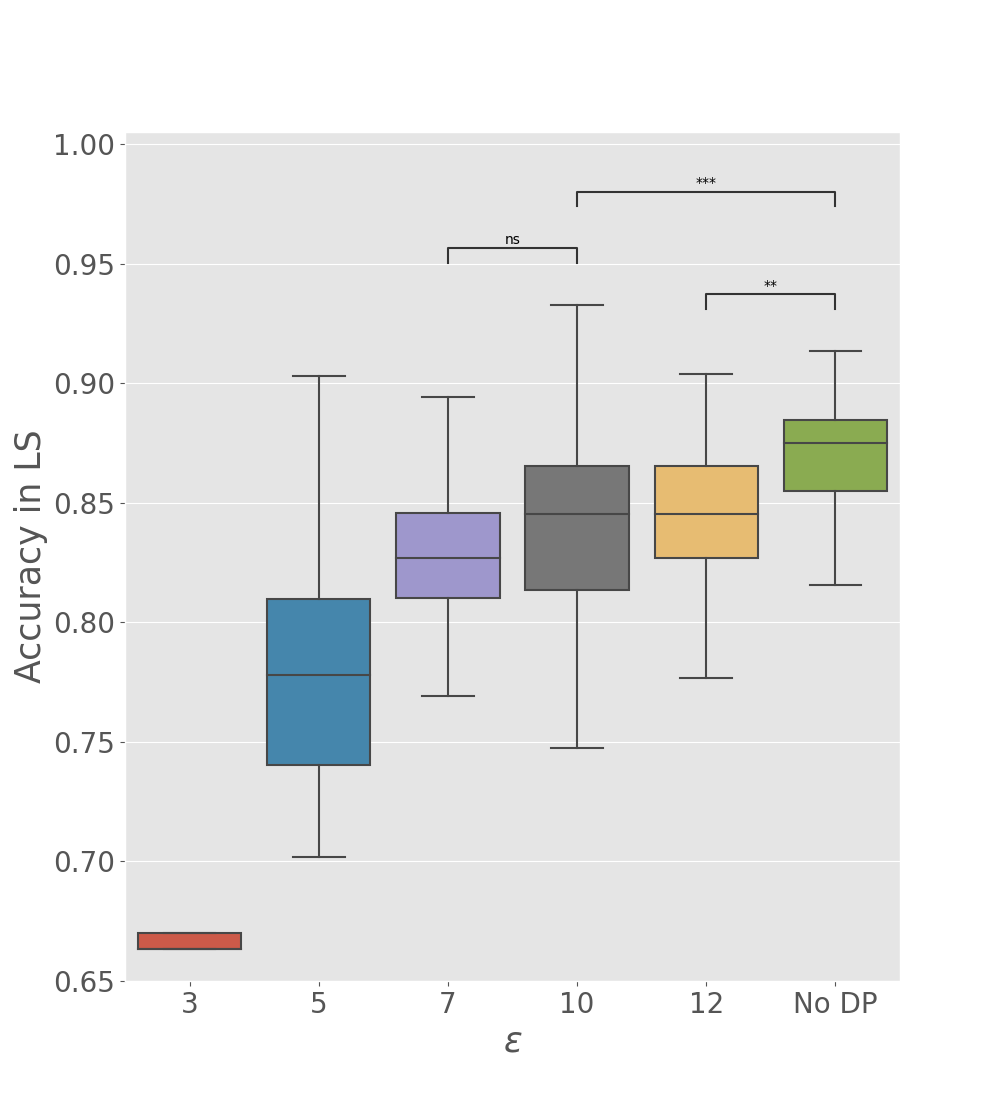
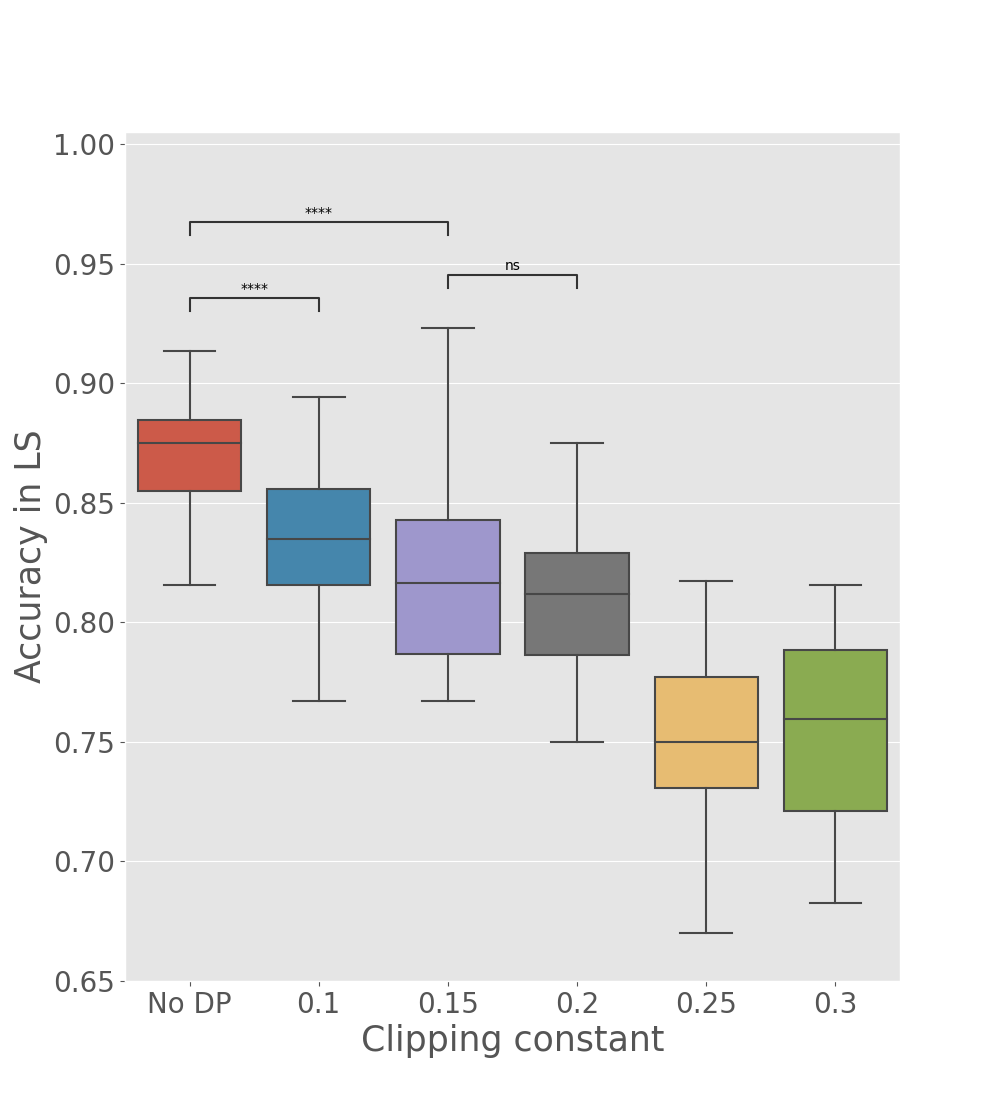
We tested the utility of global parameters obtained with the differentially private Algorithm 2, to appreciate if data reconstruction and accuracy in the latent space are well preserved when the perturbation is performed at the client level (see Table 2, DP-Fed-mv-PPCA rows). As expected, we observe a deterioration of previous results, which increases with the number of training centers, due to the communication of a larger number of perturbed parameters. Nevertheless, results remain still coherent, and illustrate the utility of the differentially private global parameters. In particular Figure 6 shows how and the multiplicative constant used for difference clipping affect the ability of the optimzed DP global parameters in preserving a meaningful separation of subjects by diagnosis in the test set. For instance, we note that when are fixed to , the clipping constant should be at most 0.2 to preserve a reasonable utility of the model outputs, in comparison to the one obtained using Fed-mv-PPCA (reported in Figure 6, not DP column). This further stresses the need of carefully tuning these DP parameters to ensure a good balance between privacy and utility.
Evolution of the standard deviation of global parameters and convergence.
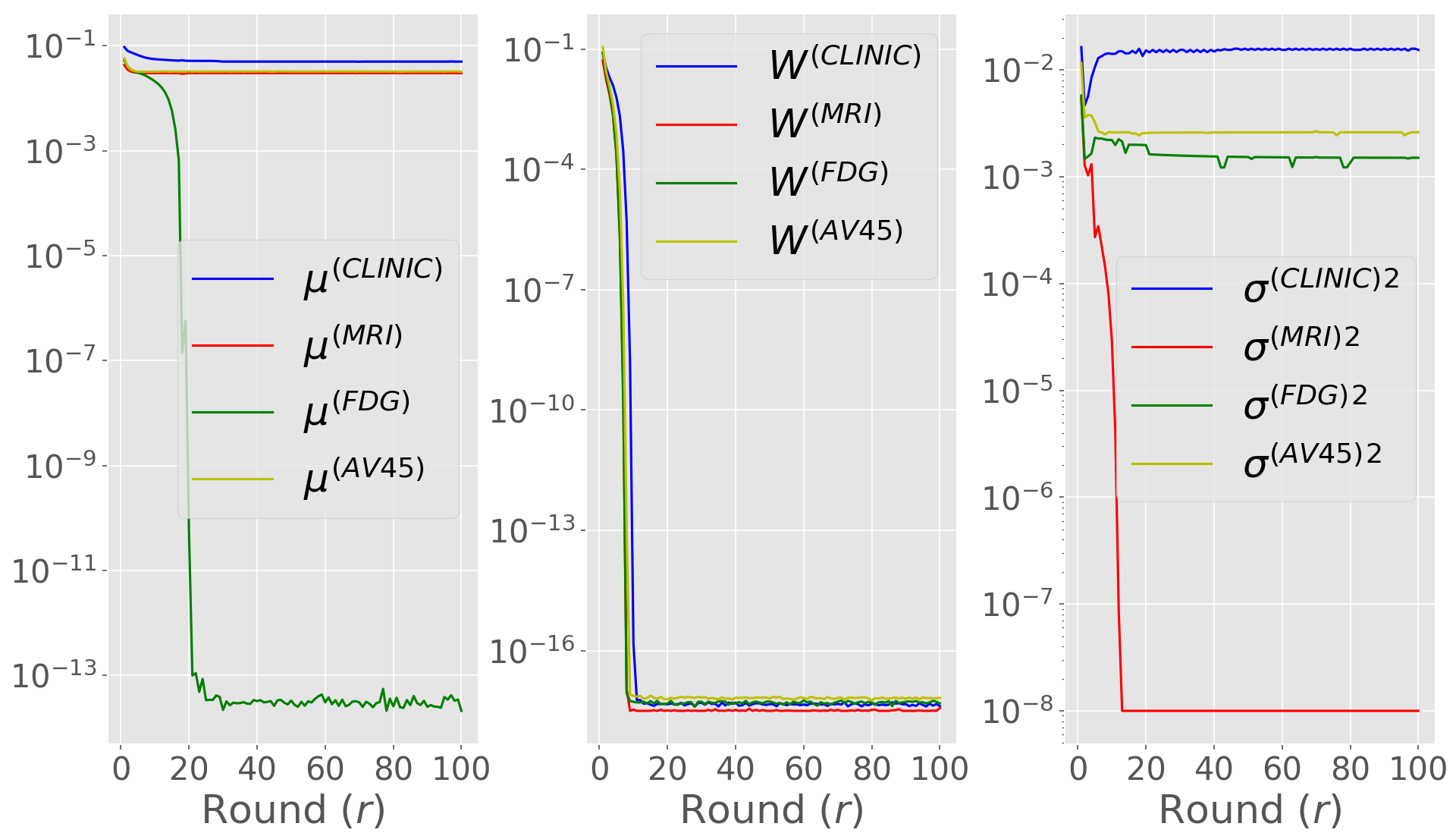
To better understand the effect of performing difference clipping with respect to the priors, in Figure 7 (a-b) we plot the median evolution of the estimated standard deviation for each global parameter during training in the G/K scenario, comparing Fed-mv-PPCA and DP-Fed-mv-PPCA. When DP is not introduced, we can see that all global parameters’ standard deviations converge, as expected, indicating harmonization