1 Introduction
The novel coronavirus disease 2019 (COVID-19) is an infectious disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). As of August 2022, more than 580 million cases have been reported worldwide (Johns Hopkins University (2020)). Early and accurate screening of the infected population and isolation from the public is an effective way to prevent and halt the spreading of the virus. Although the initial infection rates are reduced with the newly developed vaccines, the COVID-19 pandemic continues to affect lives around the world. Currently, the real-time polymerase chain reaction (RT-PCR) is considered as the gold standard in the diagnosis of COVID-19 (Tahamtan and Ardebili (2020)). When patients with confirmed COVID-19 arrive at hospitals, initial patient assessment often includes imaging studies such as radiologic examinations, which can be useful for rapid screening of disease (Shi et al. (2020)). Easily accessible chest X-ray (CXR) imaging has emerged as one of the preferred modalities due to its wide availability, less radiation exposure, and faster image acquisition times. However, the interpretation of CXR images is challenging due to low image resolution and COVID-19 image features being similar to regular pneumonia. Computer-aided diagnosis via deep learning has been investigated to help mitigate these problems and help clinicians during the decision-making process. The novel deep learning methods developed for improved diagnosis of COVID-19 have also led to advancements for similar tasks such as accurately detecting the presence of multiple diseases from CXRs or lung disease identification from ultrasound data (Arntfield et al. (2021); Liu et al. (2021)).
The most investigated computational approaches for detection of COVID-19 from CXR scans has been using deep convolutional neural networks (CNNs) with supervised learning (Wang et al. (2020); Ozturk et al. (2020); Manokaran et al. (2021)). Ozturk et al. (2020) proposed a CNN architecture with 17 layers named DarkCovidNet for detection of COVID-19 using CXR iamges. They achieved an average 87.02% three class classification accuracy using five-fold cross-validation. The method was evaluated on 127 COVID-19, 500 healthy and 500 pneumonia CXR scans. Wang et al. (2020) built a public dataset named COVIDx, which is comprised of a total of 13975 CXR images from 13870 patient case and developed COVID-Net. Their dataset had 358 COVID-19 images obtained from 266 patients. Their model achieved 93.3% overall accuracy for multiclass classification (Normal vs. Pneumonia vs. COVID-19). Manokaran et al. (2021) developed an deep transfer learning-based approach for the detection of COVID-19 infection on CXR images using DenseNet201. The proposed model was able to achieve an accuracy of 94% in detecting COVID-19 and an overall accuracy of 92.19%. The model was able to achieve an AUC of 0.99 for COVID-19, 0.97 for normal, and 0.97 for pneumonia.
Several groups have also investigated various image enhancement methods for improving the representation of CXR image data for improving the diagnostic performance of CNN methods. Rahman et al. (2021) investigated five different image enhancement techniques. Among them, the gamma correction-based enhancement technique outperformed other techniques in detecting COVID-19 from the plain and the segmented lung CXR images. The accuracy, precision, sensitivity, F1-score, and specificity were 95.11%, 94.55%, 94.56%, 94.53%, and 95.59% respectively were achieved tested on 724 COVID-19, 1771 normal, and 1203 Non-COVID segmented CXR images. Qi et al. (2020) investigated how local phase CXR feature-based image enhancement improves the accuracy of CNN architectures for COVID-19 diagnosis. Three different CXR local phase image features are combined as a multi-feature CXR image. Then a multi-feature CNN with various fusion techniques was proposed for processing both the original CXR image and the multi-feature CXR image. The multi-feature ResNet50 with late-fusion using sum operation achieves 95.57% and 94.44% average accuracy tested on two datasets including 3323 COVID-19, 8851 normal, and 6045 pneumonia CXR images.
Transformer, a deep neural network based on a self-attention mechanism, was first introduced in the field of natural language processing (NLP) and achieved dominant performance. Inspired by the success of the self-attention mechanism in NLP, Vision Transformer (ViT) has been introduced in 2021 and beats some state-of-the-art (SOTA) convolutional neural networks (CNNs) in some image recognition tasks (Dosovitskiy et al. (2020)). Recently, ViT has been applied for COVID-19 detection instead of CNN architectures (Park et al. (2021); Debaditya et al. (2021)). Debaditya et al. (2021) proposed a ViT for COVID-19 detection using CXR images. The authors collected data from three open-source datasets of CXR images including COVID-19, Pneumonia, and Normal cases from multiple datasets to obtain a total of 30,000 images. The proposed ViT model achieved an ACC of 92% and an AUC score of 0.98 for the multi-class classification (COVID-19, Normal, and Pneumonia). Park et al. (2021) proposed a hybrid model by conjugating the conventional CNN backbone for producing initial feature embedding. Their backbone network was DenseNet121 and trained using a large public ChexpertIrvin et al. (2019) datasets to obtain the abnormal features. Then, the embedded features from the backbone network were used as the corpus for ViT training. They achieved an average AUC of 0.94, 0.90, and 0.91 on the three datasets including 94 COVID-19, 1020 normal, and 491 other infections.
Motivated by the effectiveness of the local phase-based image enhancement technique, CNN and ViT in the detection of COVID-19 from CXR images, we propose a novel multi-scale feature fusion deep learning model. Multi-scale feature fusion has a long history in detection and recognition of objects (Feichtenhofer et al. (2018); Prakash et al. (2021)). We first utilize the local phase-based image enhancement technique to generate enhanced CXR images to provide more details of CXR images. Then, a Parallel-Attention (PA) block to encode feature correlation between original CXR images and local-phase enhanced CXR images is developed. Our proposed multi-feature fusion modal has two separate branches for processing the original CXR image and local-phase enhanced CXR image, and PA blocks are deployed after each feature extractor to fuse feature representations from two branches at multi-scales. In the end, the embedded features from two branches are fused together through cross-attention operations. In this work, our contributions and findings include the following: 1) we develop a novel multi-feature fusion deep learning model by deploying the PA blocks at multi-scales. 2) we show that our proposed method obtains improved results compared to state-of-the-art (SOTA) CNNs, ViTs, and multi-feature fusion models. 3) we demonstrate that local-phase feature enhanced CXR-image can further improve diagnostic performance by increasing generalization ability. 4) we also provide clinically interpretable visualization results of the model for helping COVID-19 diagnosis and localization.
2 Methods
2.1 Image Enhancement
The local phase-based image enhancement method extracts the phase signatures from the image and are intensity invariant (Alessandrini et al. (2012); Li et al. (2018)). Therefore, the enhancement results and subsequent image analysis methods are not affected by the intensity variations due to patient characteristics or machine acquisition settings. The local phase image features which provide more structural information about the local anatomy. Especially the consolidations are more dominantly represented and highly localized in the enhanced images.
