

1 Introduction
The quest for efficient acquisition and reconstruction mechanisms in Magnetic Resonance Imaging (MRI) has been ongoing since its invention in the 1970’s. This led to a few major breakthrough, which comprise the design of efficient pulse sequences Bernstein et al. (2004), the use of parallel imaging Roemer et al. (1990); Blaimer et al. (2004), the theory and application of compressed sensing Lustig et al. (2008) and its recent improvements thanks to the progresses in learning and GPU computing Knoll et al. (2020). While the first attempts to use neural networks in this field were primarily focused on the efficient design of reconstruction algorithms Jacob et al. (2020), some recent works began investigating the design of efficient sampling schemes or joint sampling/reconstruction schemes. The aim of this paper is to make progress in the numerical analysis of this nascent and challenging field.
1.1 Some sampling theory
In a simplified way, an MRI scanner measures values of the Fourier transform of the image to reconstruct at different locations in the so-called k-space. The locations are obtained by sampling a continuous trajectory defined through a gradient sequence. The problem we tackle in this paper is: how to choose the points or the underlying trajectories in an efficient or optimal way?
Shannon-Nyquist
This question was first addressed using Shannon-Nyquist theorem, which certifies that sampling the k-space on a sufficiently fine Euclidean grid provides exact reconstructions using linear reconstructors. This motivated the design of many trajectories, such as the ones in echo-planar imaging (EPI) Schmitt et al. (2012). Progresses on non-uniform sampling theory Feichtinger and Gröchenig (1994) then provided guidelines to produce efficient sampling/reconstruction schemes for linear reconstructors. This theory is now mature for the reconstruction of bandlimited functions. In a nutshell, it advocates the use of a sampling set which covers the k-space sufficiently densely with well spread samples.
Compressed sensing theory
Shannon-Nyquist theory requires sampling the k-space densely, resulting in long scanning times. It was observed in the 1980’s that subsampling the high frequencies using variable density radial patterns did not compromise the image quality too much Ahn et al. (1986); Jackson et al. (1992). The first theoretical elements justifying this evidence were provided by the theory of compressed sensing, when using nonlinear reconstructors. This seminal theory is based on concepts such as the restricted isometry property (RIP) or the incoherence between the measurements Candès et al. (2006); Lustig et al. (2005). However it soon became evident that these concepts were not suited to the practice of MRI and a refined theory based on local coherence appeared in Adcock et al. (2017); Boyer et al. (2019). The main teaching is that a good sampling scheme for -based reconstruction methods must have a variable density that depends on the sparsity basis and on the sparsity pattern of the images. To the best of our knowledge, this theory is currently the one that provides the best explanation of the success of sub-sampling. In particular, analytical expressions of the optimal densities Adcock et al. (2020) can be derived and fit relatively well with the best empirical ones.
The main teachings
To date, there is still a significant discrepancy between the theory and practice of sampling in MRI. A mix between theory and common sense however provides the following main insights. A good sampling scheme should Boyer et al. (2016):
- •
have a variable density, decaying with the distance to the center of the k-space,
- •
have a sufficiently high density in the center to comply with the Shannon-Nyquist criterion, and sufficiently low to avoid dense clusters which would not bring additional information,
- •
have a locally uniform coverage of the k-space. In particular, nearby samples are detrimental to the reconstruction since they are highly correlated and increase the condition number of partial Fourier matrices.
These considerations are all satisfied when using Poisson disk sampling with an adequate density Vasanawala et al. (2011) for pointwise sampling. They also led to the development of the Sparkling trajectories Chauffert et al. (2017); Lazarus et al. (2019), which incorporate additional trajectory constraints in the design.
What can still be optimized?
Given the previous remarks, an important question remains open: how to choose the sampling density? An axiomatic approach leads to choosing radial densities with a plateau (constant value) at the center. The radial character ensures rotation invariance, which seems natural to image organs in arbitrary orientations. The plateau enforces Nyquist rate at the center. However, it may still be possible to improve the results for specific datasets.
1.2 Data-driven sampling schemes
The first attempts to learn a sampling density Knoll et al. (2011); Zhang et al. (2014) were based on the average energy of the k-space coefficients on a collection of reference images. While this principle is valid for linear reconstructions, it is not supported by a theoretical background when using nonlinear reconstructors. Motivated by the recent breakthroughs of learning and deep learning, many authors recently proposed to learn either the reconstructor Hammernik et al. (2018); Korkmaz et al. (2022); Muckley et al. (2021), the sampling pattern Baldassarre et al. (2016); Gözcü et al. (2018); Zibetti et al. (2021); Sherry et al. (2020), or both Jin et al. (2019); Bahadir et al. (2020); Weiss et al. (2021); Aggarwal and Jacob (2020); Zibetti et al. (2022); Wang et al. (2022). Data-driven optimization has emerged as a promising approach to tailor the sampling schemes with respect to the reconstructor and to the image structure. In Baldassarre et al. (2016); Gözcü et al. (2018); Sherry et al. (2020); Sanchez et al. (2020); Zibetti et al. (2021), the authors look for an optimal subset of a fixed set of k-space positions. The initial algorithms are based on simple greedy approaches that generated a sampling pattern by iteratively selecting a discrete horizontal line that minimizes the residual error of the reconstructed image. This approach is limited to low dimensional sets of parallel lines. Some efforts have been spent on finding better and more scalable solutions to this hard combinatorial problem using stochastic greedy algorithms Sanchez et al. (2020), -relaxation and bi-level programming Sherry et al. (2020) or bias-accelerated subset selection Zibetti et al. (2021). This method is reported to provide results over 3D images and seems to have solved some of the scalability issues.
To the best of our knowledge, the first work investigating the joint optimization of a sampling pattern and a reconstruction algorithm was proposed in Jin et al. (2019). In this work, the authors use a Monte Carlo Tree Search which allows them to optimize a policy that determines the positions to sample. This sampling relies on lines and the reconstruction process is an image to image domain with an inverse Fourier transform performed on the data before the denoising step. In the same spirit, Bahadir et al. (2020) proposes to learn MRI trajectories by optimizing a binary mask over a Cartesian grid with some sparsity constraint. The reconstruction is decomposed into two steps: a regridding using an inverse Fourier transform and a U-NET for de-aliasing. Finally, a new class of reconstruction methods called algorithm unrolling, mimicking classical variational approaches have emerged. These approaches improve the interpretability of deep learning based methods. Optimizing the weights of a CNN that plays the role of a denoiser in a conjugate gradient descent has been investigated in Aggarwal and Jacob (2020). The authors jointly optimize the sampling pattern and a denoising network based on an unrolled conjugate gradient scheme. The sampling scheme is expressed as the tensor product of 1D sampling patterns which significantly restricts the possible sampling schemes.
Overall, the previous works suffer from some limitations: the sampling points are required to live on a Cartesian grid, which may be non physical and lead to combinatorial problems; the methods cannot incorporate advanced constraints on the sampling trajectory and therefore focus on “rigid” constraints such as selecting a subset of horizontal lines.
To address these issues, some recent works propose to optimize points that can move freely in a continuous domain Weiss et al. (2021); Wang et al. (2022). This approach allows handling real kinematic constraints. In Weiss et al. (2021), the authors propose to reconstruct an image using a rough inversion of the partial Fourier transform, followed by a U-NET to eliminate the residual artifacts. They optimize jointly the weights of the U-NET together with the k-space positions using a stochastic gradient method. The physical kinematic constraints are handled using two different ingredients. First, the k-space points are regularly ordered by solving a traveling salesman problem, ensuring a low distance between consecutive points. Second, the constraints are promoted using a penalization function. This re-ordering step was then abandoned in Wang et al. (2022), where the authors use a B-spline parameterization of the trajectories with a penalization over the constraints in the cost function. Instead of using a rough inversion with a U-NET, the authors opted for an unrolled ADMM reconstructor where the proximal operator is replaced by a DIDN CNN Yu et al. (2019). The k-space locations and the CNN weights are optimized jointly. In both works, long computation times and memory requirements are reported. We also observed significant convergence issues related to the existence of spurious minimizers Gossard et al. (2022).
1.3 Our contribution
The purpose of this work is to improve the process of optimizing sampling schemes from a methodological perspective. We propose a framework that optimizes the sampling density using Bayesian Optimization (BO). Our method has a few advantages compared to recent learning based approaches: i) it globalizes the convergence by reducing the dimensionality of the optimization problem, ii) it reduces the computing times drastically, iii) it requires only a small number of reference images and iv) it works off-the-grid and handles arbitrary physical constraints. The first three features are essential to make sampling scheme optimization tractable in a wide range a different MRI scanners. The last one allows more versatility in the sampling patterns that can take advantage of all the degrees of freedom offered by an MRI scanner.
2 The proposed approach
In this section, we describe the main ideas of this work after having introduced the notation.
2.1 Preliminaries
Images
Let denote the set of training images . A -dimensional image is a vector of , where and denotes the number of pixels in the -th direction. In this work, each index , is associated with a position on Euclidean grid. It describes the location of the -th pixel in the k-space. With a slight abuse of notation, we associate to each discrete image , a function still denoted , defined by
where denotes the convolution-product and where is an interpolation function. For instance, we can set as the indicator of a grid element to generate piece-wise constant images.