of local parameters during training. In particular, it is worth noticing that the clinical view displays higher variability for both intercept and noise parameters. Indeed, the clinical view is the most discriminant one between healthy and Alzheimer patients, and results plotted in Figure 7 are obtained under a non-iid scenario. Furthermore, one can notice the low magnitude of the standard deviations for and : this may be explained by the fact that there are less centers contributing to the estimation of both FDG- and MRI-specific parameters, since in the G/K scenario the FDG and MRI views are missing in some centers. On the other hand, when differential privacy is introduced we tend to loose information concerning variability of global parameters: in this case all standard deviations drop towards 0 after approximately 20 communication rounds, meaning that the final global parameters distributions are strongly concentrated around their mean.
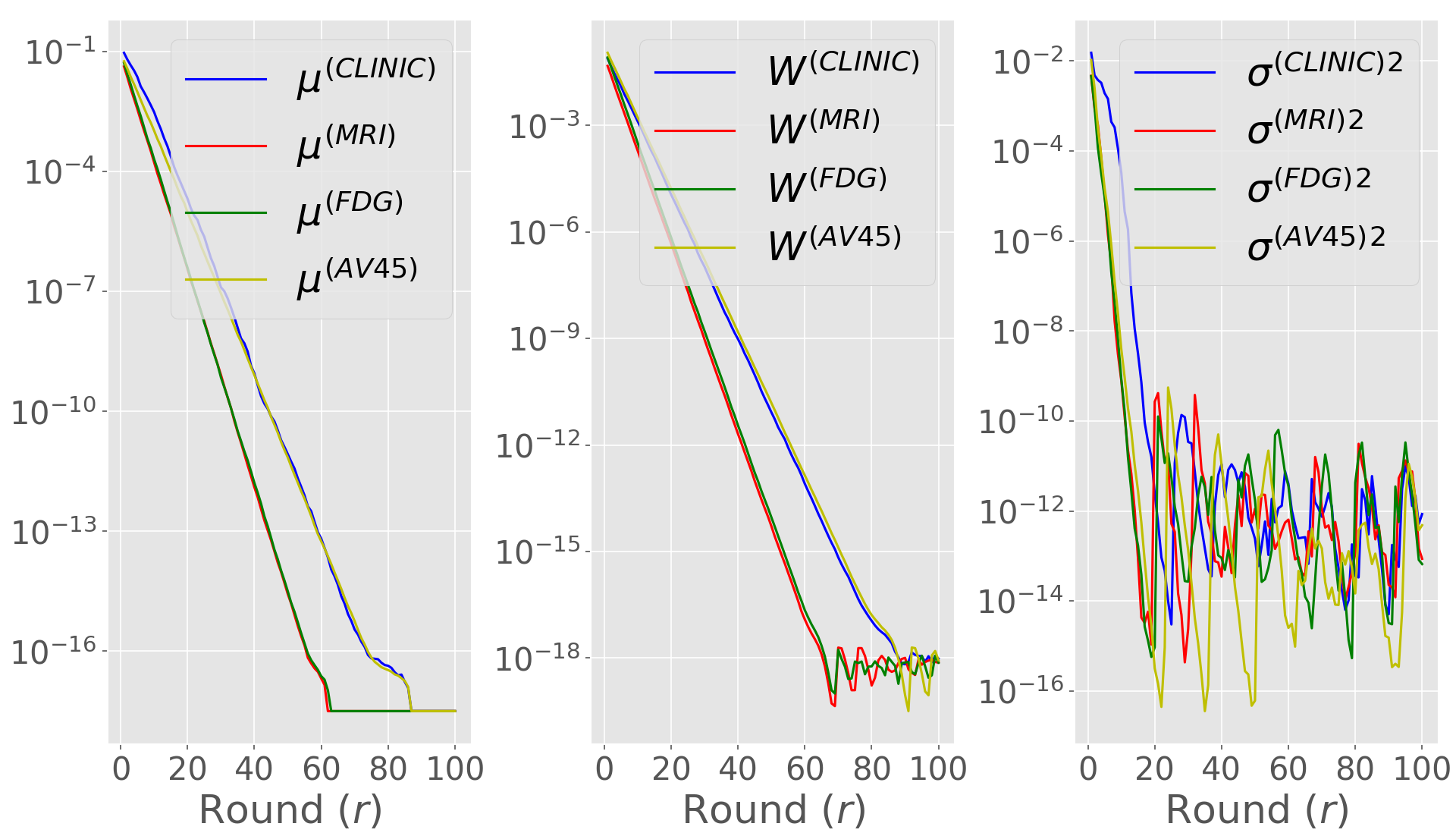
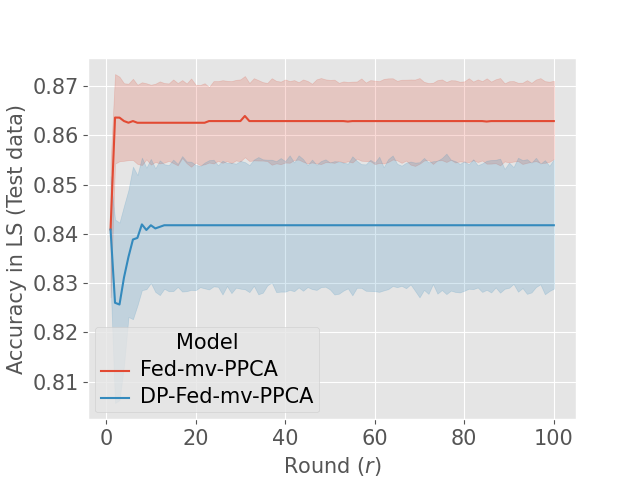
Finally, we empirically investigate the convergence of DP-Fed-mv-PPCA. The convergence of the EM algorithm for PPCA has already been commented by Tipping and Bishop (1999). Nevertheless, in the case of DP-Fed-mv-PPCA, local parameters updates are performed using priors estimated at the master level from perturbed previous local updates. In addition, as commented above, the standard deviations of global parameters used as priors tend to decrease rapidly due to the clipping mechanism. Consequently, priors provided to the centers will be increasingly informative, affecting the algorithm convergence. Figure 7 (c) shows the mean evolution of the accuracy in the latent space (and for the test dataset) during successive rounds of both