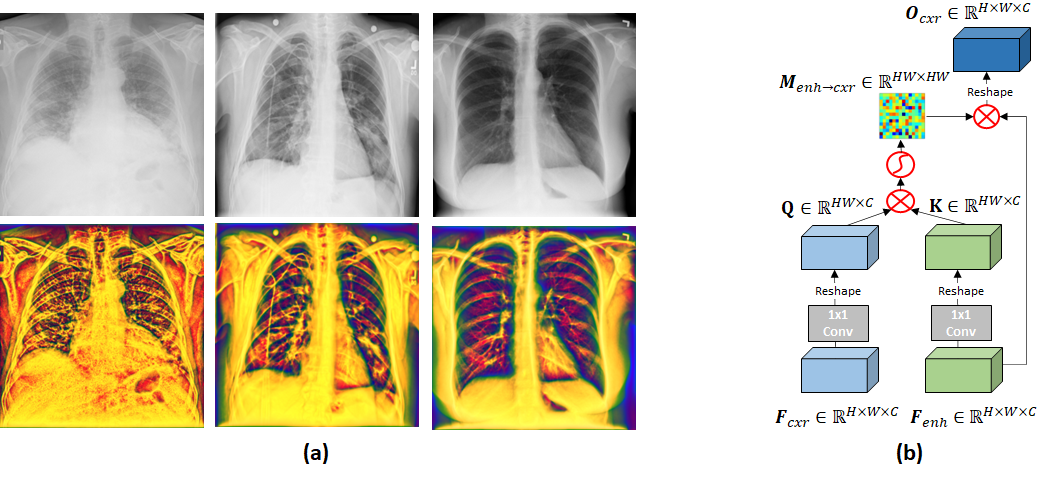
In the context of enhancing the appearance of CXR data, Qi et al. (2020) developed a local phase-based image enhancement method by designing bandpass quadrature filters. During this work, we deploy this image enhancement method for improving the representation of the CXR lung data (Qi et al. (2020)). The enhanced CXR image, termed multi-feature image , is obtained by combining three different local phase image features: 1-Local weighted mean phase angle (), 2- Weighted local phase energy (), and 3-Enhanced local energy attenuation image (). and image features are extracted by filtering the CXR image in frequency domain using monogenic filter and -scale space derivative (ASSD) bandpass quadrature filters (Qi et al. (2020)). image is extracted from the image by modeling the scattering and attenuation effects of lung tissue inside a local region using L1 norm-based contextual regularization method (Qi et al. (2020)). We have used the filter parameters reported in Qi et al. (2020) for processing all the CXR images used in this work. Investigating Figure 1, we can see that structural features inside the lung tissue are more dominant for COVID-19 CXR images compared to healthy lung tissue (last column Fig.1). The next section explains how the images are used to improve the diagnostic accuracy of our proposed deep learning model.
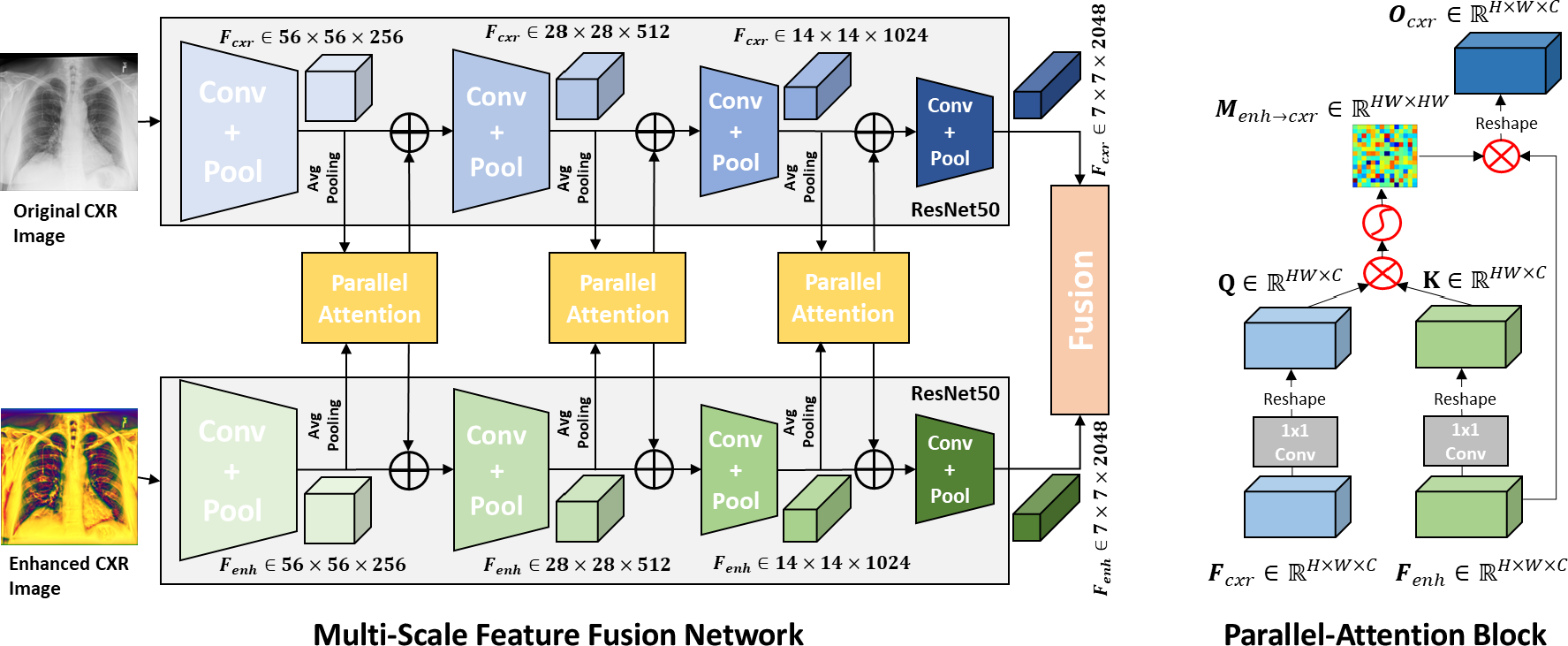
2.2 Parallel-Attention Block
Figure 2 (b) illustrates parallel-attention (PA) block for the original CXR images (), and the same procedure is performed for the enhanced CXR images () by simply swapping the index cxr and enh. Two embedded feature maps , from and are fed to a PA block. In a PA block, is fed to a 11 convolution layer for feature adaption to produce a query feature map Q , and meanwhile is fed to another 1 1 convolutional layer for feature adaption to produce a key feature map K , as shown in Eq.1. Q and K are then reshaped to . Then, matrix multiplication is performed between Q and K followed by a softmax layer to produce a attention matrix , as shown in Eq.2. Next, is reshaped to and multiples to produce output feature map , as shown in Eq.3. Through matrix multiplication between Q and K, our PA can effectively encode feature correlation between and into attention map M, and thus two attention maps ( and ) are generated by our PA block. Correspondence can then be captured by multiplying its corresponding F as shown in Eq.3.