Image quality
To measure the reconstruction quality, we consider an image quality metric . The experiments in this work are conducted using the squared distance . Any other metric could be used instead with the proposed approach.
The Non-Uniform Fourier Transform
Throughout the paper, we let denote a set of locations in the k-space (or Fourier domain). Let denote the forward non-uniform Fourier transform defined for all and by
| (1) |
where is the Fourier transform of the interpolation function .
Image reconstruction
We let denote an image reconstruction mapping. For a measurement vector , a sampling scheme , and a parameter , we let denote the reconstructed image. In this paper, we will consider two different reconstructors:
- •
A Total Variation (TV) reconstructor Lustig et al. (2008), which is a standard baseline:
(2) where is a regularization parameter. The approximate solution of this problem is obtained with an iterative algorithm run for a fixed number of iterations. We refer the reader to Appendix A.1 for the algorithmic details. This allows us to use the automatic differentiation of PyTorch as described in Ochs et al. (2015).
- •
An unrolled neural network , where denotes the weights of the neural network. There is now a multitude of such reconstructors available in the literature Muckley et al. (2021). They draw their inspiration from classical model-based reconstructors with hand-crafted priors. The details are provided in Appendix A.2.
Constraints on the sampling scheme
As mentioned in the introduction, the sampling positions correspond to the discretization of a k-space trajectory subject to kinematic constraints. Throughout the paper, we let denote the constraint set for . A sampling set consists of trajectories (shots) with measurements per shot. We consider realistic kinematic constraints on these trajectories. Let denote the maximal speed of a discrete trajectory and denote its maximal acceleration (the slew rate). We let
| (3) |
where
where is a vector and a matrix encoding some position constraints. For instance, we enforce the first point of each trajectory to start at the origin. Since the sampling schemes consists of trajectories, the constraint set on the sampling is . The total number of measurements is equal to . We refer the reader to Chauffert et al. (2016) for more details on these constraints.
2.2 The challenges of sampling scheme optimization
In this paper, we consider the optimization of a sampling scheme for a fixed reconstruction mapping . A good sampling scheme should reconstruct the images in the training set efficiently on average. Hence, a natural optimization criterion is
| (4) |
The term corresponds to the measurements of the image associated with the sampling scheme . The expectation is taken with respect to the term which models noise on the measurements. More elaborate forward models can be designed to account for sensibility matrices in multi-coil imaging or for trajectory errors. We will not consider these extensions in this paper. Their integration is straightforward – at least at an abstract level.
Even if problem (4) is simple to state (and very similar to Weiss et al. (2021); Wang et al. (2022)), the practical optimization looks extremely challenging for the following reasons:
- •
The computation of the cost function is very costly.
- •
Computing the derivative of the cost function using backward differentiation requires differentiating a Non-uniform Fast Fourier Transform (NFFT). It also requires a consequent quantity of memory that limits the complexity of the reconstruction mapping.
- •
The energetic landscape of the functional is usually full of spurious minimizers Gossard et al. (2022).
- •
The minimization of an expectation calls for the use of stochastic gradient descent, but the additional presence of a constraint set reduces the number of solvers available.
Hence, the design of efficient computational solutions is a major issue. It will be the main focus of this paper. The following sections are dedicated to the simplification of (4) and to the design of a lightweight solver. We also propose a home-made solver that attacks (4) directly. Since similar ideas were proposed in Wang et al. (2022), we describe the main ideas and differences in Appendix A.5.1 only.
2.3 Regularization and dimensionality reduction
The non-convexity of (4) is a major hurdle inducing spurious minimizers Gossard et al. (2022). We discuss the existing solutions to mitigate this problem and give our solution of choice.
2.3.1 Existing strategies and their limitation
In Weiss et al. (2021); Wang et al. (2022), the authors propose to avoid local minima by using a multi-scale optimization approach starting from a trajectory described through a small number of control points and progressively getting more complex through the iterations. The use of the stochastic Adam optimizer can also allow escaping from narrow basins of attraction. In addition, Adam optimizer can be seen as a preconditioning technique, which can accelerate the convergence, especially for the high frequencies Gossard et al. (2022). This optimizer together with a multi-scale approach can yield sampling schemes with improved reconstruction quality at the cost of a long training process. However, despite heuristic approaches to globalize the convergence, we experienced significant difficulties in getting reproducible results.
To illustrate this fact, we conducted a simple experiment in Fig. 1. Starting from two similar initial sampling trajectories, we let a multi-scale solver run for 14 epochs and 85 hours on the fastMRI knee database. We then evaluate the average reconstruction peak signal-to-noise ratio (PSNR) on the validation set. As can be seen, the final point configuration and the average performance varies by dB, which is significant. This suggests that the algorithm was trapped in a spurious local minimizer and illustrates the difficulty to globalize the convergence.
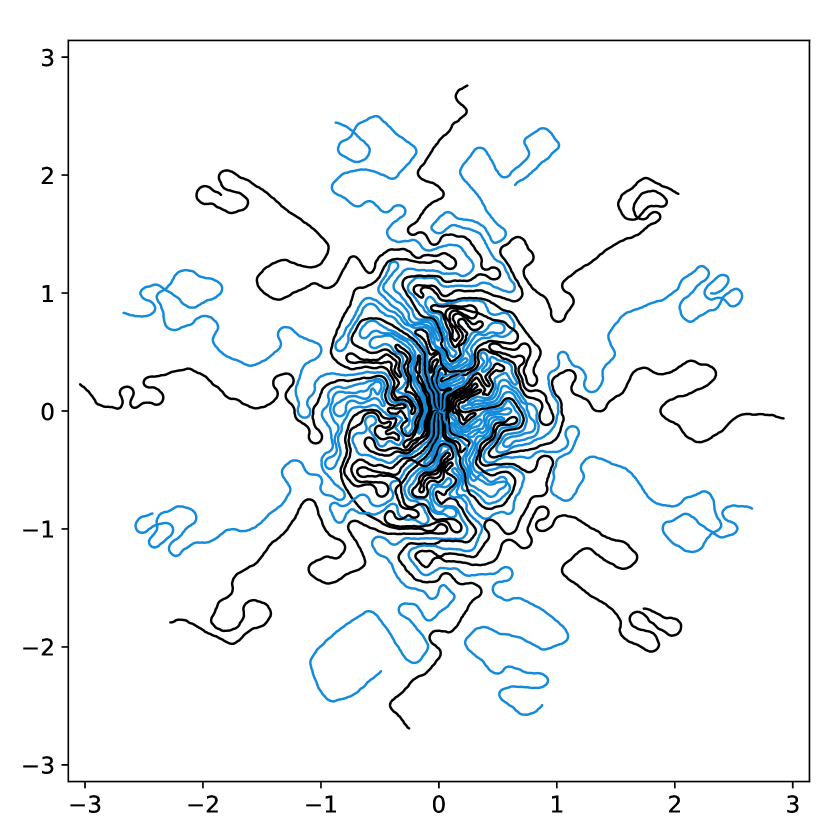
dB
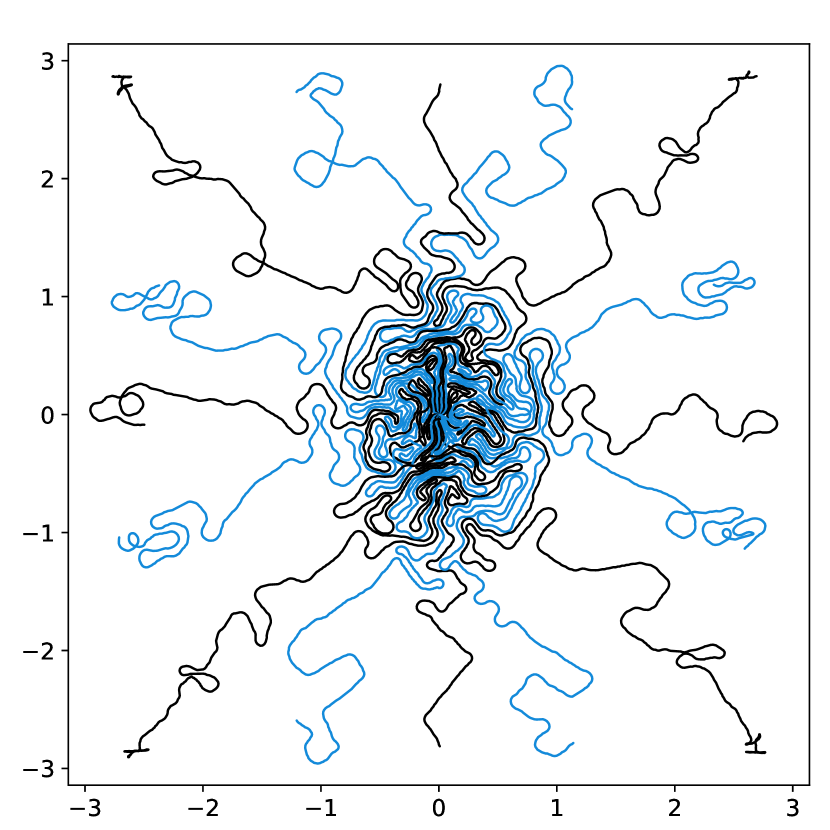
dB
2.3.2 Optimizing a sampling density
The key idea in this paper is to regularize the problem by optimizing a sampling density rather than the point positions directly. To formalize this principle we need to introduce two additional ingredients:
- 1.