Fed-mv-PPCA and DP-Fed-mv-PPCA: mean and standard deviation are obtained by repeating 10 times a 3-CV test. Although the convergence of the algorithm seems to be reached in both cases, DP-Fed-mv-PPCA optimized parameters are clearly sub-optimal. Moreover, we notice a higher variability of the accuracy metric, as a consequence of the random perturbation performed over local parameters, which in turns affects the priors. Further insights are provided in Supp. Figure 10, showing the estimated global variance of the Gaussian noise, which is greater when using DP-Fed-mv-PPCA compared to Fed-mv-PPCA, indicating an estimated higher variability in the global dataset (i.e. the ensemble of the local datasets). This is an expected consequence of the perturbation mechanism, which necessary affects the global model’s performance.
5 Conclusions
In spite of the large amount of currently available multi-site biomedical data, we still lack of reliable analysis methods to be applied in multi-centric applications in compliance with privacy. To tackle this challenge, Fed-mv-PPCA proposes a hierarchical generative model to perform data assimilation of federated heterogeneous multi-views data. The Bayesian approach allows to naturally handle statistical heterogeneity across centers and missing views in local datasets, to provide an interpretable model of data variability and a valuable tool for missing data imputation. We show that Fed-mv-PPCA can be further coupled with differential privacy. Compatibly with our Bayesian formulation, we provide formal privacy guarantees of the proposed federated learning scheme against potential private information leakage from the shared statistics.
