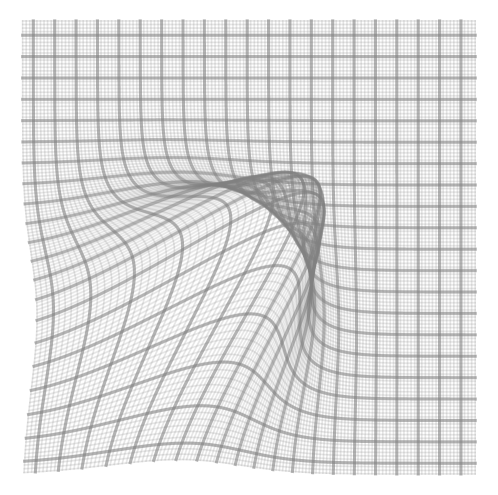
1 Introduction
Deformable medical image registration aims at finding a mapping between coordinate systems of two images, called a deformation, to align them anatomically. Deep learning can be used to train a registration network which takes as input two images and outputs a deformation. We focus on unsupervised intra-modality registration without a ground-truth deformation and where images are of the same modality, applicable, e.g., when deforming brain MRI images from different patients to an atlas or analyzing a patient’s breathing cycle from multiple images.
Success of the most popular deep learning architectures is often seen through the desirable inductive biases imposed by suitable geometric priors (such as translation equivariance for CNNs) (Bronstein et al., 2017, 2021). In image registration priors of inverse consistency, symmetry, and topology preservation are widely considered to be useful (Sotiras et al., 2013). While some of the most popular classical methods enforce all of these properties by construction (Ashburner, 2007; Avants et al., 2008), no prior deep learning methods do, and we address this gap (see a detailed literature review in Appendix F). To clearly state our contributions, we start by defining the properties (further clarifications in Appendix J).
We define a registration method as a function that takes two images, say and , and produces a deformation. In general one can predict the deformation with any method in either direction by varying the input order, but some methods predict both forward and inverse deformations directly, and we use subscripts to indicate the direction for such methods. For example, produces a deformation that aligns the image of the first argument to the image of the second argument. Note that even if and both denote a deformation for aligning image to , they in general can be different functions. As a result, a registration method may predict up to four different deformations for any given input pair: , , , and . If a method predicts a deformation only in one direction for a given input order, we might omit the subscript.
Inverse consistent registration methods ensure that is an accurate inverse of , which we quantify using the inverse consistency error: , where is the composition operator and is the identity deformation. Inverse consistency has been enforced using a loss or by construction. However, due to a limited spatial resolution of the predicted deformations, even for the by construction inverse consistent methods the inverse consistency error is not exactly zero (Ashburner, 2007).
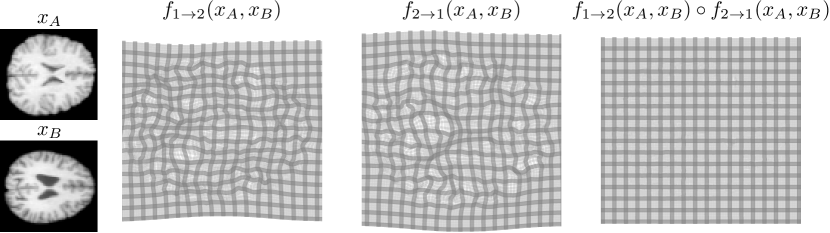
In symmetric registration, the registration outcome does not depend on the order of the inputs, i.e., equals . Unlike with inverse consistency, can equal exactly (Avants et al., 2008; Estienne et al., 2021), which we call symmetric by construction. A related property, cycle consistency, can be assessed using cycle consistency error . It can be computed for any method since it does not require the method to predict deformations in both directions. If the method is symmetric by construction, inverse consistency error equals cycle consistency error.
We define topology preservation of predicted deformations similarly to Christensen et al. (1995). From the real-world point of view this means the preservation of anatomical structures, preventing non-smooth changes. Mathematically we want the deformations to be homeomorphisms, i.e., invertible and continuous. In registration literature it is common to talk about diffeomorphims which are additionally differentiable. In practice we want a deformation not to fold on top of itself which we measure by estimating the local Jacobian determinants of the predicted deformations, and checking whether they are positive.
With these definitions at hand, we summarize our main contributions as follows:
- •
We propose a novel multi-resolution deep learning registration architecture which is by construction inverse consistent, symmetric, and preserves topology. The properties are fulfilled for the whole multi-resolution pipeline, not just separately for each resolution. Apart from the parallel works by (Greer et al., 2023; Zhang et al., 2023), we are not aware of other multi-resolution deep learning registration methods which are by construction both symmetric and inverse consistent. For motivation of the multi-resolution approach, see Section 2.4.
- •
As a component in our architecture, we propose an implicit neural network layer, which we call deformation inversion layer, based on a well-known fixed point iteration formula (Chen et al., 2008) and recent advances in Deep Equilibrium models (Bai et al., 2019; Duvenaud et al., 2020). The layer allows memory efficient inversion of deformation fields.
- •
We show that the method achieves state-of-the-art results on two brain subject-to-subject registration datasets, and state-of-the-art results for deep learning methods on inspiration-exhale registration of lung CT scans.
We name the method SITReg after its symmetricity, inverse consistency and topology preservation properties.
2 Background and preliminaries
2.1 Topology preserving registration
The diffeomorphic LDDMM framework (Cao et al., 2005) was the first approach suggested for by construction topology preserving registration. The core idea was to generate diffeomorphisms through integration of time-varying velocity fields constrained by certain differential equations. Arsigny et al. (2006) suggested more constrained but computationally cheaper stationary velocity field (SVF) formulation and it was later adopted by popular registration algorithms (Ashburner, 2007; Vercauteren et al., 2009). While some unsupervised deep learning methods do use the LDDMM approach for generating topology preserving deformations (Shen et al., 2019b; Ramon et al., 2022; Wang et al., 2023), most commonly (Chen et al., 2023) topology preservation in unsupervised deep learning is achieved using the more efficient SVF formulation, e.g. by Krebs et al. (2018, 2019); Niethammer et al. (2019); Shen et al. (2019a, b); Mok and Chung (2020a).
Another classical method by Choi and Lee (2000); Rueckert et al. (2006) generates topology preserving deformations by constraining each deformation to be diffeomorphic but small, and forming the final deformation as a composition of multiple small deformations. Since diffeomorphisms form a group under composition, the final deformation is diffeomorphic. The principle is close to a practical implementation of the SVF, where the velocity field is integrated by first scaling it down by a power of two and interpreting the result as a small deformation, which is then repeatedly composed with itself. The idea is hence similar: a composition of small deformations.
In this work we build topology preserving deformations using the same strategy, as a composition of small topology preserving deformations.
2.2 Inverse consistent registration
Originally inverse consistency was achieved via variational losses (Christensen et al., 1995) but later LDDMM and SVF frameworks allowed for inverse consistent by construction methods since the inverse can be obtained by integrating the velocity field in the opposite direction. Both approaches are found among the deep learning methods as well, as some enforce inverse consistency via a penalty (Zhang, 2018; Kim et al., 2019; Estienne et al., 2021), and many use the SVF formulation as mentioned in Section 2.1.
Compared to the earlier deep learning approaches, we take a methodologically slightly different approach of using the proposed deformation inversion layer for building an inverse consistent architecture.
2.3 Symmetric registration
Symmetric registration methods consider both images equally: swapping the input order should not change the registration outcome. Developing symmetric registration methods has a long history (Sotiras et al., 2013), but one particularly relevant for this work is a method called symmetric normalization (SyN, Avants et al., 2008) which learns two separate transformations: one for deforming the first image half-way toward the second image and the other for deforming the second image half-way toward the first image. The images are matched in the intermediate coordinates and the full deformation is obtained as a composition of the half-way deformations (one of which is inverted). The same idea was applied in deep learning setting by SYMNet (Mok and Chung, 2020a). However, SYMNet does not guarantee symmetricity by construction during inference (see Figure 7 in Appendix H). Some existing deep learning registration methods enforce cycle consistency via a penalty (Mahapatra and Ge, 2019; Gu et al., 2020; Zheng et al., 2021), and the method by Estienne et al. (2021) is symmetric by construction but only for a single component of their multi-step formulation, and not inverse consistent by construction. Recently, parallel with and unrelated to us, Iglesias (2023); Greer et al. (2023); Zhang et al. (2023) have proposed by construction symmetric and inverse consistent registration methods within the SVF framework, in a different way from us.
We use the idea of deforming the images half-way towards each other to achieve symmetry throughout our multi-resolution architecture.
2.4 Multi-resolution registration
Multi-resolution registration methods learn the deformation by first estimating it in a low resolution and then incrementally improving it while increasing the resolution. For each resolution one feeds the input images deformed with the deformation learned thus far, and incrementally composes the full deformation. Since its introduction a few decades ago (Rueckert et al., 1999; Oliveira and Tavares, 2014), the approach has been used in the top-performing classical and deep learning registration methods (Avants et al., 2008; Klein et al., 2009; Mok and Chung, 2020b, 2021; Hering et al., 2022).
In this work we propose the first multi-resolution deep learning registration architecture that is by construction symmetric, inverse consistent, and topology preserving.
2.5 Deep equilibrium networks
Deep equilibrium networks use implicit fixed point iteration layers, which have emerged as an alternative to the common explicit layers (Bai et al., 2019, 2020; Duvenaud et al., 2020). Unlike explicit layers, which produce output via an exact sequence of operations, the output of an implicit layer is defined indirectly as a solution to a fixed point equation, which is specified using a fixed point mapping. In the simplest case the fixed point mapping takes two arguments, one of which is the input. For example, let be a fixed point mapping defining an implicit layer. Then, for a given input , the output of the layer is the solution to equation
| (1) |
This equation is called a fixed point equation and the solution is called a fixed point solution. If has suitable properties, the equation can be solved iteratively by starting with an initial guess and repeatedly feeding the output as the next input to . More advanced iteration methods have also been developed for solving fixed point equations, such as Anderson acceleration (Walker and Ni, 2011).