A probability density generator , where is the set of probability distributions on . In this paper, will be defined as a simple affine mapping, but we could also consider more advanced generators such as Generative Adversarial Networks.
- 2.
A trajectory sampler , which maps a density to a point configuration . Various possibilities could be considered such as Poisson point sampling, Poisson disk sampling. In this paper, we will use discrepancy based methods Boyer et al. (2016).
Instead of minimizing (4), we propose to work directly with the density. Letting denote the mapping defined by
| (5) |
we propose to minimize:
| (6) |
where the expectation is taken with respect to the noise term . A schematic illustration of this approach is proposed in Fig. 2.
2.3.3 The density generator
Various approaches could be used to define a density generator . In this work, we simply define as an affine mapping, i.e.
| (7) |
where belongs to a properly defined convex set . We describe hereafter how the eigen-elements and the set are constructed.
A candidate space of densities
The general idea of our construction is to define a family of elementary densities and to enrich it by taking convex combinations of its elements.
Let denote a rotation angle, denote lengths, denote a density at the center and a decay rate. For , let , . We define
| (8) |
where is a normalizing constant such that . We then smooth the function by convolving it with a Gaussian function of standard deviation :
| (9) |
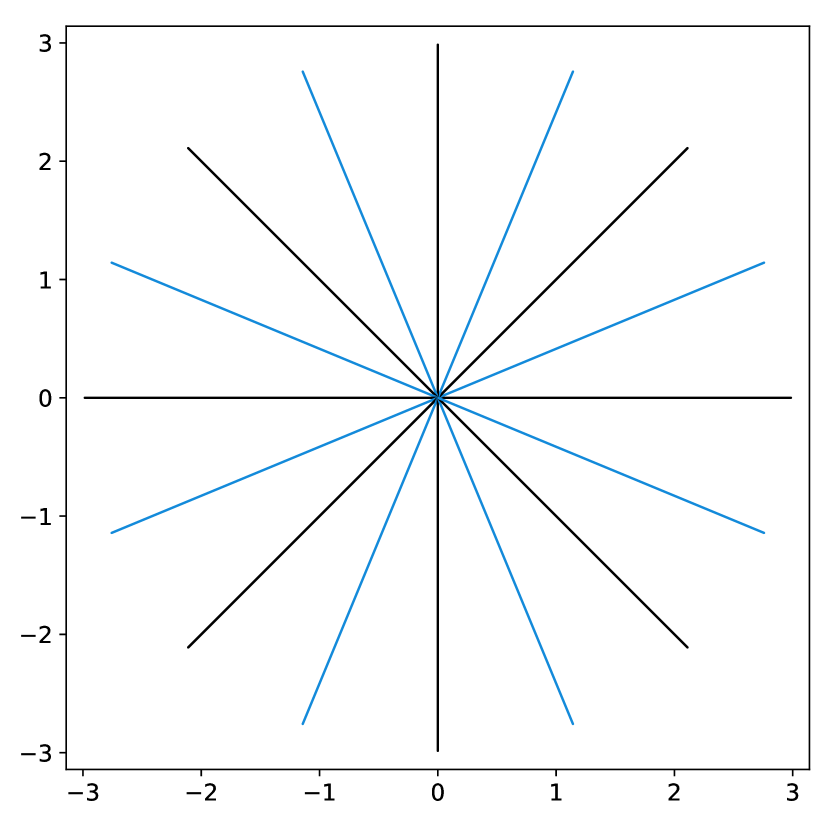
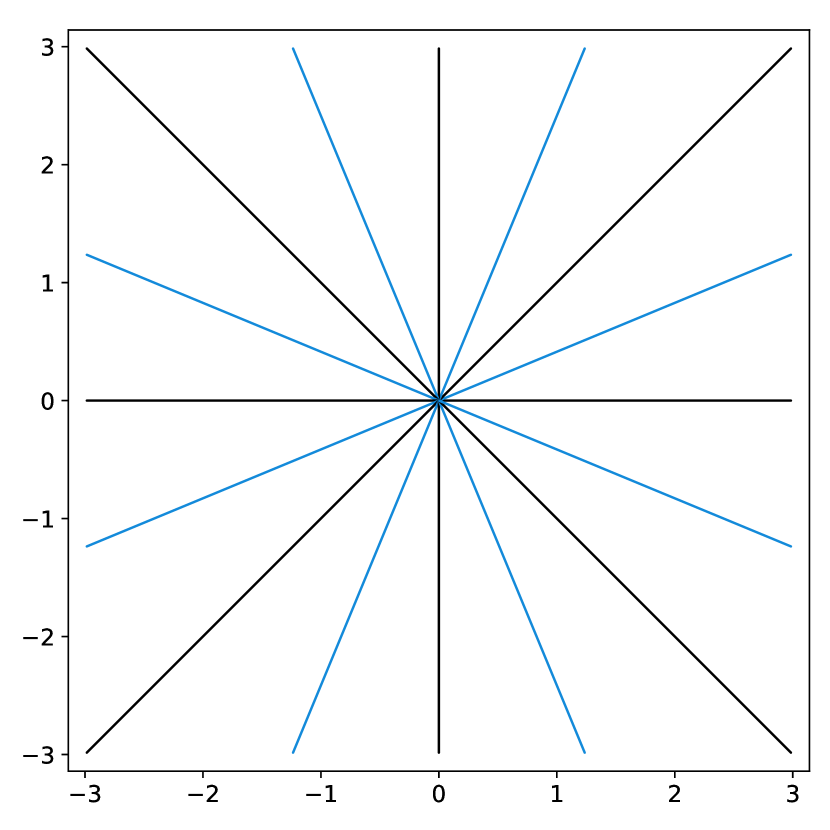
The elements in this family are good candidates for sampling densities: i) they are nearly constant and approximately equal to at the center of the k-space, ii) they can be anisotropic to accommodate for specific image orientations and iii) they have various decay rates, allowing sampling the high frequencies more or less densely. Some examples of such densities are displayed in Fig. 3(a). However, the family of densities generated by this procedure is quite poor. For instance, it is impossible to sample densely both the and axes simultaneously. In order to enrich it, we propose to consider the set of convex combinations of these elementary densities. This allows us to construct more general multi-modal densities, see Fig. 3(b) for examples of such convex combinations.
Dimensionality reduction
In order to construct the family , we first draw a large family of densities . They are generated at random by uniform draws of the parameters inside a box. We then perform a principal component analysis (PCA) on this family to generate some eigen-elements . We set . Since probability densities must sum to , we orthogonalize the family with respect to the vector . Thereby, we obtain a second family that satisfies and for all . This procedure discards one dimension. The resulting PCA basis is illustrated in Fig. 3(c).
Let denote the intersection of the span of with the probability densities and the orthogonal projection on . The space of densities is the convex hull of the family projected on :
| (10) |
As illustrated in Fig. 3(b), this process overall provides a rather rich and natural family. In practice, we select a value , so that the tail of the singular values contains less than of the energy. This value is also a compromise between numerical complexity (the higher , the more complex) and the richness of the family of densities that can be generated.




















2.3.4 The sampler
The sampler is based on discrepancy minimization Schmaltz et al. (2010); Gräf et al. (2012); Chauffert et al. (2017). It is defined as an approximate solution of
| (11) |
where indicates the Dirac delta function, is the set of feasible discrete trajectories and is a discrepancy defined by
where is a positive definite kernel (i.e. a function with a real positive Fourier transform). Other metrics on the set of probability distributions could be used such as the transportation distance Lebrat et al. (2019). The formulation (11) has already been proposed in Chauffert et al. (2017) and it is at the core of the Sparkling scheme generation Lazarus et al. (2019). We will discuss the choice of the kernel in the numerical experiments: it turns out to play a critical role.
In practice (11) is not solved exactly: an iterative solver Chauffert et al. (2016) is ran for a fixed number of iterations. This allows the use of automatic differentiation in order to compute the Jacobian of w.r.t. . Technical details about the implementation of this sampler are provided in Appendix A.5.
2.3.5 The pros and cons of this strategy
The optimization problem (6) presents significant advantages compared to the original one (4):
- •
The number of optimization variables is considerably reduced: instead of working with variables, we now only work with variables defining a continuous density. In this paper we set which is considerably smaller in comparison to the 2D sampling points for the formulation of (4) with undersampling on images. This allows resorting to global optimization routines. Hereafter, we will describe a Bayesian optimization approach.
- •
The point configurations generated by this algorithm are always locally uniform since they correspond to the minimizers of a discrepancy. Clusters are therefore naturally discarded, which can be seen as a natural regularization scheme.
