Are we using appropriate segmentation metrics? Identifying correlates of human expert perception for CNN training beyond rolling the DICE coefficient
Florian Kofler1,2,3,4 , Ivan Ezhov1,2, Fabian Isensee5,6, Fabian Balsiger7, Christoph Berger1, Maximilian Koerner1, Beatrice Demiray8, Julia Rackerseder8,9, Johannes Paetzold1,10,11, Hongwei Li1,12, Suprosanna Shit1,2, Richard McKinley7, Marie Piraud4, Spyridon Bakas13,14,15, Claus Zimmer3, Nassir Navab8, Jan Kirschke3, Benedikt Wiestler2,3,16, Bjoern Menze1,12,16
, Ivan Ezhov1,2, Fabian Isensee5,6, Fabian Balsiger7, Christoph Berger1, Maximilian Koerner1, Beatrice Demiray8, Julia Rackerseder8,9, Johannes Paetzold1,10,11, Hongwei Li1,12, Suprosanna Shit1,2, Richard McKinley7, Marie Piraud4, Spyridon Bakas13,14,15, Claus Zimmer3, Nassir Navab8, Jan Kirschke3, Benedikt Wiestler2,3,16, Bjoern Menze1,12,16
1: Department of Informatics, Technical University Munich, Germany, 2: TranslaTUM - Central Institute for Translational Cancer Research, Technical University of Munich, Germany, 3: Department of Diagnostic and Interventional Neuroradiology, School of Medicine, Klinikumrechts der Isar, Technical University of Munich, Germany, 4: Helmholtz AI, Helmholtz Zentrum München, Germany, 5: Applied Computer Vision Lab, Helmholtz Imaging, Germany, 6: Division of Medical Image Computing, German Cancer Research Center (DKFZ), Germany, 7: Support Center for Advanced Neuroimaging (SCAN), Institute for Diagnostic and Interventional Neuroradiology, Inselspital, Bern University Hospital, University of Bern, Bern, Switzerland, 8: Computer Aided Medical Procedures (CAMP), Technical University of Munich, Germany, 9: ImFusion GmbH, Munich, Germany, 10: Helmholtz Zentrum München, Germany, 11: Imperial College London, 12: Department of Quantitative Biomedicine, University of Zurich, Switzerland, 13: Center for Biomedical Image Computing and Analytics (CBICA), University of Pennsylvania, Philadelphia, Pennsylvania, USA, 14: Department of Pathology and Laboratory Medicine, Perelman School of Medicine, University of Pennsylvania, Philadelphia, Pennsylvania, USA, 15: Department of Radiology, Perelman School of Medicine, University of Pennsylvania, Philadelphia, Pennsylvania, USA, 16: contributed equally as senior authors
Publication date: 2023/05/03
https://doi.org/10.59275/j.melba.2023-dg1f
Abstract
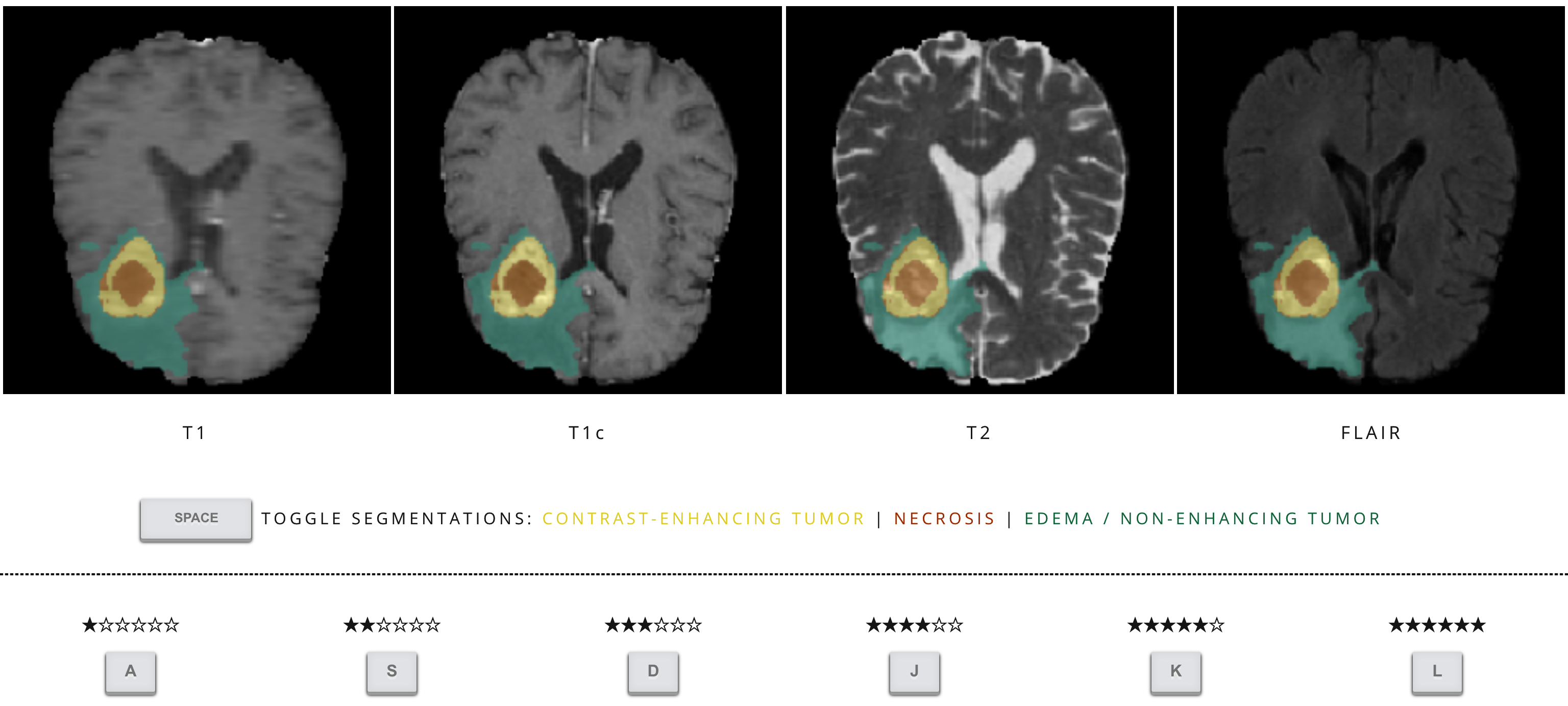