| (1) | ||||
| (2) | ||||
| (3) |
2.3 Multi-Scale Parallel-Attention Fusion Network
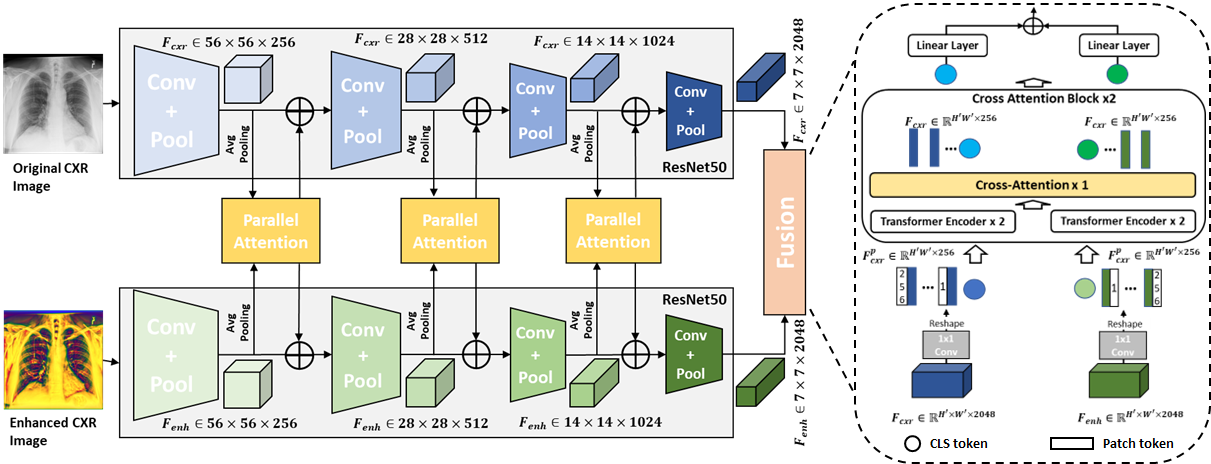
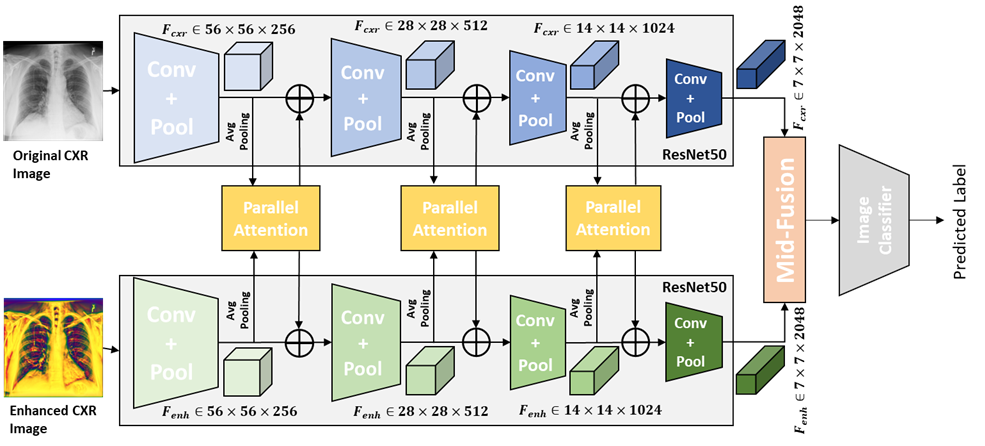
The network architecture of our propose multi-scale parallel-attention (MS-PA) fusion network is shown as Figure 2 (a). A image and its corresponding image as inputs are fed to two same CNN architectures, then several PA blocks are used for the fusion of intermediate feature maps from convolutional feature extractors between and images, and in the end a ViT with cross-attention is used for making the final decision. The convolutional feature extractors for the and inputs encode different aspects of the image at each scale. Therefore, we fuse these features at multiple scales throughout the convolutional encoder.
As shown in Figure 2 (a), the intermediate feature maps are fed to a PA block, which produces two outputs , . The each output is then fed back into each of the individual branch using an element-wise summation with the existing feature maps. The mechanism described above constitutes feature fusion at a single scale. This fusion is applied multiple times throughout the convolutional feature extractors of the and branches at different resolutions. However, processing feature maps at high spatial resolutions is computationally expensive, specially when your inputs have a high resolution. Therefore, we downsample higher resolution feature maps from the early convolutional feature extractors using average pooling (HW7) to the resolution of feature map from the last convolutional feature extractor before passing them as inputs to a PA block and upsample the output to the original resolution using bilinear interpolation before element-wise summation with the existing feature maps.
After PA fusion at multiple scales, feature maps are obtained at the last convolutional feature extractors from the and branches. Then, we projected encoded feature maps and of dimension into and with dimension of 256 using 1 1 convolution kernel. Then and are reshaped to . We prepended additional CLS tokens and added positional embedding for incorporating global context to and . Two cross-attention blocks are applied to further exchange information between and (Qi et al. (2022)). As and already encodes the representations for important findings from and , we adopted relatively simple architecture for Transformer encoder with two encoder layers with four attention heads. In the end, CLS tokens from two branches are projected into two 3-dimensional feature vectors and summed together.
3 Experiments
3.1 Datasets and Partitioning.
In this study, all images were collected from six public data repositories, which are BIMCV (de la Iglesia Vayá et al. (2020)), COVIDx (Wang et al. (2020)), COVID-19-AR (Desai et al. (2020)), MIDRC-RICORD-1c (Tsai et al. (2021)), COVID-19-IR (Winther et al. (2020)) and COVID-19-NY-SBU (Saltz et al. (2021)). Total dataset includes three classes: normal, pneumonia, and COVID-19. The numbers of images for each class are summarized in Table 1. COVID-19 CXR images from both (BIMCVde la Iglesia Vayá et al. (2020)) and COVIDx (Wang et al. (2020)) datasets plus 2567 randomly selected CXR images from normal and pneumonia classes composed the ’Evaluation Dataset’. To evaluate the generalization ability of models in various institutional settings, we used the rest normal and pneumonia CXR images from Wang et al. (2020) and four COVID-19 datasets collected from different institutions with different devices as ’Test Dataset-2’.
| Class | Total | Evaluation Dataset | Test Dataset-2 | |||||
| COVIDx | BIMCV | COVIDx | AR | 1c | IR | SBU | ||
| Normal | 8,851 | 2,567 | - | 6,284 | - | - | - | - |
| Pneumonia | 6,045 | 2,567 | - | 3,478 | - | - | - | - |
| COVID-19 | 10,776 | 400 | 2,167 | - | 249 | 977 | 243 | 6,740 |
| Total image | 25,672 | 5,534 | 2167 | 9,762 | 249 | 977 | 243 | 6,740 |
3.2 Implementation Details
We choose ResNet-50 pretrained on ImageNet that has the best performance reported by Qi et al. (2020) and DenseNet-121 with PCAM pooling pretrained on CheXpert (Irvin et al. (2019)) that achieved the first place in CheXpert challenge in 2019 (Ye et al. (2020)) as the backbone network architectures. CheXpert (Irvin et al. (2019)) dataset has 223,415 CXR images containing 13 labeled observations including no finding, enlarged cardiomediastinum, cardiomegaly, lung opacity, lung lesion, edema, consolidation, pneumonia, atelectasis, pneumothorax, pleural effusion, pleural other, and support devices. Binary cross-entropy (BCE) losses were used as the loss function. For training of the proposed model for COVID-19 diagnosis, we used SGD optimizer (momentum = 0.9) with learning rate of 0.001. The model was trained for 35 epochs with cosine warm-up scheduler (warm-up epochs = 4), with batch size set to 32. Five-fold cross-validation was performed on ’Evaluation Dataset’ for training and testing the proposed methods. Our augmentation method includes random translation, rotation, changing lighting condition, normalization, horizontal flip and resizing. We adopted mean overall accuracy (Acc) as our primary evaluation metric, but also calculated sensitivity, precision, F-1 score and area under the ROC curve (AUC). All experiments were performed with Python version 3.6 and PyTorch 1.10 on two Nvidia 1080Ti.