The main mathematical innovation related to deep equilibrium networks is that the derivative of an implicit layer w.r.t. its inputs can be calculated based solely on a fixed point solution, i.e., no intermediate iteration values need to be stored for back-propagation. Now, given some solution , such that , and assuming certain local invertibility properties for , the implicit function theorem says that there exists a solution mapping in the neighborhood of , which maps other inputs to their corresponding solutions. Let us denote the solution mapping as . The solution mapping can be seen as the theoretical explicit layer corresponding to the implicit layer. To find the derivatives of the implicit layer we need to find the Jacobian of at point which can be obtained using implicit differentiation as
The vector-Jacobian product of needed for back-propagation can be calculated using another fixed point equation without fully computing the Jacobians, see, e.g., Duvenaud et al. (2020). Hence, both forward and backward passes of the implicit layer can be computed as a fixed point iteration.
We use these ideas to develop a neural network layer for inverting deformations based on the fixed point equation, following Chen et al. (2008). The layer is very memory efficient as only the fixed point solution needs to be stored for the backward pass.
3 Methods
Let denote the dimensionality of the image, e.g., for 3D medical images, and the number of channels, e.g., for an RGB-image. The goal in deformable image registration is to find a mapping from to , connecting the coordinate systems of two non-aligned images , called a deformation. Application of a deformation to an image can be mathematically represented as a (function) composition of the image and the deformation, denoted by . Furthermore, in practice linear interpolation is used to represent images (and deformations) in continuous coordinates.
In this work the deformations are in practice stored as displacement fields with the same resolution as the registered images, that is, each pixel or voxel is associated with a displacement vector describing the coordinate difference between the original image and the deformed image (e.g. if , displacement field is tensor with shape where is the shape of the image). In our notation we equate the displacement fields with the corresponding coordinate mappings, and always use to denote the deformation operation (sometimes called warping).
In deep learning based image registration, we aim at learning a neural network that takes two images as input and outputs a mapping between the image coordinates. Specifically, in medical context should be such that matches anatomically with .
3.1 Symmetric formulation
As discussed in Section 1, we want our method to be cycle consistent. That is, since in the ideal case of finding the correct coordinate mapping between any given inputs and , and should be inverses of each other. Hence enforcing such a property by construction should provide a useful constraint on the optimization space. To achieve this, we define the network using another auxiliary network which also predicts deformations:
| (2) |
By defining this way, it holds by construction that apart from small numerical errors introduced by the composition and inversion. An additional benefit is that equals the identity transformation, again apart from numerical inaccuracies, which is a natural requirement for a registration method. Applying the formulation in Equation 2 naively would double the computational cost. To avoid this we encode features from the inputs separately before feeding them to the deformation extraction network in Equation 2. A similar approach has been used in recent registration methods (Estienne et al., 2021; Young et al., 2022). Denoting the feature extraction network by , the modified formulation is
| (3) |
3.2 Multi-resolution architecture
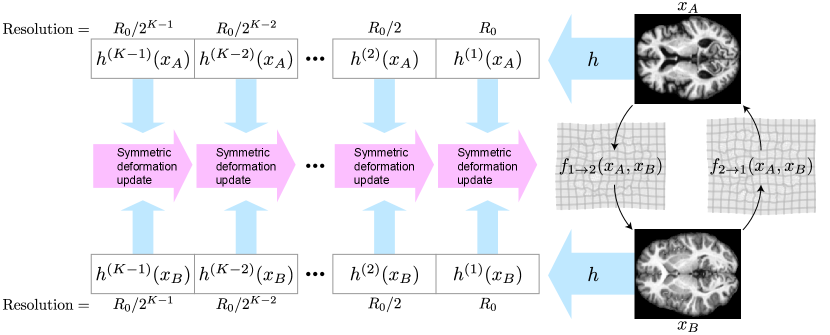
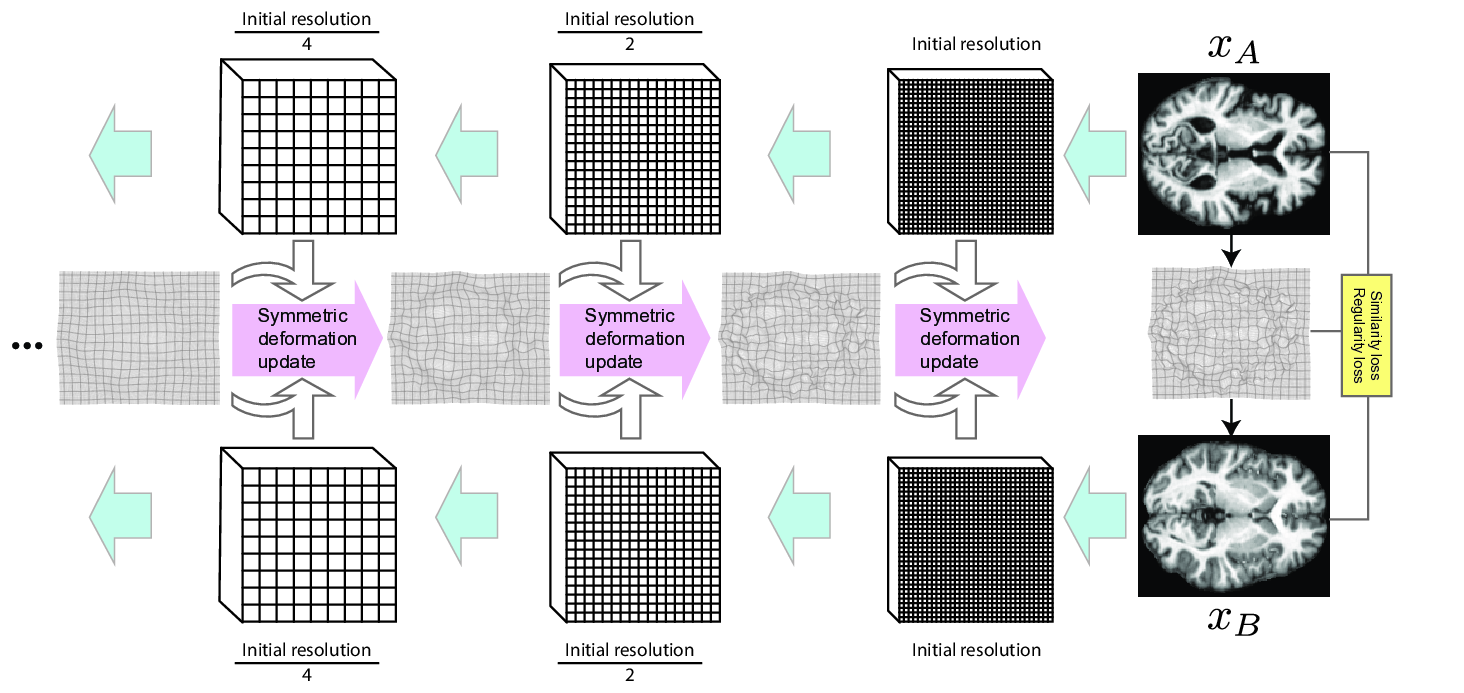
As the overarching architecture, we propose a novel symmetric and inverse consistent multi-resolution coarse-to-fine approach. For motivation, see Section 2.4. Overview of the architecture is shown in Figure 2, and the prediction process is demonstrated visually in Figure 10 (Appendix H).
First, we extract image feature representations , at different resolutions . Index is the original resolution and increasing by one halves the spatial resolution. In practice is a ResNet (He et al., 2016) style convolutional network and features at each resolution are extracted sequentially from previous features. Starting from the lowest resolution , we recursively build the final deformation between the inputs using the extracted representations. To ensure symmetry, we build two deformations: one deforming the first image half-way towards the second image, and the other for deforming the second image half-way towards the first image (see Section 2.3). The full deformation is composed of these at the final stage. Let us denote the half-way deformations extracted at resolution as and . Initially, at level , these are identity deformations. Then, at each , the half-way deformations are updated by composing them with a predicted update deformation. In detail, the update at level consists of three steps (visualized in Figure 3):
- 1.
Deform the feature representations of level towards each other by the half-way deformations from the previous level :
(4) Note that the deformations have a higher (or the same when ) spatial resolution than the deformed feature volumes, and in practice we first downsample (with linear interpolation) the deformation to the resolution of the feature volume, and then resample the feature volume based on the downsampled deformation.
- 2.
Define an update deformation , using the idea from Equation 3 and the half-way deformed feature representations and :
(5) Here, is a trainable convolutional neural network predicting an invertible auxiliary deformation (details in Section 3.4). The intuition here is that the symmetrically predicted update deformation should learn to adjust for whatever differences in the image features remain after deforming them half-way towards each other in Step 1 with deformations from the previous resolution.
- 3.
Obtain the updated half-way deformation by composing the earlier half-way deformation of level with the update deformation
(6) For the other direction , we use the inverse of the deformation update which can be obtained simply by reversing and in Equation 5 (see Figure 3):
(7) The inverses and are updated similarly.
The full registration architecture is then defined by the functions and which compose the half-way deformations from stage :
| (8) |
Note that , , and their inverses are functions of and through the features in Equation 4, but the dependence is suppressed in the notation for clarity.
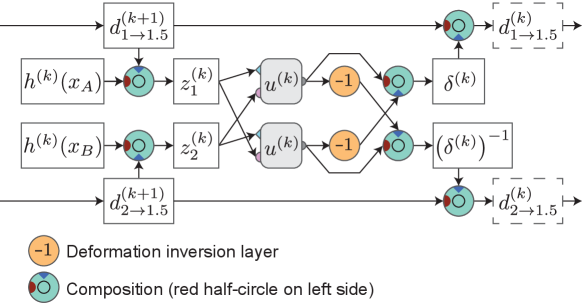
By using half-way deformations at each stage, we avoid the problem with full deformations of having to select either of the image coordinates to which to deform the feature representations of the next stage, breaking the symmetry of the architecture. Now we can instead deform the feature representations of both inputs by the symmetrically predicted half-way deformations, which ensures that the updated deformations after each stage are separately invariant to input order.