- •
As discussed in the numerical experiments, the regularization effect allows optimizing the sampling density with a small dataset with a similar performance. Optimizing the function with as little as reference images yields a near optimal density. This aspect might be critical for small databases.
On the negative side, notice that we considerably constrained the family of achievable trajectories, thereby reducing the maximal achievable gain. We will show later that the trajectories obtained by minimizing (6) are indeed slightly less efficient than those obtained with (4). This price might be affordable if we compare it to the advantages of having a significantly faster and more robust solver requiring only a fraction of the data needed for solving (4).
2.4 The optimization routine
In this section, we describe an algorithmic approach to attack the problem (6).
2.4.1 The non informativeness of the gradient
A natural approach to solve (6) is to optimize the coefficients using a gradient based algorithm. Indeed, one may hope that the reparameterization of the cost function with a density prevents the appearance of spurious minimizers described in Gossard et al. (2022). Unfortunately, this is not the case and gradient based algorithms might be trapped in such local minimizers. Fig. 4 and 5 illustrate this fact. In Fig. 4, the baseline sampling scheme is shifted continuously in the and directions. The cost function is evaluated for each shift and displayed in the right. Observe that many local minimizers are present. Similarly, in Fig. 5, a target density is varied continuously in a subspace consisting of eigen-elements . Again, the energy profiles on the right are highly oscillatory.
Overall, this experiment shows that the gradient direction is not meaningful: it oscillates in an erratic way. This advocates for the use of 0th order optimization methods. A significant advantage of this observation is that it allows discarding the memory and time issues related to automatic differentiation.

images.
images.
2.4.2 Bayesian optimization
As can be seen from the energy profiles in Fig. 4, the cost function seems to be decomposable as a smooth function plus an oscillatory one of low amplitude. This calls for the use of algorithms that i) sample the function at a few scattered points, ii) construct a smooth surrogate approximation, iii) find a minimizer of the surrogate and add it to the explored samples, iv) go back to ii).
Bayesian Optimization (BO) Frazier (2018) is a principled approach that follows these steps. It seems particularly adequate since it models uncertainty on the function evaluations and comes with advanced solvers Balandat et al. (2020). Its application is nonetheless nontrivial and requires some care in our setting. We describe some technical details hereafter.
Consider an objective function of the form
where the expectation is taken with respect to a random vector . In our setting, models both the noise and the input images . We consider to be a random vector taken uniformly inside a database. In that setting, Bayesian optimization requires the following ingredients:
- 1.
An initial sampling set.
- 2.
A black-box evaluation routine of .
- 3.
A family of interpolation functions together with a regression routine.
- 4.
A solver that minimizes the regression function.
Hereafter, each choice made in this work is described.
The initial sampling set
To initialize the algorithm, we need the convex set to be covered as uniformly as possible in order to achieve a good uniform approximation of the energy profile. In this work, we used a maximin space covering design Pronzato (2017). The idea is to construct a discrete set that solves approximately
| (12) |
In words, we want the minimal distance between pairs of points in to be as large as possible. This problem is known to be hard. In this work we used the recent solver proposed in Debarnot and Weiss (2022) together with the Faiss library Johnson et al. (2019).
The evaluation routine
Evaluating the cost function (6) is not an easy task. For just one realization of the noise and image , we need a fast reconstruction method and a fast way to evaluate the non-uniform Fourier transform. The technical details are provided in the appendix A. Second, might be very large. For instance, the fastMRI knee training database contains more than 30 000 slices of size . Hence, it is impossible to compute the complete function and it is necessary to either pick a random, but otherwise fixed subset of the images, or to consider random batches that would vary from one iteration to the next. A similar comment holds for the noise term .
While Bayesian optimization allows the use of random functions, it requires evaluating expectations, i.e. integrals. This is typically achieved with Monte-Carlo methods, which is computationally costly. Hence, in all the forthcoming experiments, we will fix a subset of images. In practice, we observed that using random batches increases the computational load without offering perceptible advantages.
The interpolation process
In Bayesian optimization, a Gaussian process is used to model the underlying unknown function. This random process models both the function and the uncertainty associated with each prediction. This uncertainty is related to the fact that the function is evaluated only at a finite number of points hence leading to an unknown behavior when getting distant from the samples. It is also related to the fact that the function evaluations might be noisy. Every sampled point has a zero variance when using a fixed realization or a low variance when using random noise and batches. The variance increases with the distance between the sampled points.
In our experiments, the Gaussian process is constructed using a Matern kernel of parameter , which is a popular choice for dimensions in the range . It is defined as
where is a scaling parameter that controls the smoothness of the interpolant and its point-wise variance. In practice, the value of is a parameter that is optimized at each iteration when fitting the Gaussian process to the sampled data.
The interpolant mean and its variance are then evaluated by solving a linear system constructed using the kernel and the sampled points . We refer to Frazier (2018) for more details.
Sampling new points
Bayesian optimization works by iteratively sampling new points. The point in the sampling set with lowest function value, is an approximation of the minimizer. To choose a new point, there is a trade-off between finding a better minimizer in the neighborhood of this point and space exploration. Indeed, big gaps in between the samples could hide a better minimizer. This trade-off is managed through a so-called utility function. In this work, we chose the expected improvement Frazier (2018), resulting in a new function . The new sampled point is found by solving a constrained non-convex problem:
Since the function is non-convex, we use a multi-start strategy. We first sample points evenly in using a maximin design. Then, we launch many projected gradient descents on in parallel, starting from those points. Notice that the gradient is evaluated with respect to the surrogate interpolation function, and not with respect to the target density. The best critical point is chosen and added as a new sample.
This process requires projecting on defined in (10). To this end, we designed an efficient first order solver.
3 Numerical experiments and results
3.1 The experimental setting
Database and computing power
Throughout this section, we used the fastMRI database Zbontar et al. (2018). It contains MRI images of size . We focused on the single coil and fully sampled knee images. The training set is composed of 3D volumes, which represents a total of slices. The validation set has volumes and slices.
Some images in the dataset have a significant amount of noise. This presents three significant drawbacks: i) the high-frequency contents of the images is increased artificially promoting sampling schemes making it possible to reconstruct noise, ii) the signal-to-noise-ratio of the reconstructed images is decreased artificially and iii) we have shown that noise can dramatically impact the convergence of off-the-grid Fourier sampling optimization Gossard et al. (2022). To mitigate these effects, we pre-processed all the slices using a non-local mean denoising algorithm Buades et al. (2011).
The experiments are conducted on the Jean-Zay HPC facility. For each task we use cores and an Nvidia Tesla V100 with 16GB of memory.
Sampling
The bounds of the constraint sets in (3) are given by:
| (13) |
where is the sampling step of the scanner. Following Chaithya et al. (2022), we used the following realistic hardware constraints: mT/m, T/m/s, and MHz/T. The value of is fixed to ensure that at maximal speed, the distance between two consecutive points equals the Shannon-Nyquist rate Lazarus et al. (2020).
We consider two different scenarii: and undersampling. Each shot consists of acquisition points and we use shots and shots respectively for the and the undersampling. Each shot is constrained to start at the center of the k-space. The first few points of each trajectory are fixed to be radial, see Appendix A.5.4 for the technical details.
The family of densities is generated using the process described in Section 2.3.3 with densities generated at random.
Sampling baseline
All the optimized schemes are compared to a state-of-the-art handcrafted baseline: the Sparkling method described in Lazarus et al. (2019). There, the attraction-repulsion problem (11) is solved with a radial density constructed with a lot of care. Its value at the center has been optimized to yield the best possible signal-to-noise ratio on the validation set in a way similar to Chaithya et al. (2021). The corresponding point configuration is given in Fig. 7(a) and Fig. 7(b) for the and undersampling rates respectively. It provides a dB improvement compared to the usual radial lines commonly found in the literature (see the first two rows of Table 3).
Image reconstruction
The experiments are conducted with two reconstruction models:
- •
- •
an unrolled network (NN) with iterations of ADMM and a DruNet as the denoising step Zhang et al. (2021), iterations of the CG algorithm that initializes the ADMM and iterations of CG to solve the data-consistency equations at each iteration.
The parameter was optimized to get the best mean square error for the baseline scheme and the number of iterations in the algorithms was chosen optimaly with respect to the reconstruction quality and the available memory on a GPU.

![[Uncaptioned image]](/papers/2023:009/x13.png)
![[Uncaptioned image]](/papers/2023:009/x14.png)
![[Uncaptioned image]](/papers/2023:009/x15.png)
3.2 Choosing a kernel for the discrepancy
In all the previous “Sparkling” papers Lazarus et al. (2019); Chauffert et al. (2017), the kernel function was used. This choice seems like the most natural alternative since it is the only one which is scale invariant in the unconstrained setting. This means that if and if a density is dilated by a certain factor, then so is the optimal sampling scheme. However, this property is not true anymore when constraints are added. In that case, the choice of kernel turns out to be of importance.