Our applications demonstrate that Fed-mv-PPCA is robust with respect to an increasing degree of heterogeneity across training centers, and provides high-quality data reconstruction, outperforming competitive methods in all scenarios. Moreover, when differential privacy is introduced, we provide an investigation of the method’s performance according to different privacy budget scenarios. It is worth noting that three DP hyperparameters play a key role, and could affect the performance of DP-Fed-mv-PPCA: the privacy budget parameters , and the clipping constant multiplying . These parameters are tightly related and all contribute to determine the magnitude of the noise used for perturbing the updated difference . Indeed, increasing either or , or reducing the multiplicative constant in the clipping mechanism, implies the addition of a smaller noise, hence the improvement of the overall utility of the global model. Nevertheless, smaller and corresponds to higher privacy guarantees.
Further extensions of this work are possible in several directions. The computational efficiency of Fed-mv-PPCA and its scalability to large datasets can be improved by leveraging on data sparsity and optimizing matrix multiplications and norm calculations as showed by Elgamal et al. (2015). In addition, introducing sparsity on the reconstruction weights is also expected to improve the robustness of the approach to non-informative dimensions and modalities. Another interesting research direction concerns the handling of missing data. Indeed, in this paper we considered Missing At Random (MAR) views in local datasets due to heterogeneous pipelines (Rubin, 1976). Fed-mv-PPCA could be extended to take into account and impute Missing Not At Random (MNAR) data as well, covering for instance the case of missing data due to self censoring, of interest in the biomedical context.