Metrics optimized in complex machine learning tasks are often selected in an ad-hoc manner. It is unknown how they align with human expert perception. We explore the correlations between established quantitative segmentation quality metrics and qualitative evaluations by professionally trained human raters. Therefore, we conduct psychophysical experiments for two complex biomedical semantic segmentation problems. We discover that current standard metrics and loss functions correlate only moderately with the segmentation quality assessment of experts. Importantly, this effect is particularly pronounced for clinically relevant structures, such as the enhancing tumor compartment of glioma in brain magnetic resonance and grey matter in ultrasound imaging. It is often unclear how to optimize abstract metrics, such as human expert perception, in convolutional neural network (CNN) training. To cope with this challenge, we propose a novel strategy employing techniques of classical statistics to create complementary compound loss functions to better approximate human expert perception. Across all rating experiments, human experts consistently scored computer-generated segmentations better than the human-curated reference labels. Our results, therefore, strongly question many current practices in medical image segmentation and provide meaningful cues for future research.
Keywords
machine learning · deep learning · interpretation · metrics · segmentation · glioma · MR · biomedical image analyis
Bibtex
@article{melba:2023:002:kofler,
title = "Are we using appropriate segmentation metrics? Identifying correlates of human expert perception for CNN training beyond rolling the DICE coefficient",
author = "Kofler, Florian and Ezhov, Ivan and Isensee, Fabian and Balsiger, Fabian and Berger, Christoph and Koerner, Maximilian and Demiray, Beatrice and Rackerseder, Julia and Paetzold, Johannes and Li, Hongwei and Shit, Suprosanna and McKinley, Richard and Piraud, Marie and Bakas, Spyridon and Zimmer, Claus and Navab, Nassir and Kirschke, Jan and Wiestler, Benedikt and Menze, Bjoern",
journal = "Machine Learning for Biomedical Imaging",
volume = "2",
issue = "May 2023 issue",
year = "2023",
pages = "27--71",
issn = "2766-905X",
doi = "https://doi.org/10.59275/j.melba.2023-dg1f",
url = "https://melba-journal.org/2023:002"
}
RIS
TY - JOUR
AU - Kofler, Florian
AU - Ezhov, Ivan
AU - Isensee, Fabian
AU - Balsiger, Fabian
AU - Berger, Christoph
AU - Koerner, Maximilian
AU - Demiray, Beatrice
AU - Rackerseder, Julia
AU - Paetzold, Johannes
AU - Li, Hongwei
AU - Shit, Suprosanna
AU - McKinley, Richard
AU - Piraud, Marie
AU - Bakas, Spyridon
AU - Zimmer, Claus
AU - Navab, Nassir
AU - Kirschke, Jan
AU - Wiestler, Benedikt
AU - Menze, Bjoern
PY - 2023
TI - Are we using appropriate segmentation metrics? Identifying correlates of human expert perception for CNN training beyond rolling the DICE coefficient
T2 - Machine Learning for Biomedical Imaging
VL - 2
IS - May 2023 issue
SP - 27
EP - 71
SN - 2766-905X
DO - https://doi.org/10.59275/j.melba.2023-dg1f
UR - https://melba-journal.org/2023:002
ER -