4 Results
Diagnostic performance of proposed methods: The diagnostic performances of our models are provided in Table 2. Dense121-PA-ViT achieves the average AUCs of 0.990, 0.992, average precision 0.960, 0.973, average sensitivity 0.963, 0.970, average F-1 score 0.963, 0.973, and average accuracy of 96.65%, 97.88% in the Evaluation dataset and Test dataset-2. In the Evaluation Dataset, both Res50-PA-ViT and Dense121-PA-ViT show 0.99 of precision, sensitivity, F-1 score for COVID-19 class, and Res50-PA-ViT achieves 99.12% accuracy for COVID-19 class slightly better than Dense121-PA-ViT. In the Test Dataset-2, Dense121-PA-ViT has the highest precision, sensitivity, F-1 score, AUC, and accuracy for all classes compared to Res50-PA-ViT.
| Metrics | Evaluation Dataset | Test Dataset-2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Avg. | Normal | Pneumonia | COVID | Avg. | Normal | Pneumonia | COVID | |
| AUC | 0.990 | 0.989 | 0.983 | 0.998 | 0.991 | 0.992 | 0.983 | 0.999 |
| Precision | 0.957 | 0.94 | 0.94 | 0.99 | 0.957 | 0.96 | 0.92 | 0.99 |
| Sensitivity | 0.953 | 0.94 | 0.93 | 0.99 | 0.960 | 0.96 | 0.93 | 0.99 |
| F-1 Score | 0.957 | 0.94 | 0.94 | 0.99 | 0.960 | 0.96 | 0.93 | 0.99 |
| Accuracy(%) | 96.04 | 94.66 | 94.34 | 99.12 | 97.05 | 96.54 | 95.43 | 99.19 |
| Metrics | Evaluation Dataset | Test Dataset-2 | ||||||
| Avg. | Normal | Pneumonia | COVID | Avg. | Normal | Pneumonia | COVID | |
| AUC | 0.990 | 0.987 | 0.985 | 0.998 | 0.992 | 0.993 | 0.985 | 0.999 |
| Precision | 0.960 | 0.94 | 0.95 | 0.99 | 0.973 | 0.96 | 0.96 | 1.00 |
| Sensitivity | 0.963 | 0.96 | 0.94 | 0.99 | 0.970 | 0.97 | 0.94 | 1.00 |
| F-1 Score | 0.963 | 0.95 | 0.95 | 0.99 | 0.973 | 0.97 | 0.95 | 1.00 |
| Accuracy(%) | 96.56 | 95.43 | 95.22 | 99.03 | 97.88 | 97.01 | 96.84 | 99.80 |
Comparison with baseline and SOTA models: Table 3 shows the diagnostic performances of our proposed models compared to the baseline and SOTA models. Res50-CXR and Res50-Enh were used as baseline models (Qi et al. (2020)). Dense121-ViT, Res50-mid, Res50-late fusion architectures proposed by Park et al. (2021) and Qi et al. (2020) respectively were used as SOTA models. Dense121-ViT has the same backbone structure as our proposed Dense121-PA-ViT, which was pre-trained using Chexpert (Irvin et al. (2019)) with PCAM pooling (Ye et al. (2020)) and finetuned using Evaluation Dataset. As shown in Table 3, our proposed Dense121-PA-ViT obtains the highest overall accuracy in both datasets and achieves statistically significant improvement compared with the best model in baseline and SOTA methods with paired t-test (). Our proposed Dense121-PA-ViT achieves significantly higher accuracy in identification of pneumonia cases compared to Dense121-ViT-Enh, the best SOTA model shown as in Table 3. Test Dataset-2 incorporates more COVID-19 CXR images, which were collected from multiple organizations with different devices and settings. Investigating Table 3, we can see that the performances of models drop significantly when testing on ‘Test Dataset-2’ if the training was performed using only. In comparison when the training data involved as a secondary dataset the performance and the generalization ability of the models improved. We also compared the performance of our proposed models with baseline and SOTA models in terms of AUC. Table 5 in the Appendix B shows the comparison results. Furthermore, an additional ultrasound (US) dataset was used to demonstrate the proposed method can be generalized to classification task from other image modalities. Similarly, the proposed Dense121-PA-ViT achieves the best performance in comparison with baseline and SOTA models. The detailed results are presented in the Appendix C.
| Methods | Evaluation Dataset | Test Dataset-2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Avg. | Normal | Pneumonia | COVID | Avg. | Normal | Pneumonia | COVID | |
| Res50-CXR | 94.20 | 93.79 | 90.44 | 98.36 | 88.12 | 91.77 | 87.79 | 86.72 |
| Res50-Enh | 94.13 | 94.43 | 91.12 | 96.83 | 95.61 | 94.72 | 90.71 | 98.37 |
| Res50-mid | 94.88 | 94.08 | 91.75 | 98.83 | 95.83 | 94.70 | 90.87 | 97.40 |
| (Qi et al. (2020)) | ||||||||
| Res50-late | 95.36 | 95.67 | 91.52 | 98.90 | 95.12 | 95.95 | 90.56 | 95.80 |
| (Qi et al. (2020)) | ||||||||
| Dense121-ViT-CXR | 93.74 | 91.86 | 90.62 | 98.75 | 90.14 | 90.73 | 88.29 | 90.32 |
| (Park et al. (2021)) | ||||||||
| Dense121-ViT-Enh | 94.87 | 96.69 | 90.54 | 97.39 | 96.77 | 96.09 | 90.68 | 99.88 |
| Res50-PA-ViT(ours) | 96.04 | 94.66 | 94.34 | 99.12 | 97.05 | 96.54 | 95.43 | 99.19 |
| Dense121-PA-ViT(ours) | 96.56 | 95.43 | 95.22 | 99.03 | 97.88 | 97.01 | 96.84 | 99.80 |
Ablation Study: We conducted an ablation study to investigate the effect of PA block for training a multi-feature network. The results of Table 4 suggest that adding PA block can further improve performance in two types of multi-feature fusion models, Res50-late and Res50-mid, reported in Qi et al. (2020). PA blocks were added to the fore-mentioned models, denoted as Res50-PA-late and Res50-PA-mid. The network architecture of Res50-PA-mid (Figure 5) and Res50-PA-late (Figure 6) are shown in the Appendix A. In the Evaluation Dataset, Res50-PA-mid achieves statistically significant improvement compared to Res50-mid without using PA blocks with paired t-test (). In the Test Dataset-2, Res50-PA-late is statistically significantly better than Res50-late with paired t-test().