In this work we adopted DP to increase our framework’s security, motivated by the need to derive explicit theoretical privacy guarantees for our model. Alternatively, some recent works propose to improve data privacy (and eventually model utility) in a federated setting by generating fake data through generative adversarial networks (Rajotte et al., 2021; Rasouli et al., 2020). Despite formal privacy guarantees cannot be provided by data augmentation methods, their comparison to DP is a problem of great interest and should be further investigated.
In addition, we provided an experimental analysis of the convergence properties of DP in the proposed setting. In the future, formal convergence guarantees could be investigated, for example for the general optimization setting associating DP to EM. Furthermore, adaptive clipping strategies (Andrew et al., 2019) could be investigated and employed to improve the convergence of DP-Fed-mv-PPCA and the final utility of global parameters. Finally, in order to improve the robustness of DP-Fed-mv-PPCA, non-Gaussian data likelihood and priors could be introduced in the future, to better account for heavy-tailed distributions defined by outliers datasets and centers.
Acknowledgments
This work received financial support by the French government, through the 3IA Côte d’Azur Investments in the Future project managed by the National Research Agency (ANR) with the reference number ANR-19-P3IA-0002, and by the ANR JCJC project Fed-BioMed, ref. num. 19-CE45-0006-01. The authors are grateful to the OPAL infrastructure from Université Côte d’Azur for providing resources and support.
Data collection and sharing for this project was funded by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol-Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; ElanPharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research Development, LLC.; Johnson Johnson Pharmaceutical Research Development LLC.; Lumosity; Lundbeck; Merck Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; andTransition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for NeuroImaging at the University of SouthernCalifornia.
Ethical Standards
The work follows appropriate ethical standards in conducting research and writing the manuscript, following all applicable laws and regulations regarding treatment of animals or human subjects.
Conflicts of Interest
The authors declare that they have no conflict of interests.
References
- Abadi et al. (2016) Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security, pages 308–318, 2016.
- Andrew et al. (2019) Galen Andrew, Om Thakkar, H Brendan McMahan, and Swaroop Ramaswamy. Differentially private learning with adaptive clipping. arXiv preprint arXiv:1905.03871, 2019.
- Antelmi et al. (2019) Luigi Antelmi, Nicholas Ayache, Philippe Robert, and Marco Lorenzi. Sparse multi-channel variational autoencoder for the joint analysis of heterogeneous data. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 302–311. PMLR, 2019. URL http://proceedings.mlr.press/v97/antelmi19a.html.
- Argelaguet et al. (2018) R. Argelaguet, B. Velten, D. Arnol, S. Dietrich, T. Zenz, J. C. Marioni, F. Buettner, W. Huber, and O. Stegle. Multi-omics factor analysis-a framework for unsupervised integration of multi-omics data sets. Mol Syst Biol, 14(6):e8124, 2018.
- Banerjee et al. (2017) Monami Banerjee, Bing Jian, and Baba C Vemuri. Robust fréchet mean and pga on riemannian manifolds with applications to neuroimaging. In International Conference on Information Processing in Medical Imaging, pages 3–15. Springer, 2017.
- Chassang (2017) Gauthier Chassang. The impact of the eu general data protection regulation on scientific research. ecancermedicalscience, 11, 2017.
- Chen et al. (2009) Tao Chen, Elaine Martin, and Gary Montague. Robust probabilistic pca with missing data and contribution analysis for outlier detection. Computational Statistics & Data Analysis, 53(10):3706–3716, 2009.
- Cunningham and Ghahramani (2015) John P Cunningham and Zoubin Ghahramani. Linear dimensionality reduction: Survey, insights, and generalizations. The Journal of Machine Learning Research, 16(1):2859–2900, 2015.
- Dwork et al. (2014) Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science, 9(3-4):211–407, 2014.
- Elgamal et al. (2015) Tarek Elgamal, Maysam Yabandeh, Ashraf Aboulnaga, Waleed Mustafa, and Mohamed Hefeeda. spca: Scalable principal component analysis for big data on distributed platforms. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, pages 79–91, 2015.
- Fischl (2012) Bruce Fischl. Freesurfer. Neuroimage, 62(2):774–781, 2012.
- Fletcher and Zhang (2016) P Thomas Fletcher and Miaomiao Zhang. Probabilistic geodesic models for regression and dimensionality reduction on riemannian manifolds. In Riemannian Computing in Computer Vision, pages 101–121. Springer, 2016.
- Fredrikson et al. (2015) Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, pages 1322–1333, 2015.
- Gelman et al. (2014) Andrew Gelman, Jessica Hwang, and Aki Vehtari. Understanding predictive information criteria for bayesian models. Statistics and computing, 24(6):997–1016, 2014.
- Geyer et al. (2017) Robin C Geyer, Tassilo Klein, and Moin Nabi. Differentially private federated learning: A client level perspective. arXiv preprint arXiv:1712.07557, 2017.
- Goodfellow et al. (2016) Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep learning. MIT press, 2016.
- Greve et al. (2014) Douglas N Greve, Claus Svarer, Patrick M Fisher, Ling Feng, Adam E Hansen, William Baare, Bruce Rosen, Bruce Fischl, and Gitte M Knudsen. Cortical surface-based analysis reduces bias and variance in kinetic modeling of brain pet data. Neuroimage, 92:225–236, 2014.