3.3 Implicit deformation inversion layer
Implementing the architecture requires inverting deformations from in Equation 5. This could be done, e.g., with the SVF framework, but we propose an approach which requires storing times less data for the backward pass than the standard SVF. The memory saving is significant due to the high memory consumption of volumetric data, allowing larger images to be registered. During each forward pass inversions are required. More details are provided in Appendix E.
As shown by Chen et al. (2008), deformations can be inverted in certain cases by a fixed point iteration. Consequently, we propose to use the deep equilibrium network framework from Section 2.5 for inverting deformations, and label the resulting layer deformation inversion layer. The fixed point equation proposed by Chen et al. (2008) is
where is the deformation to be inverted, is the candidate for the inverse of , and is the identity deformation. It is easy to see that substituting for , yields as output. We use Anderson acceleration (Walker and Ni, 2011) for solving the fixed point equation and use the memory-effecient back-propagation (Bai et al., 2019; Duvenaud et al., 2020) strategy discussed in Section 2.5.
3.4 Topology preserving deformation prediction networks
Each predicts a deformation based on the features and and we define the networks as CNNs predicting cubic spline control point grid in the resolution of the features and . The cubic spine control point grid can then be used to generate the displacement field representing the deformation. The use of cubic spline control point grid for representing deformations is a well-known strategy in image registration, see e.g. (Rueckert et al., 2006; De Vos et al., 2019).
The deformations generated by have to be invertible to ensure the topology preservation property, and particularly invertible by the deformation inversion layer. To ensure that, we limit the control point absolute values below a hard constraint using a scaled function.
In more detail, each consists of the following sequential steps:
- 1.
Concatenation of the two inputs, and , along the channel dimension. Before concatenation we reparametrize the features as and as suggested by Young et al. (2022).
- 2.
Any number of spatial resolution preserving ( and ) convolutions with an activation after each of the convolutions except the final one. The number of output channels of the final convolutions should equal the dimensionality ( in our experiments).
- 3.
function
- 4.
As shown in Appendix D, the optimal upper bound for ensuring invertibility by the deformation inversion layer but also in general, can be obtained by the formula where
| (9) |
is the dimensionality of the images (in this work ), are the relative sampling positions used in cubic spline upsampling (imlementation detail), and is a centered cardinal cubic B-spline (symmetric function with finite support). In practice we define .
The formula can be evaluated exactly for dimensions for any practical number of resolution levels (for concrete values, see Table 16 in Appendix D). Note that the outer sum over is finite since has a finite support and hence only a finite number of terms are non-zero.
The strategy of limiting the absolute values of cubic spline control points to ensure invertibility is similar to the one taken by Rueckert et al. (2006) based on the proof by Choi and Lee (2000). However, our mathematical proof additionally covers the convergence by the deformation inversion layer, and provides an exact bound even in our discretised setting (see Appendix D for more details).
3.5 Theoretical properties
Theorem 1
The proposed architecture is inverse consistent by construction.
Theorem 2
The proposed architecture is symmetric by construction.
Theorem 3
The proposed architecture is topology preserving.
Proof Appendix C, including discussion on numerical errors caused by limited sampling resolution.
3.6 Training and implementation
We train the model in an unsupervised end-to-end manner similarly to most other unsupervised registration methods, by using similarity and deformation regularization losses. The similarity loss encourages deformed images to be similar to the target images, and the regularity loss encourages desirable properties, such as smoothness, on the predicted deformations. For similarity we use local normalized cross-correlation with window width 7 and for regularization we use penalty on the gradients of the displacement fields, identically to VoxelMorph (Balakrishnan et al., 2019). We apply the losses in both directions to maintain symmetry. One could apply the losses in the intermediate coordinates and avoid building the full deformations during training. The final loss is:
| (10) |
where , , the local normalized cross-correlation loss, the penalty on the gradients of the displacement fields, and is the regularization weight. For details on hyperparameter selection, see Appendix A. Our implementation is in PyTorch (Paszke et al., 2019), and is available at https://github.com/honkamj/SITReg. Evaluation methods and preprocessing done by us, see Section 4, are included.
3.7 Inference
We consider two variants: Standard: The final deformation is formed by iteratively resampling at each image resolution (common approach). Complete: All individual deformations (outputs of ) are stored in memory and the final deformation is their true composition. The latter is included only to demonstrate that the deformation is everywhere invertible (no negative determinants) without numerical sampling errors, but the first one is used unless stated otherwise, and perfect invertibility is not necessary in practice. Due to limited sampling resolution even the existing ”diffeomorphic” registration frameworks such as SVF do not usually achieve perfect invertibility.
4 Experimental setup
We evaluate our method on subject-to-subject registration of brain MRI images.
4.1 Datasets
We evaluate our method on two tasks: subject-to-subject registration of brain images and on inspiration-exhale registration of lung CT scans. The latter is considered challenging for deep learning methods, and classical optimization based methods remain state-of-the-art (Falta et al., 2024).
We use two subject-to-subject registration datasets and evaluate on both of them separately: OASIS brains dataset with 414 T1-weighted brain MRI images (Marcus et al., 2007) as pre-processed for Learn2Reg challenge (Hoopes et al., 2021; Hering et al., 2022) 111https://www.oasis-brains.org/#access , and LPBA40 dataset from University of California Laboratory of Neuro Imaging (USC LONI) with 40 brain MRI images (Shattuck et al., 2008)222https://resource.loni.usc.edu/resources/atlases/license-agreement/
Pre-processing for both brain subject-to-subject datasets includes bias field correction, normalization, and cropping. For OASIS dataset we use affinely pre-aligned images and for LPBA40 dataset we use rigidly pre-aligned images. Additionally we train the models without any pre-alignment on OASIS data (OASIS raw) to compare the methods with larger initial displacements. We crop the images in affinely pre-aligned OASIS dataset to resolution and in LPBA40 dataset to resolution. Images in raw OASIS dataset have resolution and we do not crop the images. Voxel sizes of the affinely aligned and raw datasets are the same. We split the OASIS dataset into , and images for training, validation, and testing. The split differs from the Learn2Reg challenge since the test set is not available, but sizes correspond to the splits used by Mok and Chung (2020a, b, 2021). We used all image pairs for testing and validation, yielding test and validation pairs. LPBA40 dataset is much smaller and we split it into , and images for training, validation, and testing. This leaves us with pairs for validation and for testing.
For inspiration-exhale registration of lung CT scans we use a recently published Lung250M-4B dataset by Falta et al. (2024). The dataset is based on multiple earlier datasets: DIR-LAB COPDgene (Castillo et al., 2013), EMPIRE10 (Murphy et al., 2011), L2R-LungCT dataset from Learn2reg challenge (Hering et al., 2022), The National Lung Screening Trial (NLST) dataset (NLST Research Team, 2011, 2013; Clark et al., 2013), TCIA-Ventilation dataset (Clark et al., 2013; Eslick et al., 2018, 2022), and TCIA-NSCLC dataset (Clark et al., 2013; Hugo et al., 2016, 2017; Balik et al., 2013; Roman et al., 2012). In total the dataset has 97, 18, and 9 pairs for training, testing, and validation. However, we can not use 12 image pairs from EMPIRE10 dataset due terms of use, 10 of which are part of the training set, and 2 of which are part of the validation set. The test set is not affected. For evaluation the data set includes manually placed landmarks on the validation and the test image pairs. In addition, the dataset contains automatically generated landmarks for training pairs but we want to stay in the unsupervised setting and do not use those for training. We use lung masked images for training, and downsample them to isotropic mm resolution, normalize and clip them to range , and crop the volumes to the shape of .
4.2 Evaluation metrics
We evaluate brain subject-to-subject registration accuracy using segmentations of brain structures included in the datasets: ( structures for OASIS and for LPBA40), and two metrics: Dice score (Dice) and 95% quantile of the Hausdorff distances (HD95), similarly to Learn2Reg challenge (Hering et al., 2022). Dice score measures the overlap of the segmentations of source images deformed by the method and the segmentations of target images, and HD95 measures the distance between the surfaces of the segmentations.
For evaluating the inspiration-exhale registration of lung CT scans we use mean distance between landmark pairs after registration, denoted as target registration error (TRE). However, comparing methods only based on the overlap of anatomic regions or landmarks is insufficient (Pluim et al., 2016; Rohlfing, 2011), and hence also deformation regularity should be measured, for which we use conventional metrics based on the local Jacobian determinants at sampled locations in each volume. The local derivatives were estimated via small perturbations of voxels. We measure topology preservation as the proportion of the locations with a negative determinant ( of ), and deformation smoothness as the standard deviation of the determinant (). Additionally we report inverse and cycle consistency errors, see Section 1.
4.3 Baseline methods
We compare against VoxelMorph (Balakrishnan et al., 2019), SYMNet (Mok and Chung, 2020a), conditional LapIRN (cLapIRN) (Mok and Chung, 2020b, 2021), and ByConstructionICON (Greer et al., 2023). VoxelMorph is a standard baseline in deep learning based unsupervised registration. With SYMNet we are interested in how well our method preserves topology and how accurate the generated inverse deformations are compared to the SVF based methods. Additionally, since SYMNet is symmetric from the loss point of view, it is interesting to see how symmetric predictions it produces in practice. cLapIRN was the best method on OASIS dataset in Learn2Reg 2021 challenge (Hering et al., 2022). ByConstructionICON is a parallel work to ours developing a multi-step inverse consistent, symmetric, and topology preserving deep learning registration method based on SVF formulation. We used the official implementations333https://github.com/voxelmorph/voxelmorph444https://github.com/cwmok/Fast-Symmetric-Diffeomorphic-Image-Registration-with-Convolutional-Neural-Networks555https://github.com/cwmok/Conditional_LapIRN/666https://github.com/uncbiag/ByConstructionICON/ adjusted to our datasets. SYMNet uses anti-folding loss to penalize negative determinant. Since this loss is a separate component that could be easily used with any method, we also train SYMNet without it, denoted SYMNet (simple) for two of our four datasets. This provides a comparison on how well the vanilla SVF framework can generate invertible deformations in comparison to our method. For details on hyperparameter selection for baseline models, see Appendix B.