| Methods | Evaluation Dataset | Test Dataset-2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Avg. | Normal | Pneumonia | COVID | Avg. | Normal | Pneumonia | COVID | |
| Res50-mid | 94.88 | 94.08 | 91.75 | 98.83 | 95.83 | 94.70 | 90.87 | 97.40 |
| Res50-late | 95.36 | 95.67 | 91.52 | 98.90 | 95.12 | 95.95 | 90.56 | 95.80 |
| Res50-PA-mid | 95.94 | 94.36 | 94.23 | 99.22 | 96.28 | 95.58 | 94.95 | 98.30 |
| Res50-PA-late | 95.87 | 94.44 | 93.96 | 99.22 | 96.54 | 95.45 | 95.02 | 99.16 |
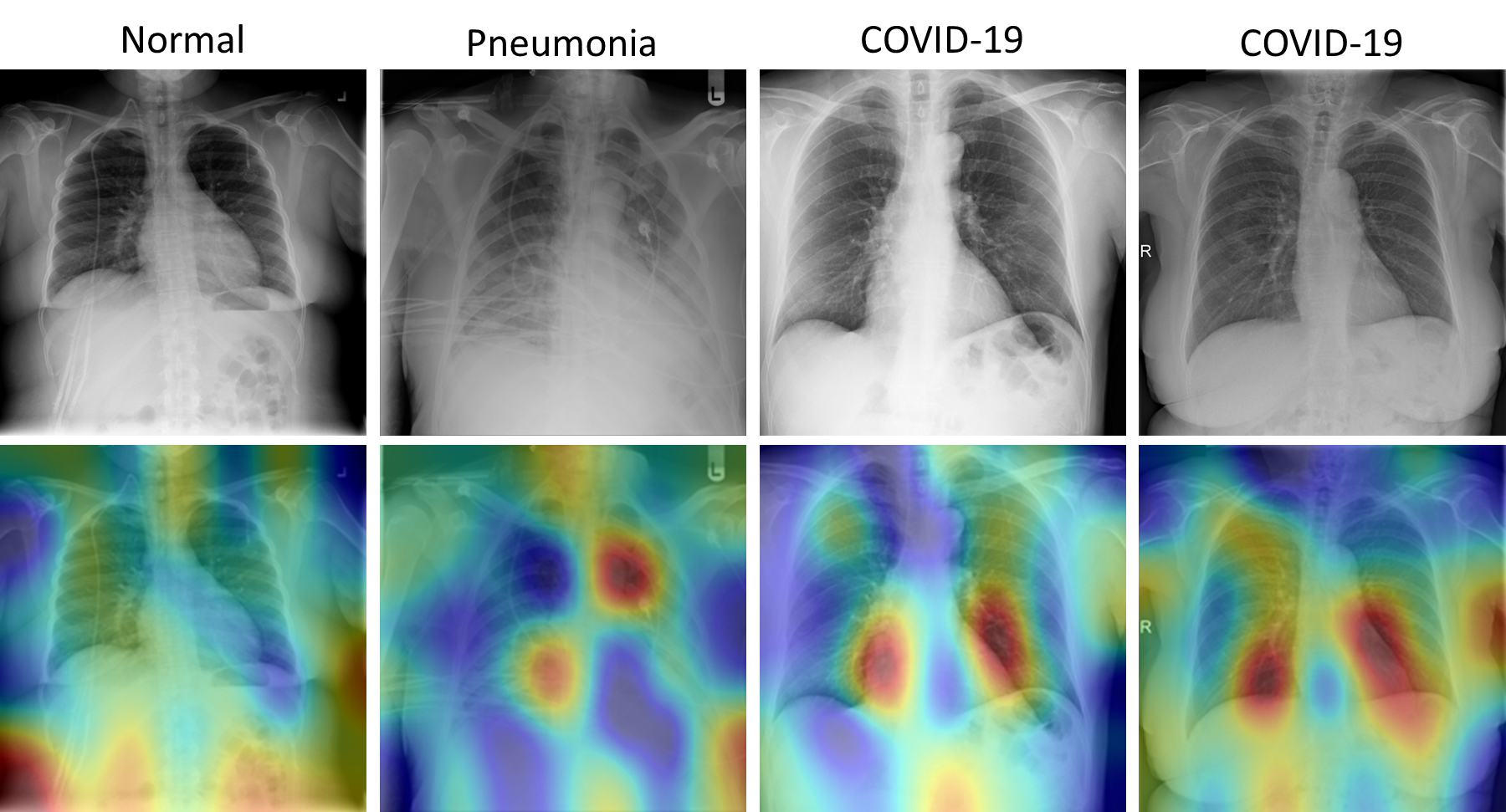
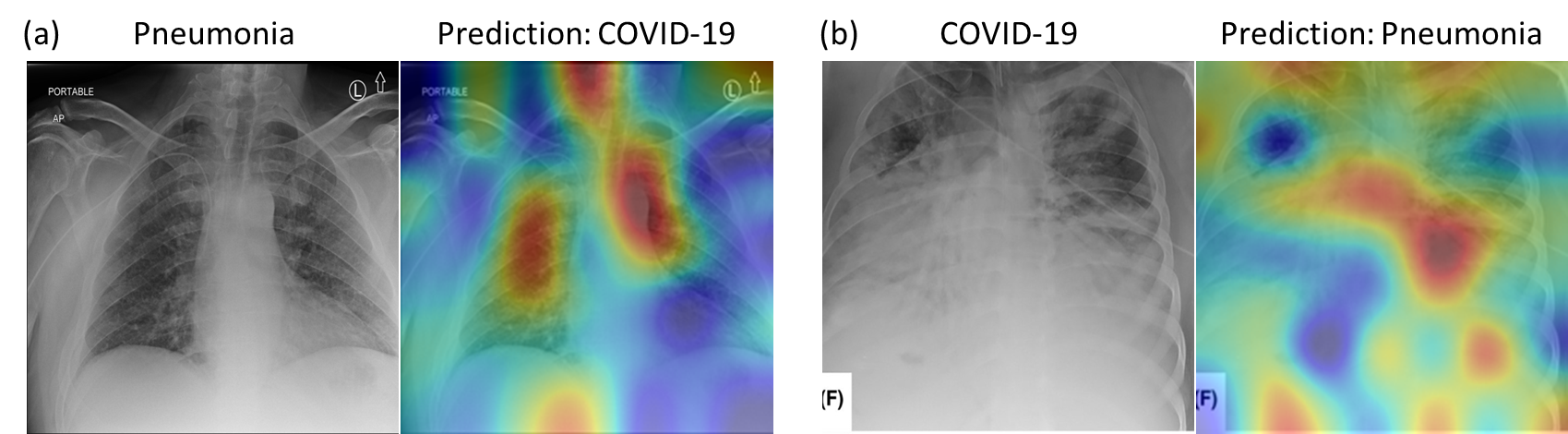
Grad-CAM Visualization Results: Figure 3 shows the examples of Grad-CAM Map (Selvaraju et al. (2016)) based visual representations for each disease classes. The Grad CAM Map visualization has the capability to highlight the regions in the lung that are significant for disease predictions as well as disease development.