- Hromatka et al. (2015) Michelle Hromatka, Miaomiao Zhang, Greg M Fleishman, Boris Gutman, Neda Jahanshad, Paul Thompson, and P Thomas Fletcher. A hierarchical bayesian model for multi-site diffeomorphic image atlases. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 372–379. Springer, 2015.
- Iyengar et al. (2018) Arun Iyengar, Ashish Kundu, and George Pallis. Healthcare informatics and privacy. IEEE Internet Computing, 22(2):29–31, 2018.
- Jolliffe (1986) Ian T Jolliffe. Principal components in regression analysis. In Principal component analysis, pages 129–155. Springer, 1986.
- Kalter et al. (2019) Joeri Kalter, Maike G Sweegers, Irma M Verdonck-de Leeuw, Johannes Brug, and Laurien M Buffart. Development and use of a flexible data harmonization platform to facilitate the harmonization of individual patient data for meta-analyses. BMC research notes, 12(1):164, 2019.
- Kingma and Welling (2014) Diederik P Kingma and Max Welling. Stochastic gradient vb and the variational auto-encoder. In Second International Conference on Learning Representations, ICLR, volume 19, 2014.
- Kingma and Welling (2019) Diederik P Kingma and Max Welling. An introduction to variational autoencoders. Foundations and Trends in Machine Learning, 12(4):307–392, 2019.
- Klami et al. (2013) Arto Klami, Seppo Virtanen, and Samuel Kaski. Bayesian canonical correlation analysis. Journal of Machine Learning Research, 14(Apr):965–1003, 2013.
- Kramer (1991) Mark A Kramer. Nonlinear principal component analysis using autoassociative neural networks. AIChE journal, 37(2):233–243, 1991.
- Li et al. (2018) Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks. arXiv preprint arXiv:1812.06127, 2018.
- Li et al. (2020) Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine, 37(3):50–60, 2020.
- Liang et al. (2020) Paul Pu Liang, Terrance Liu, Liu Ziyin, Nicholas B Allen, Randy P Auerbach, David Brent, Ruslan Salakhutdinov, and Louis-Philippe Morency. Think locally, act globally: Federated learning with local and global representations. arXiv preprint arXiv:2001.01523, 2020.
- Llera and Beckmann (2016) A Llera and CF Beckmann. Estimating an inverse gamma distribution. arXiv preprint arXiv:1605.01019, 2016.
- Matsuura et al. (2018) Toshihiko Matsuura, Kuniaki Saito, Yoshitaka Ushiku, and Tatsuya Harada. Generalized bayesian canonical correlation analysis with missing modalities. In Proceedings of the European Conference on Computer Vision (ECCV), pages 0–0, 2018.
- McMahan et al. (2017a) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics, pages 1273–1282. PMLR, 2017a.
- McMahan et al. (2017b) H Brendan McMahan, Daniel Ramage, Kunal Talwar, and Li Zhang. Learning differentially private recurrent language models. arXiv preprint arXiv:1710.06963, 2017b.
- Rajotte et al. (2021) Jean-Francois Rajotte, Sumit Mukherjee, Caleb Robinson, Anthony Ortiz, Christopher West, Juan Lavista Ferres, and Raymond T Ng. Reducing bias and increasing utility by federated generative modeling of medical images using a centralized adversary. arXiv preprint arXiv:2101.07235, 2021.
- Rasouli et al. (2020) Mohammad Rasouli, Tao Sun, and Ram Rajagopal. Fedgan: Federated generative adversarial networks for distributed data. arXiv preprint arXiv:2006.07228, 2020.
- Rubin (1976) Donald B Rubin. Inference and missing data. Biometrika, 63(3):581–592, 1976.
- Sattler et al. (2019) Felix Sattler, Simon Wiedemann, Klaus-Robert Müller, and Wojciech Samek. Robust and communication-efficient federated learning from non-iid data. IEEE transactions on neural networks and learning systems, 31(9):3400–3413, 2019.
- Shen and Thompson (2019) Li Shen and Paul M Thompson. Brain imaging genomics: Integrated analysis and machine learning. Proceedings of the IEEE, 108(1):125–162, 2019.
- Sommer et al. (2010) Stefan Sommer, François Lauze, Søren Hauberg, and Mads Nielsen. Manifold valued statistics, exact principal geodesic analysis and the effect of linear approximations. In European conference on computer vision, pages 43–56. Springer, 2010.
- Tipping and Bishop (1999) Michael E Tipping and Christopher M Bishop. Probabilistic principal component analysis. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61(3):611–622, 1999.
- Triastcyn and Faltings (2019) Aleksei Triastcyn and Boi Faltings. Federated learning with bayesian differential privacy. In 2019 IEEE International Conference on Big Data (Big Data), pages 2587–2596. IEEE, 2019.
- Wei et al. (2020) Kang Wei, Jun Li, Ming Ding, Chuan Ma, Howard H Yang, Farhad Farokhi, Shi Jin, Tony QS Quek, and H Vincent Poor. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Transactions on Information Forensics and Security, 15:3454–3469, 2020.
- Yurochkin et al. (2019) Mikhail Yurochkin, Mayank Agarwal, Soumya Ghosh, Kristjan Greenewald, Nghia Hoang, and Yasaman Khazaeni. Bayesian nonparametric federated learning of neural networks. In International Conference on Machine Learning, pages 7252–7261. PMLR, 2019.
- Zhang and Fletcher (2013) Miaomiao Zhang and Tom Fletcher. Probabilistic principal geodesic analysis. Advances in Neural Information Processing Systems, 26:1178–1186, 2013.