To illustrate this fact, we considered the three different radial kernels , and . As can be seen on Fig. 6(a), performance variations of more than dB in average are obtained depending on the kernel. The reason is that contiguous points on the trajectories are spaced more or less depending on this choice. For instance, observe that the points on the zoom of Fig. 6(a) are more packed along the trajectories that on Fig. 6(c). To compensate for this higher longitudinal density, the sampler then increases the distance between adjacent trajectories, thereby creating holes in the sampling set. This is detrimental, since low frequency information is lost in the process. This effect can be quantified by evaluating the distances between contiguous points in the k-space center. As can be seen, it goes from for the usual kernel to a significantly higher value for the logarithmic kernel. The latter kernel creates a higher repulsion for neighboring points.
![[Uncaptioned image]](/papers/2023:009/x20.png)
![[Uncaptioned image]](/papers/2023:009/x21.png)
![[Uncaptioned image]](/papers/2023:009/x23.png)
![[Uncaptioned image]](/papers/2023:009/x24.png)
![[Uncaptioned image]](/papers/2023:009/x26.png)
![[Uncaptioned image]](/papers/2023:009/x27.png)
3.3 Bayesian optimization: database size and numerical complexity
In this section, we aim at evaluating the computational complexity of the Bayesian optimization routine. To this end, we study the impact of the number of images in the dataset, the size of the initial sampling set and the number of iterations, which are governing the algorithm’s complexity. Table 1 and 2 summarize our main findings for the total variation reconstruction and unrolled neural network.
In Table 1, we see that the number of images in the dataset has nearly no influence on the quality of the final sampling density. Taking or images yields an identical PSNR on the validation set. This holds both for the 25% and 10% undersampling rates. As can be seen in the Tables, reconstructing as little as images is enough to reach the best possible density in the family. The same conclusion holds for the undersampling rate. This represents of a single epoch.
We also see that the initial sampling set of the convex plays a marginal role on the quality of the final result. In addition, taking a small number of initial points allows us to reduce the overall complexity of the algorithm to reach a given PSNR.
Finally, Table 2 allows us to conclude that taking a database of or images has only a marginal influence on the computing times (3 hours instead of 4 hours) of the Bayesian optimization routine. This feature is related to the fact that a significant amount of time is spent in the minimization of , whose numerical cost is independent of the number of images. Hence, the fact that the algorithm seems to perform well for images is advantageous mostly when only small datasets can be generated.
| Recon. | init. points | evaluations | average PSNR images | average PSNR images | average PSNR images |
| TV | dB | dB | dB | ||
| TV | dB | dB | dB | ||
| TV | dB | dB | dB | ||
| NN | dB | dB | dB | ||
| NN | dB | dB | dB | ||
| NN | dB | dB | dB |
3.4 Comparing optimization routines for the total variation reconstructor
In what follows, we aim at comparing two different sampling optimization approaches:
- Trajectory optimization
- BO density
The Bayesian approach to minimize (6) globally.
To compare these approaches, we conduct various experiments. The corresponding results are shown in Table 2, Table 3 and Fig 7(a). Below, we summarize our main findings.
Qualitative comparison of the sampling schemes
In this paragraph, we compare our method with existing works Wang et al. (2022); Weiss et al. (2021). The optimized sampling schemes are shown in Fig. 7(a) for the TV reconstructor. In Fig. 7(a), we see the results of the different optimization routines.
The two optimization methods yield anisotropic sampling schemes with a higher density along the vertical axis. However the trajectories present significant differences.
The Bayesian optimization yields a sampling scheme which covers the space more uniformly. The trajectories have a significantly higher curvature at the k-space center. These features are somehow hard-coded within the sampling generator described in Section 2.3.4.
The trajectory optimization yields trajectories which are locally linear and aligned at a distance of about a pixel. This suggests that the trajectory optimization favors Shannon’s sampling rate at the center of the k-space. A potential explanation is as follows. When the sampling points are close to a subgrid Gossard et al. (2022), the adjoint of the forward operator is roughly the pseudo-inverse. Using a points configuration close to a subgrid therefore helps iterative reconstruction algorithms to converge.
Finally, at the bottom-left of the zoomed region on the 25% undersampling rate, it seems that Bayesian optimization (Fig. 7(c)) yields a density slightly higher than trajectory optimization (Fig. 7(e)). This density is critical for the reconstruction quality and might explain a part of the quantitative differences observed in the next section.
| Method | Computational time TV | Computational time NN |
| Trajectory optimization | h | h |
| 14 epochs | ||
| Bayesian optimization | ||
| Optimization | h | h |
| Optimization | h | h |
Performance comparison
Table 3 reveals that the trajectory optimization yields better performance in average than the Bayesian optimization approach both for the 25% (dB) and 10% (dB) undersampling rates. This was to be expected since the density optimization is much more constrained. The difference is however mild.
In Fig. 8, we display some images which benefited the least (resp. the most) from the sampling scheme optimization, with respect to the baseline. For the total variation reconstructor, some images actually suffer from the sampling scheme optimization as can be seen on the left of the picture. However, they correspond to slices which are not dominant in the dataset. On the other hand, the images that benefit the most from trajectory optimization correspond to central slices, prevalent in the set. As for the neural network, the best increases are obtained with the outer slices, which could be due to the large constant areas, the network is able to reproduce easily. Finally, the largest decreases for the neural network as a reconstruction mapping are not clearly associated to a specific type of slice.
| Method | ||
| Radial scheme | dB | dB |
| Sparkling radial (baseline) | dB | dB |
| Bayesian optim. | dB () | dB () |
| Trajectory optim. | dB () | dB () |
| Trajectory optim. | dB () | dB () |
| Trajectory optim. | dB () | dB () |
Computing times
Table 2 gives the computation times for each method with the total variation reconstruction method. The proposed approach has the significant advantage of giving an optimized sampling scheme with guarantees on the underlying density with a reduced computational budget and with a reduced number of images. As can be seen, our approach requires only images and 3 hours. This has to be compared to the 85 hours (3 days and a half) needed by the trajectory optimization routine.
This feature is a significant advantage of our approach. It could be key element when targeting high resolution images or 3D data.
Size of the training set
As advertised, the Bayesian optimization approach works even for small datasets. The trajectory optimization routine also provides competitive results with only images in the training set. However, the performance collapses for the undersampling rate. Increasing the size of the training set to does not improve the situation. This feature is in strong favor of our approach, when having access to a limited dataset.
BO TV | |||||||
TO TV | |||||||
BO NN | |||||||
TO NN | |||||||
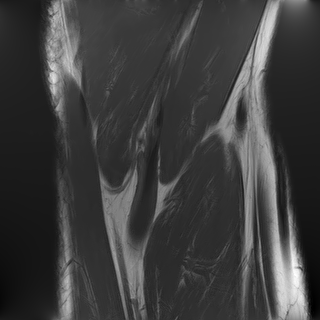
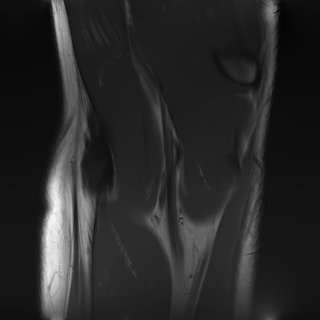

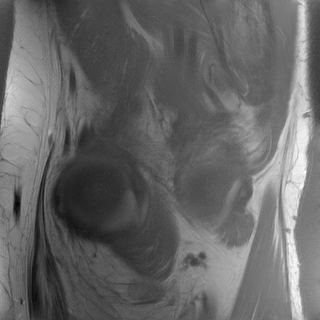
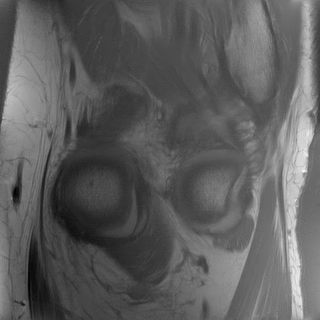
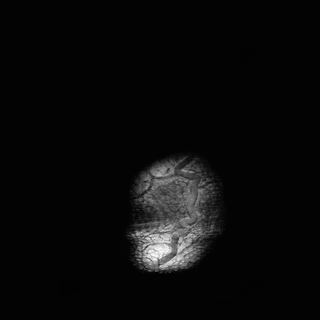
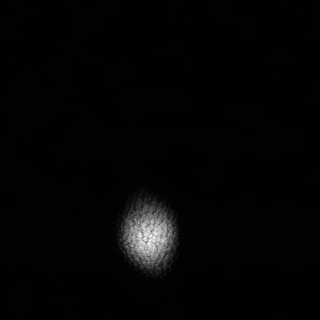
3.5 Comparing optimization routines for a neural network reconstructor
The aim of this section, is to compare three different sampling optimizers:
- •
The Bayesian density optimization solver proposed in this paper.
- •
The trajectory optimization solver with a fixed unrolled neural network trained on a family of sampling schemes, see Appendix A.3. This is a novelty of this paper.