4.4 Ablation study
To study the usefulness of the symmetric formulation introduced in Section 3.1, we also conduct the experiments without it while keeping the architecture otherwise identical. In more detail, we change Equation 5 into the following form:
| (11) |
For the inverse update (not necessarily inverse anymore despite the notation) we then simply use
| (12) |
The resulting architecture is still topology preserving but no longer inverse or cycle consistent by construction. We refer to the architecture as SITReg (non-sym)
5 Results
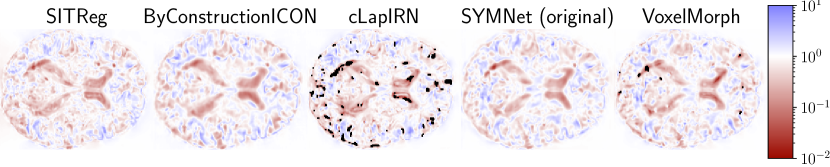
Evaluation results for the affinely pre-aligned OASIS dataset are shown in Table 1, the OASIS raw dataset in Table 2., the LPBA40 dataset in Table 3, and for the Lung250M-4B dataset in Table 4. Figure 4 visualizes differences in deformation regularity on OASIS dataset, and additional visualizations are available in Appendix H. A comparison of the methods’ inference time efficiencies on OASIS dataset are shown in Table 5.
| Accuracy | Deformation regularity | Consistency | ||||
| Model | Dice | HD95 | of | Cycle | Inverse | |
| SYMNet (original) | ||||||
| SYMNet (simple) | ||||||
| VoxelMorph | - | |||||
| cLapIRN | - | |||||
| ByConstructionICON | ||||||
| SITReg | ||||||
| SITReg (non-sym) | ||||||
| ∗ Statistically significant () improvement compared to the baselines, for details see Appendix I. | ||||||
| Accuracy | Deformation regularity | Consistency | ||||
| Model | Dice | HD95 | of | Cycle | Inverse | |
| SYMNet | ||||||
| VoxelMorph | - | |||||
| cLapIRN | - | |||||
| ByConstructionICON | ||||||
| SITReg | ||||||
| ∗ Statistically significant () improvement compared to the baselines, for details see Appendix I. | ||||||
| Accuracy | Deformation regularity | Consistency | ||||
| Model | Dice | HD95 | of | Cycle | Inverse | |
| SYMNet (original) | ||||||
| SYMNet (simple) | ||||||
| VoxelMorph | - | |||||
| cLapIRN | - | |||||
| ByConstructionICON | ||||||
| SITReg | ||||||
| SITReg (non-sym) | ||||||
| ∗ Statistically significant () improvement compared to the baselines, for details see Appendix I. | ||||||
| Deformation regularity | Consistency | ||||
| Model | TRE | of | Cycle | Inverse | |
| SYMNet | |||||
| VoxelMorph | - | ||||
| cLapIRN | - | ||||
| ByConstructionICON | |||||
| SITReg | |||||
| SITReg (non-sym) | |||||
| ∗ Statistically significant () improvement compared to the baselines, for details see Appendix I. | |||||
| Model | Inference Time (s) | Inference Memory (GB) | # parameters (M) |
|---|---|---|---|
| SYMNet | |||
| VoxelMorph | |||
| cLapIRN | |||
| ByConstrictionICON | |||
| SITReg |
6 Discussion
Evaluation of registration algorithms is difficult due to lack of ground truth (Pluim et al., 2016). In particular, the assessment of registration performance should not be based only on a tissue overlap score since a clearly unrealistic and wrong deformation could still have a good tissue overlap score (an extreme example is presented by Rohlfing (2011)). For that reason, usually also deformation regularity is measured. However, that introduces further difficulties for evaluation because of the trade-off invoked by the regularization hyperparameter (in our case ) between the tissue overlap and deformation regularity, which can change the ranking of the methods for different metrics. For that reason one should look at the overall performance across the regularity and accuracy metrics (see e.g. Learn2reg challenge (Hering et al., 2022)). We further evaluate using the consistency metrics as is often done in the literature (Holden et al., 2000; Pluim et al., 2016).
In a such overall comparison over all four datasets, our method performs clearly the best. In more detail:
- •
VoxelMorph: Our method outperforms it on every metric in every experiment.
- •
SYMNet: While SYMNet (original) has in general slightly better deformation regularity (compared to our standard inference variant), our method has a significantly better dice score or TRE. By increasing regularization one could make our model to have better regularity while still maintaining significantly better dice score or TRE than SYMNet. This is demonstrated for validation set results in Tables 6, 7, and 8 in Appendix A. In other words, our method has significantly better overall performance.
- •
cLapIRN: Our method outperforms cLapIRN on all four datasets. On OASIS raw and Lung250M-4B datasets our method outperforms cLapIRN clearly. On the pre-aligned OASIS and LPBA40 datasets our method has only slightly better tissue overlap performance than cLapIRN, but has clearly superior deformation regularity in terms of folding voxels.
- •
ByConstructionICON: On the OASIS datasets ByCounstrictionICON performs similarily to our method, although slightly worse on the OASIS raw dataset. However, on the smaller LPBA40 and Lung250M-4B datasets the performance of our method is clearly better, suggesting that our method generalizes from less data than ByConstructionICON.
For the Lung250M-4B dataset the test set is standardized, and we can compare the results to the methods benchmarked in the paper (Falta et al., 2024). However, our metrics are computed in the coordinates of the inhale image whereas the paper uses coordinates of the exhale image. In the exhale coordinates our method obtains TRE which is very competitive, clearly outperforming the best deep learning method VoxelMorph++ without instance optimization (TRE ) trained using additional landmark supervision unlike our unsupervised method. VoxelMorph++ with instance optimization obtains TRE .
6.1 Ablation study
Based on the ablation study, the symmetric formulation helps especially on the smaller LPBA40 and Lung250M-4B datasets. On the larger OASIS dataset the performance on tissue overlap metrics is similar but even there is a slight improvement in terms of deformation regularity. The result is in line with the common machine learning wisdom that incorporating inductive bias into models has more relevance when the training set is small.
6.2 Computational performance
Inference time of our method is slightly larger than that of the compared methods, but unlike VoxelMorph and cLapIRN, it produces deformations in both directions immediately. Also, half a second runtime is still very fast and restrictive only in the most time-critical use cases. In terms of inference memory usage our method is competitive.
7 Conclusions
We proposed a novel image registration architecture inbuilt with the desirable properties of symmetry, inverse consistency, and topology preservation. The multi-resolution formulation was capable of accurately registering images even with large intial misalignments. As part of our method, we developed a new neural network component deformation inversion layer. The model is easily end-to-end trainable and does not require tedious multi-stage training strategies. In the experiments the method demonstrates state-of-the-art registration performance. The main limitation is somewhat heavier computational cost than other methods.
Acknowledgments
This work was supported by the Academy of Finland (Flagship programme: Finnish Center for Artificial Intelligence FCAI, and grants 336033, 352986) and EU (H2020 grant 101016775 and NextGenerationEU). We also acknowledge the computational resources provided by the Aalto Science-IT Project.
Ethical Standards
The work follows appropriate ethical standards in conducting research and writing the manuscript, following all applicable laws and regulations regarding treatment of animals or human subjects.
Conflicts of Interest
We declare we don’t have conflicts of interest.
Data availability
All data used in the experiments is publicly available. The exact OASIS dataset used can be accessed from the website of Learn2reg challenge https://learn2reg.grand-challenge.org/ and the LPBA40 dataset is available for download at https://www.loni.usc.edu/research/atlas_downloads. Lung250M-4B dataset can be obtained based on instructions at https://github.com/multimodallearning/Lung250M-4B. The provided codebase contains implementation for all additional data pre-processing that was done.
References
- Arsigny et al. (2006) Vincent Arsigny, Olivier Commowick, Xavier Pennec, and Nicholas Ayache. A log-euclidean framework for statistics on diffeomorphisms. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 924–931. Springer, 2006.
- Ashburner (2007) John Ashburner. A fast diffeomorphic image registration algorithm. Neuroimage, 38(1):95–113, 2007.
- Avants et al. (2008) Brian B Avants, Charles L Epstein, Murray Grossman, and James C Gee. Symmetric diffeomorphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain. Medical image analysis, 12(1):26–41, 2008.
- Avants et al. (2009) Brian B Avants, Nick Tustison, Gang Song, et al. Advanced normalization tools (ants). Insight j, 2(365):1–35, 2009.
- Bai et al. (2019) Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models. Advances in Neural Information Processing Systems, 32, 2019.
- Bai et al. (2020) Shaojie Bai, Vladlen Koltun, and J Zico Kolter. Multiscale deep equilibrium models. Advances in Neural Information Processing Systems, 33:5238–5250, 2020.
- Balakrishnan et al. (2019) Guha Balakrishnan, Amy Zhao, Mert R Sabuncu, John Guttag, and Adrian V Dalca. VoxelMorph: A learning framework for deformable medical image registration. IEEE transactions on medical imaging, 38(8):1788–1800, 2019.
- Balik et al. (2013) Salim Balik, Elisabeth Weiss, Nuzhat Jan, Nicholas Roman, William C. Sleeman, Mirek Fatyga, Gary E. Christensen, Cheng Zhang, Martin J. Murphy, Jun Lu, Paul Keall, Jeffrey F. Williamson, and Geoffrey D. Hugo. Evaluation of 4-dimensional computed tomography to 4-dimensional cone-beam computed tomography deformable image registration for lung cancer adaptive radiation therapy. International Journal of Radiation Oncology*Biology*Physics, 86(2):372–379, 2013. ISSN 0360-3016. . URL https://www.sciencedirect.com/science/article/pii/S0360301613000023.
- Beg et al. (2005) M Faisal Beg, Michael I Miller, Alain Trouvé, and Laurent Younes. Computing large deformation metric mappings via geodesic flows of diffeomorphisms. International journal of computer vision, 61:139–157, 2005.
- Bronstein et al. (2017) Michael M Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst. Geometric deep learning: going beyond euclidean data. IEEE Signal Processing Magazine, 34(4):18–42, 2017.