- Zhang et al. (2021) Xinwei Zhang, Xiangyi Chen, Mingyi Hong, Zhiwei Steven Wu, and Jinfeng Yi. Understanding clipping for federated learning: Convergence and client-level differential privacy. arXiv preprint arXiv:2106.13673, 2021.
- Zhao et al. (2019) Jun Zhao, Teng Wang, Tao Bai, Kwok-Yan Lam, Zhiying Xu, Shuyu Shi, Xuebin Ren, Xinyu Yang, Yang Liu, and Han Yu. Reviewing and improving the gaussian mechanism for differential privacy. arXiv preprint arXiv:1911.12060, 2019.
Appendix A. Theoretical derivation of Fed-mv-PPC method
Problem setting
We consider centers, each center providing data from subjects, each consisting of views. Let be the dimension of data corresponding to the -view, and .
For each and each , the generative model is:
| (7) |
where:
- •
denotes the raw data of the -view of the sample indexed by in center , which belongs to group .
- •
is a -dimensional latent variable, being a suitable user-defined latent-space dimension.
- •
provides the linear mapping between the two sets of variables for the -view.
- •
allows data corresponding to view to have a non-zero mean.
- •
is a Gaussian noise for the -view.
A compact formulation for (i.e. considering all views concatenated) can be easily derived from Equation (7):
| (8) |
where:
- •
- •
- •
- •
,
where is a diagonal block-matrix,
Note that for the sake of simplicity we represented all views. If in center the -view is missing, than it will be simply removed, e.g. one would have:
, .
For each center and each we want to estimate assuming that all local parameters are a realization of a common global distribution, to be estimated as well. The latter, provide a global model, which should be able to describe data across all centers.
Parameter
We assume that :
| (9) |
Step 1. (In each center): Estimate given (iteration is denoted by ).
The corresponding log-likelihood gives:
Therefore, for each center and for all , the following optimization problem should be considered:
where:
where collects terms which are independents from . We obtain:
Step 2. (In the master): Estimate given for all .
Complete-data log-likelihood
The joint distribution of and follows (), hence the expectation of the complete-data log-likelihood for each center with respect to :
| (15) | |||||
Parameter
We assume that :
| (16) |
Step 1. (In each center): Estimate given .
For each center , we consider the following optimization problem:
where
It follows:
Step 2. (In the master): Estimate given for all . Proceeding as for parameter and using (16):
| (17) |
and
Parameter
We assume that :
| (19) |
so that:
| (20) |
Step 1. (In each center): Estimate given .
For each center , we consider the following optimization problem:
where :
It follows:
| (21) | |||||
Step 2. (In the master): Estimate given for all .
In order to estimate the parameters of the inverse-gamma distribution, we use the (ML1) method described by Llera and Beckmann Llera and Beckmann (2016).
Appendix B. Supplementary Tables and Figures
| Group | Sex | Count | Age | Range |
| AD | Female | 94 | 71.58 (7.59) | 55.10 - 90.30 |
| Male | 113 | 74.37 (7.19) | 55.90 - 89.30 | |
| NL | Female | 58 | 73.76 (4.61) | 65.10 - 84.70 |
| Male | 46 | 75.39 (6.58) | 59.90 - 85.60 |
| View | Dim. | Description |
| CLINIC | 7 | Cognitive assessments |
| MRI | 41 | Magnetic resonance imaging |
| FDG | 41 | Fluorodeoxyglucose-Positron Emission Tomography (PET) |
| AV45 | 41 | AV45-Amyloid PET |
| SD | ADNI | |||||
| WAIC | MAE Train | MAE Test | WAIC | MAE Train | MAE Test | |
| 2 | -2911 | 0.08860.0031 | 0.08790.0024 | -4916 | 0.12400.0017 | 0.12490.0011 |
| 3 | -3954 | 0.06400.0029 | 0.06620.0038 | -5275 | 0.11700.0028 | 0.11870.0023 |
| 4 | -4725 | 0.04500.0036 | 0.04850.0042 | -6088 | 0.11130.0016 | 0.11420.0009 |