- •
Qualitative comparisons
The differences between the density optimization and the trajectory optimization can be observed on Fig. 9(a). They are much more pronounced than for the total variation reconstructor. Surprisingly, the trajectory optimized sampling schemes leave large portions of the low frequencies unexplored. Hence, it seems that the unrolled network is able to infer low frequency information better than the traditional total variation prior. This suggests that the existing compressed sampling theories designed for the Fourier-Wavelet system have to be revised significantly to account for the progress in neural network reconstructions. The optimization of a trajectory for a fixed sampling scheme or the joint optimization yield qualitatively similar trajectories, with perhaps larger unexplored parts of the k-space for the fixed reconstruction method.
Quantitative comparisons
| Method | ||
| Baseline with unrolled net | dB | dB |
| BO scheme with unrolled net | dB () | dB () |
| Traj. optim. with fixed unrolled net | dB () | dB () |
| Joint optim. multi-scale | dB () | dB () |
Table 4 allows comparing the different methods quantitatively. BO yields a PSNR increase almost twice lower than the multi-scale optimization (+0.94dB VS +1.83dB for 25% and +0.64dB VS +1.16dB for 10%). This can likely be explained by the fact that the chosen family of densities (dimension 20) is unable to reproduce the complexity of the optimized trajectories. It is possible that richer sampling densities could reduce the gap between both approaches. However, Bayesian optimization is known to work only in small dimension and it is currently unclear how to extend the method to this setting.
Interestingly, the trajectory optimized with a fixed unrolled neural network trained on a family provides slightly better results (dB) than the joint optimization. This suggests that the joint optimization gets trapped in a local minimizer since it can only be better if optimized jointly with the reconstructor.
![[Uncaptioned image]](/papers/2023:009/x32.png)
![[Uncaptioned image]](/papers/2023:009/x33.png)
![[Uncaptioned image]](/papers/2023:009/x35.png)
![[Uncaptioned image]](/papers/2023:009/x36.png)
![[Uncaptioned image]](/papers/2023:009/x38.png)
![[Uncaptioned image]](/papers/2023:009/x39.png)
4 Conclusion
In this work, we designed efficient optimization algorithms that either optimize trajectories directly or learn a sampling density and an associated sampling pattern in MRI. Overall, the main highlights of this work are:
- •
The compressed sensing theories designed for the Fourier-Wavelet system with reconstruction (e.g. Adcock and Hansen (2021)) seem nearly optimal from an experimental point of view. Sampling schemes can be designed based on a density that is close to Shannon’s rate at the k-space center and that decays towards the high frequencies. The precise shape of the density depends on the images structure.
- •
In that context, the Bayesian optimization of densities is an attractive method to design sampling schemes. It works with small datasets, ensures the convergence to a global minimizer. Its performance is close to much heavier trajectory optimizers and is from one to two orders of magnitude faster.
- •
In the case of unrolled neural network reconstructions, the proposed Bayesian optimization framework is still interesting with gains of up to dB in average on the fastMRI knee validation set. However, the gain can be nearly doubled with a direct optimization of the trajectories. A possible explanation for this fact is that the family of densities is too poor to describe the best convoluted trajectories. Another one is that the theoretical bases of the compressed sensing theory break down when using neural network reconstruction methods. This calls for a renewed theory for this fast expanding field.
- •
As points of minor importance, we improved the Sparkling trajectories Lazarus et al. (2019), by changing the discrepancies and provided various improvements to the direct optimization of trajectories by using the Extra-Adam algorithm to handle hard constraints and by training reconstruction networks on families of operators.
- •
As a prospect, the extensions of these ideas to 3D multi-coil imaging is particularly relevant. There is no a priori obstacle to apply this rather lightweight formalism and to obtain dataset tailored sampling distributions.
Acknowledgments
P. Weiss and F. de Gournay were supported by the ANR JCJC Optimization on Measures Spaces ANR-17-CE23-0013-01 and the ANR-P3IA-0004 Artificial and Natural Intelligence Toulouse Institute. This work was granted access to the HPC resources of IDRIS under the allocation AD011012210 made by GENCI.
Ethical Standards
The work follows appropriate ethical standards in conducting research and writing the manuscript, following all applicable laws and regulations regarding treatment of animals or human subjects.
Conflicts of Interest
We declare we don’t have conflicts of interest.
References
- Adcock and Hansen (2021) Ben Adcock and Anders C Hansen. Compressive Imaging: Structure, Sampling, Learning. Cambridge University Press, 2021.
- Adcock et al. (2017) Ben Adcock, Anders C Hansen, Clarice Poon, and Bogdan Roman. Breaking the coherence barrier: A new theory for compressed sensing. In Forum of Mathematics, Sigma, volume 5. Cambridge University Press, 2017.
- Adcock et al. (2020) Ben Adcock, Claire Boyer, and Simone Brugiapaglia. On oracle-type local recovery guarantees in compressed sensing. Information and Inference: A Journal of the IMA, 2020.
- Aggarwal and Jacob (2020) Hemant Kumar Aggarwal and Mathews Jacob. J-modl: Joint model-based deep learning for optimized sampling and reconstruction. IEEE Journal of Selected Topics in Signal Processing, 2020.
- Ahn et al. (1986) CB Ahn, JH Kim, and ZH Cho. High-speed spiral-scan echo planar NMR imaging-I. IEEE Transactions on Medical Imaging, 5(1):2–7, 1986.
- Bahadir et al. (2020) Cagla Bahadir, Alan Wang, Adrian Dalca, and Mert R Sabuncu. Deep-learning-based optimization of the under-sampling pattern in mri. IEEE Transactions on Computational Imaging, 2020.
- Balandat et al. (2020) Maximilian Balandat, Brian Karrer, Daniel R. Jiang, Samuel Daulton, Benjamin Letham, Andrew Gordon Wilson, and Eytan Bakshy. BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization. In Advances in Neural Information Processing Systems 33, 2020.
- Baldassarre et al. (2016) Luca Baldassarre, Yen-Huan Li, Jonathan Scarlett, Baran Gözcü, Ilija Bogunovic, and Volkan Cevher. Learning-based compressive subsampling. IEEE Journal of Selected Topics in Signal Processing, 10(4):809–822, 2016.
- Bernstein et al. (2004) Matt A Bernstein, Kevin F King, and Xiaohong Joe Zhou. Handbook of MRI pulse sequences. Elsevier, 2004.
- Blaimer et al. (2004) Martin Blaimer, Felix Breuer, Matthias Mueller, Robin M Heidemann, Mark A Griswold, and Peter M Jakob. Smash, sense, pils, grappa: how to choose the optimal method. Topics in Magnetic Resonance Imaging, 15(4):223–236, 2004.
- Boyer et al. (2016) Claire Boyer, Nicolas Chauffert, Philippe Ciuciu, Jonas Kahn, and Pierre Weiss. On the generation of sampling schemes for magnetic resonance imaging. SIAM Journal on Imaging Sciences, 9(4):2039–2072, 2016.
- Boyer et al. (2019) Claire Boyer, Jérémie Bigot, and Pierre Weiss. Compressed sensing with structured sparsity and structured acquisition. Applied and Computational Harmonic Analysis, 46(2):312–350, 2019.
- Buades et al. (2011) Antoni Buades, Bartomeu Coll, and Jean-Michel Morel. Non-local means denoising. Image Processing On Line, 1:208–212, 2011.
- Candès et al. (2006) Emmanuel J Candès, Justin Romberg, and Terence Tao. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on information theory, 52(2):489–509, 2006.
- Chaithya et al. (2021) GR Chaithya, Zaccharie Ramzi, and Philippe Ciuciu. Learning the sampling density in 2d sparkling mri acquisition for optimized image reconstruction. In 2021 29th European Signal Processing Conference (EUSIPCO), pages 960–964. IEEE, 2021.
- Chaithya et al. (2022) GR Chaithya, Pierre Weiss, Guillaume Daval-Frérot, Aurélien Massire, Alexandre Vignaud, and Philippe Ciuciu. Optimizing full 3d sparkling trajectories for high-resolution magnetic resonance imaging. IEEE Transactions on Medical Imaging, 2022.
- Charlier et al. (2021) Benjamin Charlier, Jean Feydy, Joan Glaunès, François-David Collin, and Ghislain Durif. Kernel operations on the gpu, with autodiff, without memory overflows. Journal of Machine Learning Research, 22(74):1–6, 2021.
- Chauffert et al. (2016) Nicolas Chauffert, Pierre Weiss, Jonas Kahn, and Philippe Ciuciu. A projection algorithm for gradient waveforms design in magnetic resonance imaging. IEEE transactions on medical imaging, 35(9):2026–2039, 2016.
- Chauffert et al. (2017) Nicolas Chauffert, Philippe Ciuciu, Jonas Kahn, and Pierre Weiss. A projection method on measures sets. Constructive Approximation, 45(1):83–111, 2017.
- Debarnot and Weiss (2022) Valentin Debarnot and Pierre Weiss. Deep-blur: Blind identification and deblurring with convolutional neural networks. 2022.
- Feichtinger and Gröchenig (1994) Hans G Feichtinger and Karlheinz Gröchenig. Theory and practice of irregular sampling. Wavelets: mathematics and applications, 1994:305–363, 1994.
- Fessler and Sutton (2003) Jeffrey A Fessler and Bradley P Sutton. Nonuniform fast fourier transforms using min-max interpolation. IEEE transactions on signal processing, 51(2):560–574, 2003.