The first column of Figure 3 shows a normal case having highlighted regions surrounding the lungs. The Grad-CAM based heatmap is similar to the reviewing process of a radiologist. During the reviewing, because the lungs are clear, the radiologist’s eye gaze skips around the image without focus on the lung (Karargyris et al. (2021)). The second column of Figure 3 shows pneumonia patient’s lungs with affected regions highlighted in dark red which indicate severe infection. It is similar to the physician’s eye gaze focuses on the focal lung opacity. The last two columns of Figure 3 show multi-focal infected areas in the lungs, which is common for the COVID-19 patients. The figure clearly shows that our proposed method recognizes and differentiates relevant impacted areas from COVID-19 and other pneumonia images.
To have a better understanding of the model’s misprediction, we exemplified the failure cases by the proposed model as shown in Figure 3. Its confusion could be explained by the generated Grad-CAM visual interpretations. Figure 3, (a) shows the model misclassified a case of pneumonia as COVID-19, as the location and distribution of the consolidations resemble those of COVID-19 (multi-focal consolidations), and (b) shows a severe COVID-19 case that was confused as pneumonia, where a focal cavitary lesion is similar to pneumonia case caused by bacteria infection. Our proposed Dense121-PA-ViT achieves a significantly higher accuracy compared to best SOTA model in identification of pneumonia cases (95.22% vs. 91.52% in the Evaluation Dataset; 96.84% vs. 90.87% in the Test Dataset-2).
5 Conclusion
In this work, we proposed a novel multi-feature fusion model for COVID-19 CXR diagnosis by applying parallel-attention block at multiple scales. The novelty of this study lies in leveraging self-attention mechanism to extract information from both original CXR images and local-phase enhanced CXR images at multiple scales. In addition, the local-phase based image enhancement method can eliminate intensity variance caused by different device setting and subjects characteristics so that increasing the model generality and stability. The experimental results on various COVID-19 test datasets confirm that our model not only achieves SOTA performance in the diagnosis of COVID-19 and other infectious disease but also retains stable performance irrespective of the external settings, which is a sine-qua-non for widespread application of system. Future work will include the extension of the method for accurately detecting the presence of multiple diseases from CXRs.
Ethical Standards
The work follows appropriate ethical standards in conducting research and writing the manuscript, following all applicable laws and regulations regarding treatment of animals or human subjects.
Conflicts of Interest
There is no conflict of interest.
References
- Alessandrini et al. (2012) Martino Alessandrini, Adrian Basarab, Hervé Liebgott, and Olivier Bernard. Myocardial motion estimation from medical images using the monogenic signal. IEEE transactions on image processing, 22(3):1084–1095, 2012.
- Arntfield et al. (2021) Robert Arntfield, Derek Wu, Jared Tschirhart, Blake VanBerlo, Alex Ford, Jordan Ho, Joseph McCauley, Benjamin Wu, Jason Deglint, Rushil Chaudhary, et al. Automation of lung ultrasound interpretation via deep learning for the classification of normal versus abnormal lung parenchyma: A multicenter study. Diagnostics, 11(11):2049, 2021.
- Born et al. (2021) Jannis Born, Nina Wiedemann, Manuel Cossio, Charlotte Buhre, Gabriel Brändle, Konstantin Leidermann, Julie Goulet, Avinash Aujayeb, Michael Moor, Bastian Rieck, et al. Accelerating detection of lung pathologies with explainable ultrasound image analysis. Applied Sciences, 11(2):672, 2021.
- de la Iglesia Vayá et al. (2020) Maria de la Iglesia Vayá, José Manuel Saborit, Joaquim Angel Montell, and et al. Bimcv covid-19+: a large annotated dataset of rx and ct images from covid-19 patients. arXiv preprint arXiv:2006.01174, 2020.
- Debaditya et al. (2021) Shome Debaditya, Kar T., Sachi Nandan Mohanty, Tiwari Prayag, Muhammad Khan, Altameem Abdullah, Zhang Yazhou, and Abdul Khader Jilani Saudagar. Covid-transformer: Interpretable covid-19 detection using vision transformer for healthcare. International Journal of Environmental Research and Public Health, 18(21), nov 2021. ISSN 1661-7827. doi: 10.3390/ijerph182111086.
- Desai et al. (2020) Shivang Desai, Ahmad Baghal, Thidathip Wongsurawat, Piroon Jenjaroenpun, Thomas Powell, Shaymaa Al-Shukri, Kim Gates, and et al. Chest imaging representing a covid-19 positive rural u.s. population. Scientific Data, 7, 2020. URL https://doi.org/10.1038/s41597-020-00741-6.
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2020. URL https://arxiv.org/abs/2010.11929.
- Feichtenhofer et al. (2018) Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition, 2018. URL https://arxiv.org/abs/1812.03982.
- Irvin et al. (2019) Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, Jayne Seekins, David A. Mong, Safwan S. Halabi, Jesse K. Sandberg, Ricky Jones, David B. Larson, Curtis P. Langlotz, Bhavik N. Patel, Matthew P. Lungren, and Andrew Y. Ng. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison, 2019. URL https://arxiv.org/abs/1901.07031.
- Johns Hopkins University (2020) Johns Hopkins University. Covid-19 dashboard by the center for systems science and engineering (csse). 2020.
- Karargyris et al. (2021) Alexandros Karargyris, Satyananda Kashyap, Ismini Lourentzou, Joy T Wu, Arjun Sharma, Matthew Tong, Shafiq Abedin, David Beymer, Vandana Mukherjee, Elizabeth A Krupinski, et al. Creation and validation of a chest x-ray dataset with eye-tracking and report dictation for ai development. Scientific data, 8(1):1–18, 2021.
- Li et al. (2018) Zhang Li, Lucas J van Vliet, Jaap Stoker, and Frans M Vos. A hybrid optimization strategy for registering images with large local deformations and intensity variations. International Journal of Computer Assisted Radiology and Surgery, 13(3):343–351, 2018.
- Liu et al. (2021) Fengbei Liu, Yuanhong Chen, Yu Tian, Yuyuan Liu, Chong Wang, Vasileios Belagiannis, and Gustavo Carneiro. Nvum: Non-volatile unbiased memory for robust medical image classification, 2021. URL https://arxiv.org/abs/2103.04053.
- Manokaran et al. (2021) Jenita Manokaran, Fatemeh Zabihollahy, Andrew Hamilton-Wright, and Eranga Ukwatta. Detection of COVID-19 from chest x-ray images using transfer learning. Journal of Medical Imaging, 8(S1), 2021. doi: 10.1117/1.JMI.8.S1.017503. URL https://doi.org/10.1117/1.JMI.8.S1.017503.
- Ozturk et al. (2020) Tulin Ozturk, Muhammed Talo, Eylul Azra Yildirim, Ulas Baran Baloglu, Ozal Yildirim, and U. Rajendra Acharya. Automated detection of covid-19 cases using deep neural networks with x-ray images. Computers in Biology and Medicine, 121:103792, 2020. ISSN 0010-4825. doi: https://doi.org/10.1016/j.compbiomed.2020.103792. URL https://www.sciencedirect.com/science/article/pii/S0010482520301621.
- Park et al. (2021) Sangjoon Park, Gwanghyun Kim, Yujin Oh, Joon Beom Seo, Sang Min Lee, Jin Hwan Kim, Sungjun Moon, Jae-Kwang Lim, and Jong Chul Ye. Vision transformer for covid-19 cxr diagnosis using chest x-ray feature corpus, 2021. URL https://arxiv.org/abs/2103.07055.