| 5 | 0.03270.0038 | 0.03750.0054 | -6915 | 0.10640.0017 | 0.11020.0007 | |
| 6 | -3688 | 0.03130.0032 | 0.03660.0052 | 0.10280.0015 | 0.10730.0005 | |
| 7 | 5722 | 0.03200.0036 | 0.03730.0053 | - | - | - |
| Scenario | Centers | Method | MAE Train | MAE Test | Accuracy in LS |
| IID | 1(centralizedcase) | Fed-mv-PPCA | 0.01243.e-5 | 0.04050.0037 | 10 |
| VAE | 0.08510.0039 | 0.10110.0048 | 10 | ||
| mc-VAE | 0.12360.0099 | 0.13820.0087 | 10 | ||
| 3 | Fed-mv-PPCA | 0.03200.0024 | 0.03730.0035 | 10 | |
| DP-Fed-mv-PPCA | 0.08580.0111 | 0.08480.0099 | 10 | ||
| VAE | 0.06830.0073 | 0.07020.0073 | 10 | ||
| mc-VAE | 0.11720.0030 | 0.11460.0046 | 10 | ||
| 6 | Fed-mv-PPCA | 0.04220.0052 | 0.03710.0039 | 10 | |
| DP-Fed-mv-PPCA | 0.08430.0093 | 0.07380.0076 | 10 | ||
| VAE | 0.07690.0093 | 0.06800.0080 | 10 | ||
| mc-VAE | 0.12950.0055 | 0.11340.0030 | 10 | ||
| G | 3 | Fed-mv-PPCA | 0.04320.0074 | 0.04330.0026 | 0.99300.0093 |
| DP-Fed-mv-PPCA | 0.09600.0151 | 0.09510.0144 | 0.98730.0176 | ||
| VAE | 0.07870.0135 | 0.06980.0082 | 0.98350.0272 | ||
| mc-VAE | 0.15620.0086 | 0.14970.0076 | 0.97320.0512 | ||
| 6 | Fed-mv-PPCA | 0.05380.0101 | 0.04200.0048 | 0.99950.0019 | |
| DP-Fed-mv-PPCA | 0.09450.0129 | 0.08130.0114 | 10 | ||
| VAE | 0.08910.0148 | 0.06850.0063 | 0.99180.0428 | ||
| mc-VAE | 0.17580.0154 | 0.14950.0112 | 0.96070.0398 | ||
| K | 3 | Fed-mv-PPCA | 0.03200.0052 | 0.04550.0069 | 10 |
| DP-Fed-mv-PPCA | 0.09220.0137 | 0.10480.0151 | 10 | ||
| 6 | Fed-mv-PPCA | 0.04020.0065 | 0.04480.0088 | 10 | |
| DP-Fed-mv-PPCA | 0.09590.0105 | 0.10140.0119 | 10 | ||
| G/K | 3 | Fed-mv-PPCA | 0.03950.0068 | 0.05670.0108 | 0.78120.02179 |
| DP-Fed-mv-PPCA | 0.11440.0215 | 0.13430.0235 | 0.78520.0526 | ||
| 6 | Fed-mv-PPCA | 0.04990.0104 | 0.05750.0128 | 0.77850.0222 | |
| DP-Fed-mv-PPCA | 0.10700.0139 | 0.11190.0144 | 0.78870.0449 |
| Centers | Method | MAE Train | MAE Test | Accuracy in LS | |
| 3 | VAE | 0 (FedAvg) | 0.11720.0022 | 0.11920.0015 | 0.82890.0383 |
| 0.01 | 0.12090.0074 | 0.12150.0013 | 0.79620.0438 | ||
| 0.05 | 0.12150.0076 | 0.12180.0015 | 0.80090.0425 | ||
| 0.1 | 0.12140.0075 | 0.12200.0018 | 0.80670.0399 | ||
| 0.2 | 0.12180.0077 | 0.12210.0016 | 0.79770.0469 | ||
| 0.3 | 0.12120.0075 | 0.12160.0017 | 0.78650.0443 | ||
| 0.4 | 0.12120.0074 | 0.12170.0014 | 0.80330.0355 | ||
| 0.5 | 0.12140.0077 | 0.12180.0020 | 0.78780.0420 | ||
| mc-VAE | 0 (FedAvg) | 0.16020.0035 | 0.15670.0017 | 0.88500.0262 | |
| 0.01 | 0.16740.0155 | 0.16050.0028 | 0.81850.0494 | ||
| 0.05 | 0.16670.0153 | 0.16040.0028 | 0.81560.0444 | ||
| 0.1 | 0.16740.0154 | 0.16090.0022 | 0.82490.0399 | ||
| 0.2 | 0.16760.0156 | 0.16100.0025 | 0.82170.0431 | ||
| 0.3 | 0.16760.0157 | 0.16100.0029 | 0.81840.0511 | ||
| 0.4 | 0.16730.0155 | 0.16070.0021 | 0.82750.0426 | ||
| 0.5 | 0.16790.0157 | 0.16130.0025 | 0.82290.0408 | ||
| 6 | VAE | 0 (FedAvg) | 0.13570.0042 | 0.11910.0014 | 0.82240.0377 |
| 0.01 | 0.14000.0114 | 0.11980.0022 | 0.78040.0470 | ||
| 0.05 | 0.14030.0115 | 0.12030.0021 | 0.78270.0411 | ||
| 0.1 | 0.14060.0116 | 0.12050.0019 | 0.78470.0531 | ||
| 0.2 | 0.14070.0117 | 0.12070.0018 | 0.78370.0433 | ||
| 0.3 | 0.14040.0115 | 0.12070.0018 | 0.78370.0569 | ||
| 0.4 | 0.14050.0116 | 0.12030.0020 | 0.77530.0546 | ||
| 0.5 | 0.14060.0113 | 0.12050.0023 | 0.77760.0501 | ||
| mc-VAE | 0 (FedAvg) | 0.18400.0054 | 0.15630.0017 | 0.88940.0230 | |
| 0.01 | 0.19320.0220 | 0.15960.0019 | 0.81400.0420 | ||
| 0.05 | 0.19270.0219 | 0.15920.0016 | 0.81010.0484 | ||
| 0.1 | 0.19320.0221 | 0.15950.0022 | 0.80430.0399 | ||
| 0.2 | 0.19300.0219 | 0.15960.0020 | 0.80660.0441 | ||
| 0.3 | 0.19310.0221 | 0.15950.0019 | 0.82170.0453 | ||
| 0.4 | 0.19310.0220 | 0.15940.0018 | 0.81110.0419 | ||
| 0.5 | 0.19340.0221 | 0.15960.0022 | 0.80210.0581 |