- Bronstein et al. (2021) Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv preprint arXiv:2104.13478, 2021.
- Cao et al. (2005) Yan Cao, Michael I Miller, Raimond L Winslow, and Laurent Younes. Large deformation diffeomorphic metric mapping of vector fields. IEEE transactions on medical imaging, 24(9):1216–1230, 2005.
- Castillo et al. (2013) Richard Castillo, Edward Castillo, David Fuentes, Moiz Ahmad, Abbie M Wood, Michelle S Ludwig, and Thomas Guerrero. A reference dataset for deformable image registration spatial accuracy evaluation using the copdgene study archive. Physics in Medicine & Biology, 58(9):2861, 2013.
- Chen et al. (2023) Junyu Chen, Yihao Liu, Shuwen Wei, Zhangxing Bian, Shalini Subramanian, Aaron Carass, Jerry L Prince, and Yong Du. A survey on deep learning in medical image registration: New technologies, uncertainty, evaluation metrics, and beyond. arXiv preprint arXiv:2307.15615, 2023.
- Chen et al. (2008) Mingli Chen, Weiguo Lu, Quan Chen, Kenneth J Ruchala, and Gustavo H Olivera. A simple fixed-point approach to invert a deformation field. Medical physics, 35(1):81–88, 2008.
- Choi and Lee (2000) Yongchoel Choi and Seungyong Lee. Injectivity conditions of 2D and 3D uniform cubic B-spline functions. Graphical models, 62(6):411–427, 2000.
- Christensen et al. (1995) Gary E Christensen, Richard D Rabbitt, Michael I Miller, Sarang C Joshi, Ulf Grenander, Thomas A Coogan, and David C Van Essen. Topological properties of smooth anatomic maps. In Information processing in medical imaging, volume 3, page 101. Springer Science & Business Media, 1995.
- Clark et al. (2013) Kenneth Clark, Bruce Vendt, Kirk Smith, John Freymann, Justin Kirby, Paul Koppel, Stephen Moore, Stanley Phillips, David Maffitt, Michael Pringle, Lawrence Tarbox, and Fred Prior. The cancer imaging archive (tcia): Maintaining and operating a public information repository. Journal of Digital Imaging, 26(6):1045–1057, Dec 2013. ISSN 1618-727X. . URL https://doi.org/10.1007/s10278-013-9622-7.
- Dalca et al. (2018) Adrian V Dalca, Guha Balakrishnan, John Guttag, and Mert R Sabuncu. Unsupervised learning for fast probabilistic diffeomorphic registration. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, September 16-20, 2018, Proceedings, Part I, pages 729–738. Springer, 2018.
- De Vos et al. (2019) Bob D De Vos, Floris F Berendsen, Max A Viergever, Hessam Sokooti, Marius Staring, and Ivana Išgum. A deep learning framework for unsupervised affine and deformable image registration. Medical image analysis, 52:128–143, 2019.
- Duvenaud et al. (2020) David Duvenaud, J Zico Kolter, and Matthew Johnson. Deep implicit layers tutorial-neural ODEs, deep equilibirum models, and beyond. Neural Information Processing Systems Tutorial, 2020.
- Eslick et al. (2018) Enid M. Eslick, John Kipritidis, Denis Gradinscak, Mark J. Stevens, Dale L. Bailey, Benjamin Harris, Jeremy T. Booth, and Paul J. Keall. Ct ventilation imaging derived from breath hold ct exhibits good regional accuracy with galligas pet. Radiotherapy and Oncology, 127(2):267–273, 2018. ISSN 0167-8140. . URL https://www.sciencedirect.com/science/article/pii/S0167814017327652.
- Eslick et al. (2022) Enid M Eslick, John Kipritidis, Denis Gradinscak, Mark J Stevens, Dale L Bailey, Benjamin Harris, Jeremy T Booth, and Paul J Keall. CT ventilation as a functional imaging modality for lung cancer radiotherapy (CT-vs-PET-Ventilation-Imaging), 2022.
- Estienne et al. (2021) Théo Estienne, Maria Vakalopoulou, Enzo Battistella, Theophraste Henry, Marvin Lerousseau, Amaury Leroy, Nikos Paragios, and Eric Deutsch. MICS: Multi-steps, inverse consistency and symmetric deep learning registration network. arXiv preprint arXiv:2111.12123, 2021.
- Falta et al. (2024) Fenja Falta, Christoph Großbröhmer, Alessa Hering, Alexander Bigalke, and Mattias Heinrich. Lung250m-4b: a combined 3d dataset for ct-and point cloud-based intra-patient lung registration. Advances in Neural Information Processing Systems, 36, 2024.
- Greer et al. (2023) Hastings Greer, Lin Tian, Francois-Xavier Vialard, Roland Kwitt, Sylvain Bouix, Raul San Jose Estepar, Richard Rushmore, and Marc Niethammer. Inverse consistency by construction for multistep deep registration. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 688–698. Springer, 2023.
- Gu et al. (2020) Dongdong Gu, Xiaohuan Cao, Shanshan Ma, Lei Chen, Guocai Liu, Dinggang Shen, and Zhong Xue. Pair-wise and group-wise deformation consistency in deep registration network. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 171–180. Springer, 2020.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Hering et al. (2022) Alessa Hering, Lasse Hansen, Tony CW Mok, Albert CS Chung, Hanna Siebert, Stephanie Häger, Annkristin Lange, Sven Kuckertz, Stefan Heldmann, Wei Shao, et al. Learn2Reg: Comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning. IEEE Transactions on Medical Imaging, 2022.
- Holden et al. (2000) Mark Holden, Derek LG Hill, Erika RE Denton, Jo M Jarosz, Tim CS Cox, Torsten Rohlfing, Joanne Goodey, and David J Hawkes. Voxel similarity measures for 3-d serial mr brain image registration. IEEE transactions on medical imaging, 19(2):94–102, 2000.
- Hoopes et al. (2021) Andrew Hoopes, Malte Hoffmann, Bruce Fischl, John Guttag, and Adrian V Dalca. Hypermorph: Amortized hyperparameter learning for image registration. In International Conference on Information Processing in Medical Imaging, pages 3–17. Springer, 2021.
- Hugo et al. (2016) Geoffrey D Hugo, Elisabeth Weiss, William C Sleeman, Salim Balik, Paul J Keall, Jun Lu, and Jeffrey F Williamson. Data from 4D lung imaging of NSCLC patients, 2016.
- Hugo et al. (2017) Geoffrey D. Hugo, Elisabeth Weiss, William C. Sleeman, Salim Balik, Paul J. Keall, Jun Lu, and Jeffrey F. Williamson. A longitudinal four-dimensional computed tomography and cone beam computed tomography dataset for image-guided radiation therapy research in lung cancer. Medical Physics, 44(2):762–771, 2017. . URL https://aapm.onlinelibrary.wiley.com/doi/abs/10.1002/mp.12059.
- Iglesias (2023) Juan Eugenio Iglesias. A ready-to-use machine learning tool for symmetric multi-modality registration of brain mri. Scientific Reports, 13(1):6657, 2023.
- Joshi and Hong (2023) Ankita Joshi and Yi Hong. R2net: Efficient and flexible diffeomorphic image registration using lipschitz continuous residual networks. Medical Image Analysis, 89:102917, 2023.
- Kim et al. (2019) Boah Kim, Jieun Kim, June-Goo Lee, Dong Hwan Kim, Seong Ho Park, and Jong Chul Ye. Unsupervised deformable image registration using cycle-consistent CNN. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 166–174. Springer, 2019.
- Klein et al. (2009) Arno Klein, Jesper Andersson, Babak A Ardekani, John Ashburner, Brian Avants, Ming-Chang Chiang, Gary E Christensen, D Louis Collins, James Gee, Pierre Hellier, et al. Evaluation of 14 nonlinear deformation algorithms applied to human brain mri registration. Neuroimage, 46(3):786–802, 2009.
- Krebs et al. (2018) Julian Krebs, Tommaso Mansi, Boris Mailhé, Nicholas Ayache, and Hervé Delingette. Unsupervised probabilistic deformation modeling for robust diffeomorphic registration. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, pages 101–109. Springer, 2018.
- Krebs et al. (2019) Julian Krebs, Hervé Delingette, Boris Mailhé, Nicholas Ayache, and Tommaso Mansi. Learning a probabilistic model for diffeomorphic registration. IEEE transactions on medical imaging, 38(9):2165–2176, 2019.
- Mahapatra and Ge (2019) Dwarikanath Mahapatra and Zongyuan Ge. Training data independent image registration with GANs using transfer learning and segmentation information. In 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), pages 709–713. IEEE, 2019.
- Marcus et al. (2007) Daniel S Marcus, Tracy H Wang, Jamie Parker, John G Csernansky, John C Morris, and Randy L Buckner. Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI data in young, middle aged, nondemented, and demented older adults. Journal of cognitive neuroscience, 19(9):1498–1507, 2007.
- Mok and Chung (2020a) Tony CW Mok and Albert Chung. Fast symmetric diffeomorphic image registration with convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4644–4653, 2020a.
- Mok and Chung (2020b) Tony CW Mok and Albert Chung. Large deformation diffeomorphic image registration with laplacian pyramid networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 211–221. Springer, 2020b.
- Mok and Chung (2021) Tony CW Mok and Albert Chung. Conditional deformable image registration with convolutional neural network. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 35–45. Springer, 2021.
- Murphy et al. (2011) Keelin Murphy, Bram Van Ginneken, Joseph M Reinhardt, Sven Kabus, Kai Ding, Xiang Deng, Kunlin Cao, Kaifang Du, Gary E Christensen, Vincent Garcia, et al. Evaluation of registration methods on thoracic ct: the empire10 challenge. IEEE transactions on medical imaging, 30(11):1901–1920, 2011.
- Niethammer et al. (2019) Marc Niethammer, Roland Kwitt, and Francois-Xavier Vialard. Metric learning for image registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8463–8472, 2019.