- Prakash et al. (2021) Aditya Prakash, Kashyap Chitta, and Andreas Geiger. Multi-modal fusion transformer for end-to-end autonomous driving. CoRR, abs/2104.09224, 2021. URL https://arxiv.org/abs/2104.09224.
- Qi et al. (2020) Xiao Qi, Lloyd Brown, David J. Foran, and Ilker Hacihaliloglu. Chest x-ray image phase features for improved diagnosis of covid-19 using convolutional neural network. 2020. doi: 10.48550/ARXIV.2011.03585. URL https://arxiv.org/abs/2011.03585.
- Qi et al. (2022) Xiao Qi, David Foran, John Nosher, and Ilker Hacihaliloglu. Multi-feature vision transformer via self-supervised representation learning for improvement of covid-19 diagnosis. 08 2022. doi: 10.48550/arXiv.2208.01843.
- Rahman et al. (2021) Tawsifur Rahman, Amith Khandakar, Yazan Qiblawey, Anas Tahir, Serkan Kiranyaz, Saad Bin Abul Kashem, Mohammad Tariqul Islam, Somaya Al Maadeed, Susu M. Zughaier, Muhammad Salman Khan, and Muhammad E.H. Chowdhury. Exploring the effect of image enhancement techniques on covid-19 detection using chest x-ray images. Computers in Biology and Medicine, 132:104319, 2021. ISSN 0010-4825. doi: https://doi.org/10.1016/j.compbiomed.2021.104319. URL https://www.sciencedirect.com/science/article/pii/S001048252100113X.
- Saltz et al. (2021) J. Saltz, P. Prasanna, and et al. Stony brook university covid-19 positive cases [data set]. 2021.
- Selvaraju et al. (2016) Ramprasaath R. Selvaraju, Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra. Grad-cam: Why did you say that? visual explanations from deep networks via gradient-based localization. CoRR, abs/1610.02391, 2016. URL http://arxiv.org/abs/1610.02391.
- Shi et al. (2020) Heshui Shi, Xiaoyu Han, Nanchuan Jiang, Yukun Cao, Osamah Alwalid, Jin Gu, Yanqing Fan, and Chuansheng Zheng. Radiological findings from 81 patients with covid-19 pneumonia in wuhan, china: a descriptive study. The Lancet infectious diseases, 20(4):425–434, 2020.
- Tahamtan and Ardebili (2020) Alireza Tahamtan and Abdollah Ardebili. Real-time rt-pcr in covid-19 detection: issues affecting the results. Expert review of molecular diagnostics, 20(5):453–454, 2020.
- Tsai et al. (2021) Emily B. Tsai, Scott Simpson, Matthew Lungren, and et al. The rsna international covid-19 open annotated radiology database (ricord). Radiology, 0(0):203957, 2021. doi: 10.1148/radiol.2021203957. URL https://doi.org/10.1148/radiol.2021203957. PMID: 33399506.
- Wang et al. (2020) Linda Wang, Zhong Qiu Lin, and Alexander Wong. Covid-net: a tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Scientific Reports, 10(1):19549, Nov 2020. ISSN 2045-2322. doi: 10.1038/s41598-020-76550-z. URL https://doi.org/10.1038/s41598-020-76550-z.
- Winther et al. (2020) Hinrich B. Winther, Hans Laser, Svetlana Gerbel, Sabine K. Maschke, Jan B. Hinrichs, Jens Vogel-Claussen, Frank K. Wacker, Marius M. Höper, and Bernhard C. Meyer. Covid-19 image repository. 5 2020. doi: 10.6084/m9.figshare.12275009.v1.
- Ye et al. (2020) Wenwu Ye, Jin Yao, Hui Xue, and Yi Li. Weakly supervised lesion localization with probabilistic-cam pooling, 2020. URL https://arxiv.org/abs/2005.14480.
A Network Architectures
A.1 Architecture of Res50-PA-mid:
Res50-PA-mid, shown as Figure 5, has the same feature extractor as the Res50-PA-ViT, but it uses middle fusion with Convolutional operation reported in Qi et al. (2020) instead.
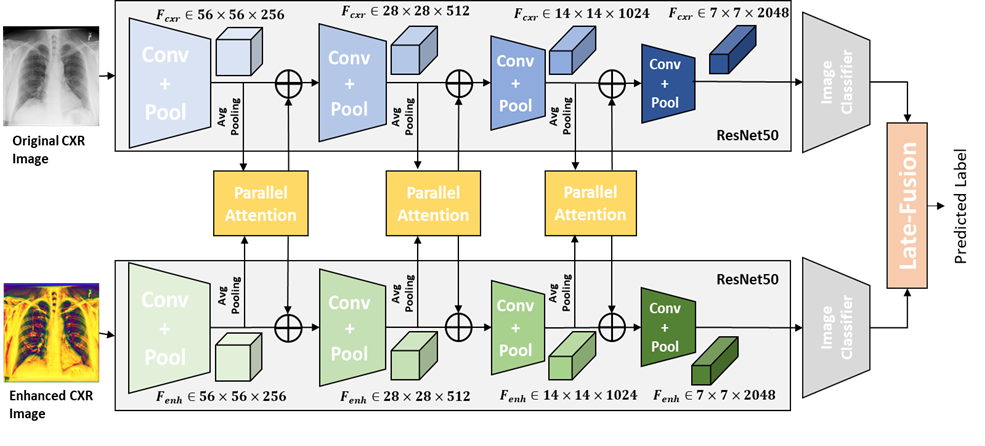
A.2 Architecture of Res50-PA-late:
Res50-PA-late, shown as Figure 6, also has the same feature extractor as the Res50-PA-ViT. After feature extraction, the features are feed into image classifier, which has the same structure of ResNet50. The final decision is made based on the joint correspondence using sum operation reported in Qi et al. (2020).
B Performance of Proposed Methods in terms of AUC
B.1 Comparison with baseline and SOTA models:
To reinforce the performance of proposed methods in the detection of COVID-19, we also report the results of AUC tested on Evaluation Dataset and Test Dataset-2 in comparison with baseline and SOTA models shown as Table 5. Dense121-PA-ViT achieves the highest average AUCs compared to other methods testing on two datasets. Res50-PA-mid and Res50-PA-late show a better performance compared to Res50-mid and Res50-late, two multi-feature fusion models without PA blocks reported in Qi et al. (2020). It demonstrates using PA blocks at multi-scales for feature fusion can further improve the model performance.