- Frazier (2018) Peter I Frazier. A tutorial on bayesian optimization. arXiv preprint arXiv:1807.02811, 2018.
- Genzel et al. (2022) Martin Genzel, Ingo Gühring, Jan Macdonald, and Maximilian März. Near-exact recovery for tomographic inverse problems via deep learning. In International Conference on Machine Learning, pages 7368–7381. PMLR, 2022.
- Gidel et al. (2019) Gauthier Gidel, Hugo Berard, Gaëtan Vignoud, Pascal Vincent, and Simon Lacoste-Julien. A variational inequality perspective on generative adversarial networks. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=r1laEnA5Ym.
- Gossard and Weiss (2022) Alban Gossard and Pierre Weiss. Training adaptive reconstruction networks for inverse problems. arXiv preprint arXiv:2202.11342, 2022.
- Gossard et al. (2022) Alban Gossard, Frédéric de Gournay, and Pierre Weiss. Spurious minimizers in non uniform fourier sampling optimization. Inverse Problems, 2022.
- Gözcü et al. (2018) Baran Gözcü, Rabeeh Karimi Mahabadi, Yen-Huan Li, Efe Ilıcak, Tolga Çukur, Jonathan Scarlett, and Volkan Cevher. Learning-based compressive mri. IEEE transactions on medical imaging, 37(6):1394–1406, 2018.
- Gräf et al. (2012) Manuel Gräf, Daniel Potts, and Gabriele Steidl. Quadrature errors, discrepancies, and their relations to halftoning on the torus and the sphere. SIAM Journal on Scientific Computing, 34(5):A2760–A2791, 2012.
- Hammernik et al. (2018) Kerstin Hammernik, Teresa Klatzer, Erich Kobler, Michael P Recht, Daniel K Sodickson, Thomas Pock, and Florian Knoll. Learning a variational network for reconstruction of accelerated mri data. Magnetic resonance in medicine, 79(6):3055–3071, 2018.
- Jackson et al. (1992) John I Jackson, Dwight G Nishimura, and Albert Macovski. Twisting radial lines with application to robust magnetic resonance imaging of irregular flow. Magnetic Resonance in Medicine, 25(1):128–139, 1992.
- Jacob et al. (2020) Mathews Jacob, Jong Chul Ye, Leslie Ying, and Mariya Doneva. Computational mri: Compressive sensing and beyond [from the guest editors]. IEEE Signal Processing Magazine, 37(1):21–23, 2020.
- Jin et al. (2019) Kyong Hwan Jin, Michael Unser, and Kwang Moo Yi. Self-supervised deep active accelerated mri. arXiv preprint arXiv:1901.04547, 2019.
- Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547, 2019.
- Juditsky et al. (2011) Anatoli Juditsky, Arkadi Nemirovski, and Claire Tauvel. Solving variational inequalities with stochastic mirror-prox algorithm. Stochastic Systems, 1(1):17–58, 2011.
- Keiner et al. (2009) Jens Keiner, Stefan Kunis, and Daniel Potts. Using nfft 3—a software library for various nonequispaced fast fourier transforms. ACM Transactions on Mathematical Software (TOMS), 36(4):1–30, 2009.
- Knoll et al. (2011) Florian Knoll, Christian Clason, Clemens Diwoky, and Rudolf Stollberger. Adapted random sampling patterns for accelerated mri. Magnetic resonance materials in physics, biology and medicine, 24(1):43–50, 2011.
- Knoll et al. (2020) Florian Knoll, Tullie Murrell, Anuroop Sriram, Nafissa Yakubova, Jure Zbontar, Michael Rabbat, Aaron Defazio, Matthew J Muckley, Daniel K Sodickson, C Lawrence Zitnick, et al. Advancing machine learning for mr image reconstruction with an open competition: Overview of the 2019 fastmri challenge. Magnetic Resonance in Medicine, 2020.
- Korkmaz et al. (2022) Yilmaz Korkmaz, Salman UH Dar, Mahmut Yurt, Muzaffer Özbey, and Tolga Cukur. Unsupervised mri reconstruction via zero-shot learned adversarial transformers. IEEE Transactions on Medical Imaging, 41(7):1747–1763, 2022.
- Lazarus et al. (2019) Carole Lazarus, Pierre Weiss, Nicolas Chauffert, Franck Mauconduit, Loubna El Gueddari, Christophe Destrieux, Ilyess Zemmoura, Alexandre Vignaud, and Philippe Ciuciu. Sparkling: variable-density k-space filling curves for accelerated t2*-weighted mri. Magnetic resonance in medicine, 81(6):3643–3661, 2019.
- Lazarus et al. (2020) Carole Lazarus, Maximilian März, and Pierre Weiss. Correcting the side effects of adc filtering in mr image reconstruction. Journal of Mathematical Imaging and Vision, pages 1–14, 2020.
- Lebrat et al. (2019) Léo Lebrat, Frédéric de Gournay, Jonas Kahn, and Pierre Weiss. Optimal transport approximation of 2-dimensional measures. SIAM Journal on Imaging Sciences, 12(2):762–787, 2019.
- Lustig et al. (2005) Michael Lustig, Jin Hyung Lee, David L Donoho, and John M Pauly. Faster imaging with randomly perturbed, under-sampled spirals and reconstruction. In Proceedings of the 13th annual meeting of ISMRM, page 685, Miami Beach, FL, USA, 2005.
- Lustig et al. (2008) Michael Lustig, David L Donoho, Juan M Santos, and John M Pauly. Compressed sensing mri. IEEE signal processing magazine, 25(2):72–82, 2008.
- Muckley et al. (2020) Matthew J Muckley, Ruben Stern, Tullie Murrell, and Florian Knoll. Torchkbnufft: a high-level, hardware-agnostic non-uniform fast fourier transform. In ISMRM Workshop on Data Sampling & Image Reconstruction, 2020.
- Muckley et al. (2021) Matthew J Muckley, Bruno Riemenschneider, Alireza Radmanesh, Sunwoo Kim, Geunu Jeong, Jingyu Ko, Yohan Jun, Hyungseob Shin, Dosik Hwang, Mahmoud Mostapha, et al. Results of the 2020 fastmri challenge for machine learning mr image reconstruction. IEEE transactions on medical imaging, 40(9):2306–2317, 2021.
- Nesterov (1983) Yurii E Nesterov. A method for solving the convex programming problem with convergence rate o (1/k^ 2). In Dokl. akad. nauk Sssr, volume 269, pages 543–547, 1983.
- Ng et al. (2010) Michael K Ng, Pierre Weiss, and Xiaoming Yuan. Solving constrained total-variation image restoration and reconstruction problems via alternating direction methods. SIAM journal on Scientific Computing, 32(5):2710–2736, 2010.
- Ochs et al. (2015) Peter Ochs, René Ranftl, Thomas Brox, and Thomas Pock. Bilevel optimization with nonsmooth lower level problems. In International Conference on Scale Space and Variational Methods in Computer Vision, pages 654–665. Springer, 2015.
- Pronzato (2017) Luc Pronzato. Minimax and maximin space-filling designs: some properties and methods for construction. Journal de la Société Française de Statistique, 158(1):7–36, 2017.
- Roemer et al. (1990) Peter B Roemer, William A Edelstein, Cecil E Hayes, Steven P Souza, and Otward M Mueller. The nmr phased array. Magnetic resonance in medicine, 16(2):192–225, 1990.
- Sanchez et al. (2020) Thomas Sanchez, Baran Gözcü, Ruud B van Heeswijk, Armin Eftekhari, Efe Ilıcak, Tolga Çukur, and Volkan Cevher. Scalable learning-based sampling optimization for compressive dynamic mri. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8584–8588. IEEE, 2020.
- Schmaltz et al. (2010) Christian Schmaltz, Pascal Gwosdek, Andrés Bruhn, and Joachim Weickert. Electrostatic halftoning. In Computer Graphics Forum, volume 29, pages 2313–2327. Wiley Online Library, 2010.
- Schmitt et al. (2012) Franz Schmitt, Michael K Stehling, and Robert Turner. Echo-planar imaging: theory, technique and application. Springer Science & Business Media, 2012.
- Sherry et al. (2020) Ferdia Sherry, Martin Benning, Juan Carlos De los Reyes, Martin J Graves, Georg Maierhofer, Guy Williams, Carola-Bibiane Schönlieb, and Matthias J Ehrhardt. Learning the sampling pattern for mri. IEEE Transactions on Medical Imaging, 2020.
- Shih et al. (2021) Yu-hsuan Shih, Garrett Wright, Joakim Andén, Johannes Blaschke, and Alex H Barnett. cufinufft: a load-balanced gpu library for general-purpose nonuniform ffts. In 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 688–697. IEEE, 2021.
- Vasanawala et al. (2011) SS Vasanawala, MJ Murphy, Marcus T Alley, P Lai, Kurt Keutzer, John M Pauly, and Michael Lustig. Practical parallel imaging compressed sensing mri: Summary of two years of experience in accelerating body mri of pediatric patients. In 2011 IEEE international symposium on biomedical imaging: From nano to macro, pages 1039–1043. IEEE, 2011.