- NLST Research Team (2011) NLST Research Team. Reduced lung-cancer mortality with low-dose computed tomographic screening. New England Journal of Medicine, 365(5):395–409, 2011. . URL https://www.nejm.org/doi/full/10.1056/NEJMoa1102873.
- NLST Research Team (2013) NLST Research Team. Data from the national lung screening trial (NLST). https://doi.org/10.7937/TCIA.HMQ8-J677, 2013. The Cancer Imaging Archive.
- Oliveira and Tavares (2014) Francisco PM Oliveira and Joao Manuel RS Tavares. Medical image registration: a review. Computer methods in biomechanics and biomedical engineering, 17(2):73–93, 2014.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019. URL http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf.
- Pluim et al. (2016) Josien PW Pluim, Sascha EA Muenzing, Koen AJ Eppenhof, and Keelin Murphy. The truth is hard to make: Validation of medical image registration. In 2016 23rd International Conference on Pattern Recognition (ICPR), pages 2294–2300. IEEE, 2016.
- Ramon et al. (2022) Ubaldo Ramon, Monica Hernandez, and Elvira Mayordomo. Lddmm meets gans: Generative adversarial networks for diffeomorphic registration. In International Workshop on Biomedical Image Registration, pages 18–28. Springer, 2022.
- Rohlfing (2011) Torsten Rohlfing. Image similarity and tissue overlaps as surrogates for image registration accuracy: widely used but unreliable. IEEE transactions on medical imaging, 31(2):153–163, 2011.
- Roman et al. (2012) Nicholas O. Roman, Wes Shepherd, Nitai Mukhopadhyay, Geoffrey D. Hugo, and Elisabeth Weiss. Interfractional positional variability of fiducial markers and primary tumors in locally advanced non-small-cell lung cancer during audiovisual biofeedback radiotherapy. International Journal of Radiation Oncology*Biology*Physics, 83(5):1566–1572, 2012. ISSN 0360-3016. . URL https://www.sciencedirect.com/science/article/pii/S0360301611034596.
- Rueckert et al. (1999) Daniel Rueckert, Luke I Sonoda, Carmel Hayes, Derek LG Hill, Martin O Leach, and David J Hawkes. Nonrigid registration using free-form deformations: Application to breast MR images. IEEE Transactions on Medical Imaging, 18(8):712–721, 1999.
- Rueckert et al. (2006) Daniel Rueckert, Paul Aljabar, Rolf A Heckemann, Joseph V Hajnal, and Alexander Hammers. Diffeomorphic registration using B-splines. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 702–709. Springer, 2006.
- Shattuck et al. (2008) David W Shattuck, Mubeena Mirza, Vitria Adisetiyo, Cornelius Hojatkashani, Georges Salamon, Katherine L Narr, Russell A Poldrack, Robert M Bilder, and Arthur W Toga. Construction of a 3D probabilistic atlas of human cortical structures. Neuroimage, 39(3):1064–1080, 2008.
- Shen et al. (2019a) Zhengyang Shen, Xu Han, Zhenlin Xu, and Marc Niethammer. Networks for joint affine and non-parametric image registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4224–4233, 2019a.
- Shen et al. (2019b) Zhengyang Shen, François-Xavier Vialard, and Marc Niethammer. Region-specific diffeomorphic metric mapping. Advances in Neural Information Processing Systems, 32, 2019b.
- Sotiras et al. (2013) Aristeidis Sotiras, Christos Davatzikos, and Nikos Paragios. Deformable medical image registration: A survey. IEEE transactions on medical imaging, 32(7):1153–1190, 2013.
- Vercauteren et al. (2009) Tom Vercauteren, Xavier Pennec, Aymeric Perchant, and Nicholas Ayache. Diffeomorphic demons: Efficient non-parametric image registration. NeuroImage, 45(1):S61–S72, 2009.
- Walker and Ni (2011) Homer F Walker and Peng Ni. Anderson acceleration for fixed-point iterations. SIAM Journal on Numerical Analysis, 49(4):1715–1735, 2011.
- Wang and Zhang (2020) Jian Wang and Miaomiao Zhang. Deepflash: An efficient network for learning-based medical image registration. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4444–4452, 2020.
- Wang et al. (2023) Jian Wang, Jiarui Xing, Jason Druzgal, William M Wells III, and Miaomiao Zhang. Metamorph: learning metamorphic image transformation with appearance changes. In International Conference on Information Processing in Medical Imaging, pages 576–587. Springer, 2023.
- Wu et al. (2022) Yifan Wu, Tom Z Jiahao, Jiancong Wang, Paul A Yushkevich, M Ani Hsieh, and James C Gee. Nodeo: A neural ordinary differential equation based optimization framework for deformable image registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20804–20813, 2022.
- Young et al. (2022) Sean I Young, Yaël Balbastre, Adrian V Dalca, William M Wells, Juan Eugenio Iglesias, and Bruce Fischl. SuperWarp: Supervised learning and warping on U-Net for invariant subvoxel-precise registration. arXiv preprint arXiv:2205.07399, 2022.
- Zhang (2018) Jun Zhang. Inverse-consistent deep networks for unsupervised deformable image registration. arXiv preprint arXiv:1809.03443, 2018.
- Zhang et al. (2023) Liutong Zhang, Guochen Ning, Lei Zhou, and Hongen Liao. Symmetric pyramid network for medical image inverse consistent diffeomorphic registration. Computerized Medical Imaging and Graphics, 104:102184, 2023.
- Zheng et al. (2021) Yuanjie Zheng, Xiaodan Sui, Yanyun Jiang, Tongtong Che, Shaoting Zhang, Jie Yang, and Hongsheng Li. Symreg-gan: symmetric image registration with generative adversarial networks. IEEE transactions on pattern analysis and machine intelligence, 44(9):5631–5646, 2021.
A Hyperparameter selection details
We experimented on validation set with different hyperparameters during the development. While the final results on test set are computed only for one chosen configuration, the results on validation set might still be of interest for the reader. Results of these experiments for the pre-aligned OASIS dataset are shown in Table 6, for the LPBA40 dataset in Table 7, and for the Lung250M-4B dataset in Table 8.
For the OASIS raw dataset without pre-alignment we used resolution levels, together with an affine transformation prediction stage before the other deformation updates. We omitted the predicted affine transformation from the deformation regularization. The same regularization weight was used as for the pre-aligned OASIS dataset.
| Hyperparameters | Accuracy | Deformation regularity | Consistency | |||
|---|---|---|---|---|---|---|
| Dice | of | Cycle | Inverse | |||
| 1.0 | 5 | |||||
| 1.5 | 5 | |||||
| 2.0 | 5 | |||||
| 1.0 | 4 | |||||
| 1.5 | 4 | |||||
| 2.0 | 4 | |||||
| Hyperparameters | Accuracy | Deformation regularity | Consistency | |||||
|---|---|---|---|---|---|---|---|---|
| Affine | Dice | HD95 | of | Cycle | Inverse | |||
| 1.0 | 4 | No | ||||||
| 1.0 | 5 | No | ||||||
| 1.0 | 6 | No | ||||||
| 1.0 | 7 | No | ||||||
| 1.0 | 5 | Yes | ||||||
| 1.0 | 6 | Yes | ||||||
| 2.0 | 4 | No | ||||||
| 2.0 | 5 | No | ||||||
| 2.0 | 6 | No | ||||||
| 2.0 | 7 | No | ||||||
| 2.0 | 5 | Yes | ||||||
| 2.0 | 6 | Yes | ||||||
| Hyperparameters | Accuracy | Deformation regularity | Consistency | |||
|---|---|---|---|---|---|---|
| TRE | of | Cycle | Inverse | |||
| 1.0 | 5 | |||||
| 1.0 | 6 | |||||
| 2.0 | 6 | |||||
B Hyperparameter selection details for baselines
For cLapIRN baseline we used the regularization parameter value for the OASIS datasets, value for the LPBA40 dataset, and for the Lung250M-4b dataset where is used as in the paper presenting the method (Mok and Chung, 2021). The values were chosen based on the validation set results shown in Tables 9, 10, 11, and 12.
For ByConstructionICON baseline we used regularization parameter for the OASIS datasets, for the LPBA40 dataset, and for the Lung250M-4B dataset. The values were chosen based on the validation set results shown in Tables 13, 14, and 15.
We trained VoxelMorph with losses and regularization weight identical to our method and for SYMNet we used hyperparameters directly provided by Mok and Chung (2020a). We used the default number of convolution features for the baselines except for VoxelMorph we doubled the number of features, as that was suggested in the paper (Balakrishnan et al., 2019).
| Hyperparameters | Accuracy | Deformation regularity | Consistency | |
|---|---|---|---|---|
| Dice | Cycle | |||
| 0.01 | ||||
| 0.05 | ||||
| 0.1 | ||||
| 0.2 | ||||
| 0.4 | ||||
| 0.8 | ||||
| 1.0 | ||||
| Hyperparameters | Accuracy | Deformation regularity | Consistency | |
|---|---|---|---|---|
| Dice | Cycle | |||
| 0.01 | ||||
| 0.02 | ||||
| 0.05 | ||||
| 0.1 | ||||
| Hyperparameters | Accuracy | Deformation regularity | Consistency | ||
|---|---|---|---|---|---|
| Dice | HD95 | Cycle | |||
| 0.01 | |||||
| 0.05 | |||||
| 0.1 | |||||
| 0.2 | |||||
| 0.4 | |||||
| 0.8 | |||||
| 1.0 | |||||
| Hyperparameters | Accuracy | Deformation regularity | Consistency | |
|---|---|---|---|---|
| TRE | Cycle | |||
| 0.01 | ||||
| 0.05 | ||||
| 0.1 | ||||
| 0.2 | ||||
| 0.4 | ||||
| 0.8 | ||||
| 1.0 | ||||
| Hyperparameters | Accuracy | Deformation regularity | Consistency | ||
|---|---|---|---|---|---|
| Dice | Cycle | Inverse | |||
| 0.5 | |||||
| 1.0 | |||||
| 5.0 | |||||
| Hyperparameters | Accuracy | Deformation regularity | Consistency | |||
|---|---|---|---|---|---|---|
| Dice | HD95 | Cycle | Inverse | |||
| 0.5 | ||||||
| 1.0 | ||||||
| Hyperparameters | Accuracy | Deformation regularity | Consistency | ||
|---|---|---|---|---|---|
| TRE | Cycle | Inverse | |||
| 0.5 | |||||
| 1.0 | |||||
| 3.0 | |||||
| 5.0 | |||||
C Proof of theoretical properties
While in the main text dependence of the intermediate outputs , , , , and on the input images is not explicitly written, throughout this proof we include the dependence in the notation since it is relevant for the proof.