| Methods | Evaluation Dataset | Test Dataset-2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Avg. | Normal | Pneumonia | COVID | Avg. | Normal | Pneumonia | COVID | |
| Res50-CXR | 0.983 | 0.978 | 0.973 | 0.998 | 0.973 | 0.987 | 0.949 | 0.982 |
| Res50-Enh | 0.984 | 0.983 | 0.973 | 0.998 | 0.985 | 0.989 | 0.968 | 0.998 |
| Res50-mid | 0.986 | 0.984 | 0.977 | 0.998 | 0.985 | 0.989 | 0.967 | 0.999 |
| Res50-late | 0.986 | 0.983 | 0.977 | 0.998 | 0.984 | 0.992 | 0.963 | 0.999 |
| Res50-PA-mid | 0.988 | 0.987 | 0.979 | 0.999 | 0.987 | 0.994 | 0.968 | 0.999 |
| Res50-PA-late | 0.988 | 0.985 | 0.979 | 0.999 | 0.988 | 0.994 | 0.973 | 0.999 |
| Dense121-ViT-CXR | 0.984 | 0.981 | 0.977 | 0.996 | 0.976 | 0.990 | 0.955 | 0.983 |
| Dense121-ViT-Enh | 0.986 | 0.982 | 0.977 | 0.998 | 0.988 | 0.992 | 0.974 | 0.999 |
| Res50-PA-ViT(ours) | 0.990 | 0.989 | 0.983 | 0.998 | 0.991 | 0.992 | 0.983 | 0.999 |
| Dense121-PA-ViT(ours) | 0.990 | 0.987 | 0.985 | 0.998 | 0.992 | 0.993 | 0.985 | 0.999 |
C Evaluation on Ultrasound (US) Images
C.1 Dataset
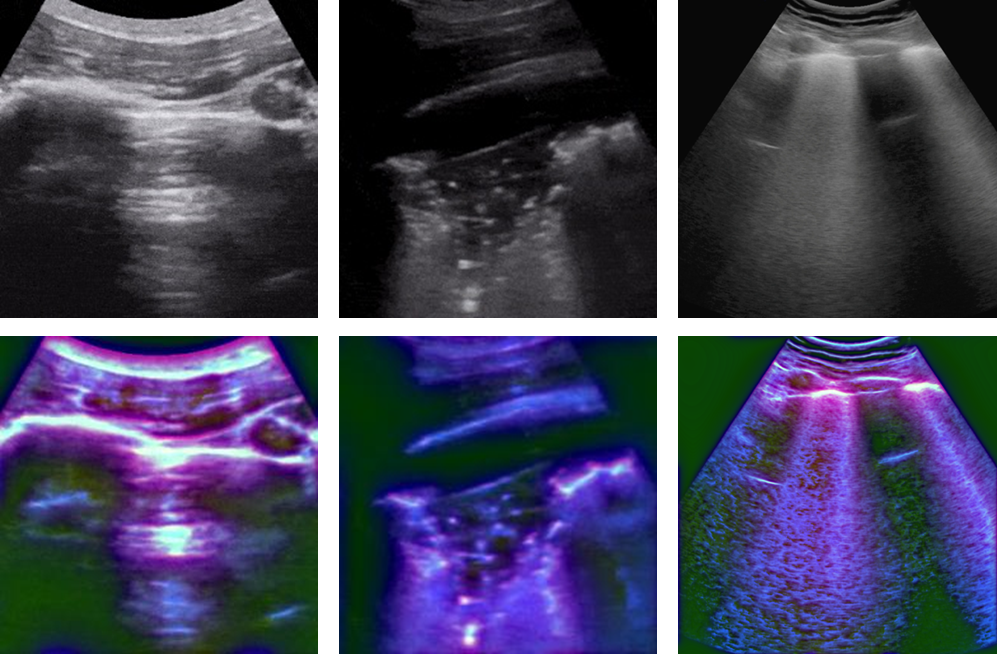
An publicly available US dataset (Born et al. (2021)) was choose as an additional dataset. The dataset has 2825 US images, including 852 COVID-19, 707 bacterial pneumonia, and 1266 healthy images, which are extracted from 157 convex ultrasound videos at a frame rate of 3Hz with maximal 30 frames per video and includes 56 convex ultrasound static images. All these images are split into five folds on a video level since the consecutive US frames are highly correlated. The reported local phase-based image enhancement method was applied to the US images to obtain the multi-feature images. Figure 7 shows the original US images and the corresponding enhanced US images for each class.
C.2 Results
Table 6 shows the diagnostic performance of our proposed method tested on the US dataset. Dense121-PA-ViT achieves the average AUC of 0.944, average precision 0.880, average sensitivity 0.877, average F-1 score 0.877, and average accuracy of 89.52%. Dense121-PA-ViT has the highest precision, sensitivity, F-1 score, AUC, and accuracy for all classes compared to Res50-PA-ViT.
Table 7 presents the diagnostic performances of our proposed models compared to the baseline and SOTA models in average accuracy and AUC. As shown in Table 7, Dense121-PA-ViT obtains the highest overall accuracy and class accuracy for all classes. And the proposed Dense121-PA-ViT achieves statistically significant improvement compared with the best baseline and SOTA methods with paired t-test () in overall accuracy and class accuracy. Investigating Table 7, we can also see the Dense121-PA-ViT obtains the highest overall AUC and class AUC except normal class. The Dense121-ViT-Enh achieves the highest AUC in identification of normal class.
| Metrics | Res50-PA-ViT (Ours) | Dense121-PA-ViT (Ours) | ||||||
|---|---|---|---|---|---|---|---|---|
| Avg. | Normal | Pneumonia | COVID | Avg. | Normal | Pneumonia | COVID | |
| AUC | 0.916 | 0.914 | 0.915 | 0.919 | 0.944 | 0.943 | 0.936 | 0.951 |
| Precision | 0.853 | 0.87 | 0.85 | 0.84 | 0.880 | 0.88 | 0.87 | 0.89 |
| Sensitivity | 0.847 | 0.87 | 0.86 | 0.81 | 0.877 | 0.89 | 0.89 | 0.85 |
| F-1 Score | 0.850 | 0.87 | 0.85 | 0.83 | 0.877 | 0.88 | 0.88 | 0.87 |
| Accuracy(%) | 87.42 | 87.36 | 88.99 | 85.91 | 89.52 | 88.53 | 90.83 | 89.20 |
| Methods | Accuracy for US Dataset | AUC for US Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Avg. | Normal | Pneumonia | COVID | Avg. | Normal | Pneumonia | COVID | |
| Res50-CXR | 82.55 | 86.63 | 81.38 | 76.33 | 0.870 | 0.902 | 0.867 | 0.840 |
| Res50-Enh | 83.71 | 88.02 | 85.41 | 73.72 | 0.878 | 0.931 | 0.884 | 0.820 |
| Res50-mid | 83.04 | 86.54 | 85.11 | 76.13 | 0.876 | 0.904 | 0.884 | 0.841 |
| Res50-late | 84.76 | 89.11 | 85.61 | 77.18 | 0.893 | 0.941 | 0.897 | 0.842 |
| Dense121-ViT-CXR | 86.34 | 86.54 | 88.21 | 84.27 | 0.907 | 0.920 | 0.935 | 0.868 |
| Dense121-ViT-Enh | 87.06 | 88.18 | 87.41 | 85.60 | 0.913 | 0.949 | 0.928 | 0.862 |
| Res50-PA-ViT(ours) | 87.42 | 87.36 | 88.99 | 85.91 | 0.916 | 0.914 | 0.915 | 0.919 |
| Dense121-PA-ViT(ours) | 89.52 | 88.53 | 90.83 | 89.20 | 0.944 | 0.943 | 0.936 | 0.951 |