- Wang and Fessler (2021) Guanhua Wang and Jeffrey A Fessler. Efficient approximation of jacobian matrices involving a non-uniform fast fourier transform (nufft). arXiv preprint arXiv:2111.02912, 2021.
- Wang et al. (2022) Guanhua Wang, Tianrui Luo, Jon-Fredrik Nielsen, Douglas C Noll, and Jeffrey A Fessler. B-spline parameterized joint optimization of reconstruction and k-space trajectories (bjork) for accelerated 2d mri. IEEE Transactions on Medical Imaging, 2022.
- Weiss et al. (2021) Tomer Weiss, Ortal Senouf, Sanketh Vedula, Oleg Michailovich, Michael Zibulevsky, and Alex Bronstein. Pilot: Physics-informed learned optimal trajectories for accelerated mri. Journal of Machine Learning for Biomedical Imaging (MELBA), pages 1–23, 2021.
- Yu et al. (2019) Songhyun Yu, Bumjun Park, and Jechang Jeong. Deep iterative down-up cnn for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.
- Zbontar et al. (2018) Jure Zbontar, Florian Knoll, Anuroop Sriram, Tullie Murrell, Zhengnan Huang, Matthew J Muckley, Aaron Defazio, Ruben Stern, Patricia Johnson, Mary Bruno, et al. fastmri: An open dataset and benchmarks for accelerated mri. arXiv preprint arXiv:1811.08839, 2018.
- Zhang et al. (2021) Kai Zhang, Yawei Li, Wangmeng Zuo, Lei Zhang, Luc Van Gool, and Radu Timofte. Plug-and-play image restoration with deep denoiser prior. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- Zhang et al. (2014) Yudong Zhang, Bradley S Peterson, Genlin Ji, and Zhengchao Dong. Energy preserved sampling for compressed sensing mri. Computational and mathematical methods in medicine, 2014, 2014.
- Zibetti et al. (2022) Marcelo Victor Wust Zibetti, Florian Knoll, and Ravinder R Regatte. Alternating learning approach for variational networks and undersampling pattern in parallel mri applications. IEEE Transactions on Computational Imaging, 8:449–461, 2022.
- Zibetti et al. (2021) Marcelo VW Zibetti, Gabor T Herman, and Ravinder R Regatte. Fast data-driven learning of parallel mri sampling patterns for large scale problems. Scientific Reports, 11(1):1–19, 2021.
A Implementation details
A.1 TV reconstruction algorithm
In this part we detail the TV iterative reconstruction algorithm that is used in this paper. We consider a regularized version of the total variation of the form
Given , the solver of problem (2) is given in Algorithm 1. The parameter drives the acceleration and is the dimension, here . It corresponds to a Nesterov accelerated gradient descent Nesterov (1983) with a regularized version of the norm.
A critical point is the choice of the step in Algorithm 1. This step is computed using the spectral norm of the data fidelity term which can be computed using a power iteration method for each point configuration . The resulting step is taken into account in the computation of the gradient with respect to the locations of the cost function in (4).
A.2 The unrolled neural network
The neural network based reconstruction is an unrolled network. The one used in this work is based on the ADMM (Alternative Descent Method of Multipliers) Ng et al. (2010). It consists in alternating a regularized inverse followed by a denoising step with a neural network. If denotes the denoiser used at iteration , the unrolled ADMM can be expressed through the sequence:
with a pseudo-inverse initialization .
In this work, we use the DruNet network Zhang et al. (2021) to define the denoising mappings . We choose an ADMM algorithm for the following reasons:
- 1.
for well-spread sampling schemes, the matrix has a good conditioning and the linear system that has to be inverted can be solved in less than a dozen iterations,
- 2.
it has demonstrated great performance to solve linear inverse problems in imaging, including image reconstruction from Fourier samples Wang et al. (2022).
We opted for a different network at each iteration instead of a network that shares its weights accross all iterations. This leads to slightly higher performance at the price of a slightly harder to interpret architecture (see e.g. Genzel et al. (2022) for a similar discussion in CT reconstruction).
A.3 Training the reconstruction network for a family of operators
Following Gossard and Weiss (2022), we trained our network in a non usual way. Instead of training the denoising networks for a single operator , we actually trained it for a whole family of operators , where is a large family of sampling schemes. We showed in Gossard and Weiss (2022), that this simple approach yields a much more robust network, which is adaptive to the forward operator.
In our experiments, the network is trained on a family of sampling schemes that are generated using the attraction-repulsion minimization problem (11). These schemes are parameterized by densities that are within . This pretraining step consists of epochs with a batch of images using the Adam optimizer with default parameters ( and ). The step for the CNN weights is set to with a multiplicative update of after each epoch. The measurements are perturbed by an additive white noise (see in (4)).
A.4 Joint optimization
Instead of optimizing the sampling scheme for a fixed network, we can also optimize jointly the sampling locations together with the network weights. This approach was proposed in Wang et al. (2022); Weiss et al. (2021). Due to memory requirements, we set the batch size to for the unrolled network in our training procedure. The step size for the CNN weights in this experiment is also set to with the default Adam parameters.
A.5 Computational details
In this paragraph, we describe the main technical tools used to optimize the reconstruction process.
A.5.1 Solving the particle problem (4)
Problem (4) is a highly non-trivial problem. Two different computational solutions were proposed in Weiss et al. (2021); Wang et al. (2022). In this work, we re-implemented a solver with some differences outlined below.
First, the optimization problem (4) involves a nontrivial constraint set . While the mentioned works use a penalization over the constraints, we enforce the constraints by using a projection at each iteration. Handling constraints in stochastic optimization was first dealt with stochastic mirror-prox algorithms Juditsky et al. (2011). This approach turned out to be inefficient in practice. We therefore resorted to an extension of Adam in the constrained case called Extra-Adam Gidel et al. (2019). The step size was set to and the default Adam parameters and . We observed no significant difference by tuning these last two parameters. We also use a step decay of each fourth of epoch and batch size of , which is the largest achievable by our GPU.
Similarly to Weiss et al. (2021); Wang et al. (2022), we use a multi-scale strategy. The trajectories are defined through a small number of control points, that progressively increases across iterations. We simply use a piecewise linear discretization (contrarily to higher order splines in Wang et al. (2022)). The initial decimation factor is and is divided by two every two epochs. This results in a total number of epochs equal to and takes about 86 hours for a total variation solver. In comparison Wang et al. (2022), reports a total of epochs.
A.5.2 Implementing the Non-uniform Fourier Transform (NUFT)
Various fast implementations of the Non-uniform Fourier Transform (1) are now available Keiner et al. (2009); Fessler and Sutton (2003); Shih et al. (2021); Muckley et al. (2020). In this work, we need a pyTorch library capable of backward differentiation. Evaluating the gradient of the cost function in (4) or in (6) indeed requires computing the differential of the forward operator with respect to . This can be done by computing non-uniform Fourier transforms (see Wang et al. (2022); Gossard et al. (2022); Wang and Fessler (2021)). Different packages were tested and we finally opted for the cuFINUFFT implementation Shih et al. (2021). The bindings for different kind of NUFT are available at https://github.com/albangossard/Bindings-NUFFT-pytorch/.
A.5.3 Minimizing the discrepancy
The minimization of the discrepancy (11) is achieved with a gradient descent, as was proposed in the original paper Schmaltz et al. (2010), see Algorithm 2. The input parameters are the initial sampling set , the target density and a step-size . The step size needs to be carefully chosen to ensure a fast convergence. The optimal choice can be shown to be related to the minimal distance between adjacent points. In our experiments, it was tuned by hand and fixed respectively to and for the and undersampling schemes.
Computing the gradient requires to compute pairwise interactions between all particles: in our codes, it is achieved using PyKeOps Charlier et al. (2021). This approach presents the advantages of being fast, adapting to arbitrary kernels and to natively allow backward differentiation within PyTorch. For a number of particles above , fast multipole methods might become preferable Chaithya et al. (2022).
A.5.4 Handling the mass at 0
An important issue is related to the fact that all trajectories start at the k-space origin. This creates a large mass for the sampling scheme at 0. When minimizing a discrepancy between the sampling scheme and a target density, the sampling points are therefore repulsed from the origin, creating large holes at the center. To avoid this detrimental effect, we fix rectilinear radial trajectories at the origin at maximal acceleration until a distance of 0.5 pixel between adjacent trajectories samples is reached. This creates a fixed pattern in the k-space center, which can easily be seen in the zoom of Fig. 7(a) and Fig. 7(b). We compute the discrepancy only at the exterior of a disk centered at the origin containing this fixed pattern.
A.5.5 Projection onto the constraint set
The projector onto the constraint set is used twice in this work. First the Extra-Adam algorithm requires a Euclidean projector on the constraint set to solve (4). This projector is also needed to compute one evaluation of the sampler in (11). In this project, we used the dual approach proposed in Chauffert et al. (2016), implemented on a GPU. This algorithm can be implemented in PyTorch, and can be differentiated. This allows computing the gradient of the overall function in (6).