C.1 Inverse consistent by construction (Theorem 1)
Proof Inverse consistency by construction follows directly from Equation 8:
Note that due to limited sampling resolution the inverse consistency error is not exactly zero despite of the proof. The same is true for earlier inverse consistent by construction registration methods, as discussed in Section 1.
To be more specific, sampling resolution puts a limit on the accuracy of the inverses obtained using deformation inversion layer, and also limits accuracy of compositions if deformations are resampled to their original resolution as part of the composition operation (see Section 3.7). While another possible source could be the fixed point iteration in deformation inversion layer converging imperfectly, that can be proven to be insignificant. As shown by Appendix D, the fixed point iteration is guaranteed to converge, and error caused by the lack of convergence of fixed point iteration can hence be controlled by the stopping criterion. In our experiments we used as a stopping criterion maximum inversion error within all the sampling locations reaching below one hundredth of a voxel, which is very small.
C.2 Symmetric by construction (Theorem 2)
Proof We use induction. Assume that for any and at level the following holds: . For level it holds trivially since and are defined as identity deformations. Using the induction assumption we have at level :
Then also:
Then we can finalize the induction step:
From this follows that the method is symmetric by construction:
The proven relation holds exactly.
C.3 Topology preserving (Theorem 3)
Proof As shown by Appendix D, each produces topology preserving (everywhere positive Jacobian determinants) deformations (architecture of is described in Section 3.4). Since the overall deformation is composition of multiple outputs of and their inverses, the whole deformation has also everywhere positive Jacobians since the Jacobian determinants at each point can be obtained as a product of the Jacobian determinants of the composed deformations.
The inveritibility is not perfect if the compositions of and their inverses are resampled to the input image resolution, as is common practice in image registration. However, invertibility everywhere can be achieved by storing all the individual deformations and evaluating the composed deformation as their true composition (see Section 3.7 on inference variants and the results in Section 5).
D Deriving the optimal bound for control points
D.1 Proof summary
As discussed in Section 3.4, we limit absolute values of the predicted cubic spline control points defining the displacement field by a hard constraint for each resolution level . We want to find optimal which ensures invertibility of individual deformations and convergence of the fixed point iteration in deformation inversion layer. Note that the proof provides a significantly shorter and more general proof of the theorems 1 and 4 in (Choi and Lee, 2000).
We start by showing the optimal bound in continuous case (infinite resolution), and then extend it to our discrete case where values between the B-spline samples are defined by linear interpolation.
The derived continuous bound equals the reciprocal of the maximum possible matrix norm of the local Jacobian matrices over all possible generated displacement fields. The matrix norm of a local Jacobian matrix equals the local Lipschitz constant and hence the bound ensures that the Lipschitz constant with respect to the norm stays under one, which by (Chen et al., 2008) guarantees both invertibility and convergence of the fixed point iteration. However, a straightforward formula for the bound is intractable computationally in three dimensions, and we simplify it by showing that due to symmetries the absolute value around the derivatives can be removed from the function being maximixed, yielding a formula which can be evaluated exactly. We further show with a counter example that the proposed bound is tight.
The bound equals the bound obtained by (Choi and Lee, 2000) using a very different approach, further validating the result (their proof does not cover the convergence of the fixed point iteration and is less general).
Note that the bound ensures positivity of the Jacobians, not only invertibility, since we are limiting displacements (and zero displacement deformation has trivially positive Jacobian).
D.2 Proof of the continuous case
By (Chen et al., 2008) a deformation field is invertible by the proposed deformation inversion layer (and hence invertible in general) if its displacement field is contractive mapping with respect to some norm (the convergence is then also with respect to that norm). In finite dimensions convergence in any p-norm is equal and hence we should choose the norm which gives the loosest bound.
Let us choose norm for our analysis, which, as it turns out, gives the loosest possible bound. Then the Lipschitz constant of a displacement field is equivalent to the maximum operator norm of the local Jacobian matrices of the displacement field.
Since for matrices norm corresponds to maximum absolute row sum it is enough to consider one component of the displacement field.
Let be a centered cardinal B-spline of some degree (actually any continuous almost everywhere differentiable function with finite support is fine) and let us consider an infinite grid of control points where is the dimensionality of the displacement field. For notational convinience, let us define a set .
Now let be the -dimensional displacement field (or one component of it) defined by the control point grid:
| (13) |
Note that since the function has finite support the first sum over can be defined as a finite sum for any and is hence well-defined. Also, without loss of generality it is enough to look at region due to the unit spacing of the control point grid.
For partial derivatives we have
| (14) |
where .
Following the power set notation, let us denote control points limited to some set as . That is, if , then for all , .
Lemma 4
For all , is a contractive mapping with respect to the norm, where
| (15) |
Proof For all ,
| (16) | ||||
Sums of absolute values of partial derivatives are exactly the operator norms of the local Jacobian matrices of , hence is a contraction.
Lemma 5
For any , , we can find some such that
| (17) |
Proof The B-splines are symmetric around origin:
| (18) |
Let us propose
| (19) |
and as where is a bijection defined as follows:
| (20) |
Then for all :
| (21) | ||||
which gives
| (22) | ||||||
| g is bijective | ||||||
And for all ,
| (23) | ||||
which gives for all
| (24) | ||||||
| g is bijective | ||||||
Theorem 6
For all , is a contractive mapping with respect to the norm, where
| (25) |
Proof Let us show that .
| (26) | ||||||
| (Lemma 5) | ||||||
The last step follows from the obvious fact that the sum is maximized when choosing each to be either or based on the sign of the inner sum .
By Lemma 4 is then a contractive mapping with respect to the norm.
Theorem 6 proves that if we limit the control point absolute values to be less than , then the resulting deformation is invertible by the fixed point iteration. Also, approximating accurately is possible at least for . Subset of over which the sum needs to be taken depends on the support of the function which again depends on the degree of the B-splines used.
Next we want to show that the obtained bound is also tight bound for invertibility of the deformation. That also then shows that norm gives the loosest possible bound.
Since corresponds only to one component of a displacement field, let us consider a fully defined displacement field formed by stacking number of together. Let us define
| (27) |
Theorem 7
There exists , s.t. where is the Jacobian matrix of and is the identity matrix.
Let us define . Then
| (29) |
Now let be a vector consisting only of values , that is . Then one has
| (30) | ||||
In other words is an eigenvector of with eigenvalue meaning that the determinant of is also .
The proposed bound is hence the loosest possible since the deformation can have zero Jacobian at the bound, meaning it is not invertible.
D.3 Sampling based case (Equation 9)
The bound used in practice, given in Equation 9, is slightly different to the bound proven in Theorem 6. The reason is that for computational efficiency we do not use directly the cubic B-spline representation for the displacement field but instead take only samples of the displacement field in the full image resolution (see Appendix 3.4), and use efficient bi- or trilinear interpolation for defining the intermediate values. As a result the continuous case bound does not apply anymore.
However, finding the exact bounds for our approximation equals evaluating the maximum in Theorem 6 over a finite set of sampling locations and replacing with finite difference derivatives. The mathematical argument for that goes almost identically and will not be repeated here. However, to justify using finite difference derivatives, we need the following two trivial remarks:
- •
When defining a displacement field using grid of values and bi- or trilinear interpolation, the highest value for operator norm is obtained at the corners of each interpolation patch.
- •
Due to symmetry, it is enough to check derivative only at one of corners of each bi- or trilinear interpolation patch in computing the maximum (corresponding to finite difference derivative in only one direction over each dimension).
Maximum is evaluated over the relative sampling locations with respect to the resolution of the control point grid (which is in the resolution of the features and ). The exact sampling grid depends on how the sampling is implemented (which is an implementation detail), and in our case we used the locations which have, without loss of generality, been again limited to the unit cube.
No additional insights are required to show that the equation 9 gives the optimal bound. For concrete values of , see Table 16.
| k | Sampling rate | ||
|---|---|---|---|
| 0 | 1 | 2.222222222 | 2.777777778 |
| 1 | 2 | 2.031168620 | 2.594390728 |
| 2 | 4 | 2.084187826 | 2.512366240 |
| 3 | 8 | 2.063570023 | 2.495476474 |
| 4 | 16 | 2.057074951 | 2.489089713 |
| 5 | 32 | 2.052177394 | 2.484247818 |
| 6 | 64 | 2.049330491 | 2.481890143 |
| 7 | 128 | 2.047871477 | 2.480726430 |
| 8 | 256 | 2.047136380 | 2.480102049 |
| 2.046392675 | 2.479472335 |
E Deformation inversion layer memory usage
We conducted an experiment on the memory usage of the deformation inversion layer compared to the stationary velocity field (SVF) framework (Arsigny et al., 2006) since SVF framework could also be used to implement the suggested architecture in practice.
With the SVF framework one could slightly simplify the deformation update Equation 5 to the form
| (31) |
where is the SVF integration (corresponding to Lie algebra exponentiation), and now predicts an auxiliary velocity field. We compared memory usage of this to our implementation, and used the implementation by Dalca et al. (2018) for SVF integration.
The results are shown in Table 17. Our version implemented using the deformation inversion layer requires times less data to be stored in memory for the backward pass compared to the SVF integration. The peak memory usage during the inversion is also slightly lower. The memory saving is due to the memory efficient back-propagation through the fixed point iteration layers, which requires only the final inverted volume to be stored for backward pass. Since our architecture requires two such operations for each resolution level ( and its inverse), the memory saved during training is significant.
| Method | Between passes memory usage (GB) | Peak memory usage (GB) |
|---|---|---|
| Deformation inversion layer | ||
| SVF integration |
F Extended related work
In this appendix we aim to provide a more thorough analysis of the related work, by introducing in more detail the works that we find closest to our method, and explaining how our method differs from those.
F.1 Classical registration methods
Classical registration methods, as opposed to the learning based methods, optimize the deformation independently for any given single image pair. For this reason they are sometimes called optimization based methods.
DARTEL by Ashburner (2007) is a classical optimization based registration method built on top of the stationary velocity field (SVF) (Arsigny et al., 2006) framework offering symmetric by construction, inverse consistent, and topology preserving registration. The paper is to our knowledge the first symmetric by construction, inverse consistent, and topology preserving registration method.
SyN by Avants et al. (2008) is another classical symmetric by construction, inverse consistent, and topology preserving registration method. The properties are achieved by the Large Deformation Diffeomorphic Metric Mapping LDDMM framework (Beg et al., 2005) in which diffeormphisms are generated from time-varying velocity fields (as opposed to the stationary ones in the SVF framework). The LDDMM framework has not been used much in unsupervised deep learning for generating diffeomorphims due to its computational cost, but some works do exist (Shen et al., 2019b; Ramon et al., 2022; Wang et al., 2023), and others which are inspired by the framework but make significant modifications, and as a result lose the by construction topology preserving properties (Wang and Zhang, 2020; Wu et al., 2022; Joshi and Hong, 2023). SyN is to our knowledge the first work suggesting matching the images in the intermediate coordinates for achieving symmetry, the idea which was also used in our work. However, the usual implementation of SyN in ANTs (Avants et al., 2009) is not as a whole symmetric since the affine registration is not applied in a symmetric manner.
SyN has performed well in evaluation studies between different classical registration methods. e.g. (Klein et al., 2009). However, it is significantly slower than the strong baselines included in our study, and has already earlier been compared with those(Balakrishnan et al., 2019; Mok and Chung, 2020a, b), and hence was not included in our study.
F.2 Deep learning methods (earlier work)
Unlike the optimization based methods above, deep learning methods train a neural network that, for two given input images, outputs a deformation directly. The benefits of this class of methods include the significant speed improvement and more robust performance (avoiding local optima) (De Vos et al., 2019). Our model belongs to this class of methods.
SYMNet by Mok and Chung (2020a) uses as single forward pass of a U-Net style neural network to predict two stationary velocity fields, and (in practice two 3 channeled outputs are extracted from the last layer features using separate convolutions). The stationary velocity fields are integrated into two half-way deformations (and their inverses). The training loss matches the images both in the intermediate coordinates and in the original coordinate spaces (using the composed full deformations). While the network is a priori symmetric with respect to the input images, changing the input order of of the images (concatenating the inputs in the opposite order for the U-Net) can in principle result in any two and (instead of swapping them), meaning that the method is not symmetric by construction as defined in Section 1 (this is confirmed by the cycle consistency experiments).
Our method does not use the stationary velocity field (SVF) framework to invert the deformations, but instead uses the novel deformation inversion layer. Also, SYMNet does not employ the multi-resolution strategy. The use of intermediate coordinates is similar to our work.
MICS by Estienne et al. (2021) uses a shared convolutional encoder to encode both input images into some feature representations and . A convolutional decoder network is then used to extract gradient volumes (constrained to contain only positive values) of the deformations for both forward and inverse deformations with formulas
| (32) |
The final deformations are obtained from the gradient volumes by a cumulative sum operation. Since gradients are constrained to be positive the resulting deformation will be roughly invertible. However, as stated in their work, this only puts a positive constraint on the diagonal of the Jacobians, not on its determinant, unlike our work which guarantees positive determinants (Theorem 3).
While MICS is symmetric by construction in the sense that swapping and will result in swapping the predicted forward and inverse deformations, this symmetry is achieved by subtraction (Equation 32) instead of mathematical inverse operation (as in our work, Equation 2). As a result the predicted ”forward” and ”inverse” deformations are not actually by construction constrained to be forward and inverse deformations of each other. MICS uses a loss to enforce this. Also, while MICS employs a multi-step approach, the symmetric by construction property is lost over the whole architecture due to not using the intermediate coordinate approach employed by our work.
Additional baselines: In addition to SYMNet, cLapIRN(Mok and Chung, 2021) was chosen as a baseline because it was the best method on OASIS dataset in the Learn2Reg challenge (Hering et al., 2022). It employs a standard and straightforward multi-resolution approach, and is not topology preserving, inverse consistent, or symmetric. Apart from the multi-resolution approach, it is not methodologically close to our method. VoxelMorph (Balakrishnan et al., 2019) is a standard baseline in deep learning based unsupervised registration, and it is based on a straightforward application of U-Net architecture to image registration.
F.3 Deep learning methods (recent methods parallel with our work)
These methods are very recent deep learning based registrations methods which have been developed independently of and in parallel with our work. A comparison with these methods and our model is therefore a fruitful topic for future research.
Iglesias (2023) uses a similar approach to achieve symmetry as our work but in the stationary velocity field (SVF) framework. In SVF framework, given some velocity field , we have the property that where represents the integration operation (Arsigny et al., 2006) generating the deformation from the velocity field. Hence to obtain symmetric by construction method, one can modify the formula 2 to the form
| (33) |
which will result in a method which is symmetric by construction, inverse consistent, and topology preserving. We measure memory usage against this formulation in Appendix E and show that our formulation using the novel deformation inversion layer requires storing times less memory for the backward pass. Their method includes only a single registration step, and not the robust multi-resolution architecture like ours.
Greer et al. (2023) extends the approach the approach by Iglesias (2023) to multi-step formulation in very similar way to how we construct our multi-resolution architecture by using the intermediate coordinates (square roots of deformations). They also employ the SVF framework, as opposed to our work which uses the deformation inversion layers, which, as shown in Appendix E, requires storing times less memory for the backward pass, which is significant for being able to train the multi-step network with many steps on large images (such as our OASIS raw data). Also, their paper treats the separate steps of multi-step architecture as independent whereas we develop very efficient multi-resolution formulation based on first extracting the multi-resolution features using ResNet-style encoder.
Zhang et al. (2023) propose a symmetric by construction multi-resolution architecture that is similar to ours. Differences include again using the SVF framework, as well as applying losses at different resolutions, as opposed to us only applying them at the final level.
G Deformation inversion layer practical convergence
We conducted an experiment on the fixed point iteration convergence in the deformation inversion layers with the model trained on OASIS dataset. The results can be seen in Figure 5. The main result was that in the whole OASIS test set of 9591 pairs not a single deformation required more than 8 iterations for convergence. Deformations requiring 8 iterations were only of all the deformations and a significant majority of the deformations () required to iterations. In all the experiments, including this one, the stopping criterion for the iterations was maximum displacement error within the whole volume reaching below one hundredth of a voxel, which is a very small error.
H Additional visualizations
Figures 6, and 7 visualize the differences in inverse consistency, and cycle consistency respectively.
Figures 8 and 9 visualize dice scores for individual anatomical regions for both OASIS and LPBA40 datasets. VoxelMorph and SYMNet perform systematically worse than our method, while cLapIRN and our method perform very similarly on most regions.
Figure 10 visualizes how the deformation is being gradually updated during the multi-resolution architecture.


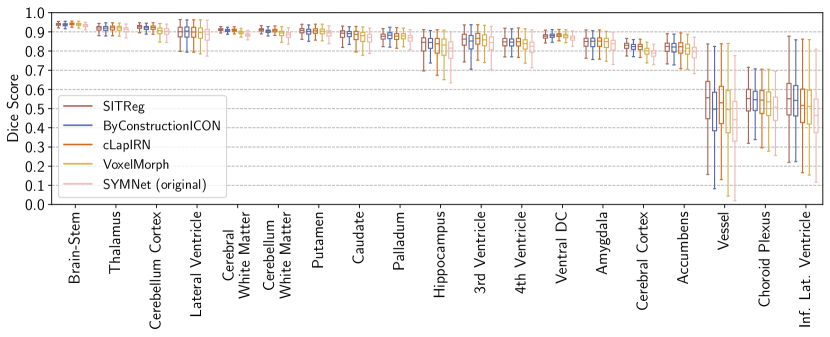
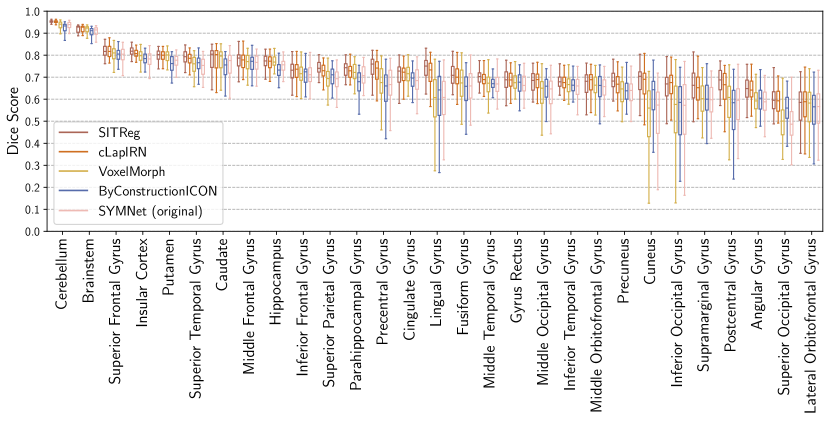

I Details on statistical significance
We computed statistical significance of the results comparing the test set predictions of the trained models with each other. We measured the statistical significance using permutation test, and in practice sampled permutations.
To establish for certain the relative performance of the methods with respect to the tight metrics, one should train multiple models per method with different random seeds. However, our claim is not that the developed method improves the results with respect to a single tight metric but rather that the overall performance is better by a clear margin (see Section 6).
J Clarifications on symmetry, inverse consistency, and topology preservation
Here we provide examples of symmetry, inverse consistency and lack of topology preservation to further clarify how the terms are used in the paper.
Since symmetry and inverse consistency are quite similar properties, their exact difference might remain unclear. Examples of registration methods that are inverse consistent by construction but not symmetric are many deep learning frameworks applying the stationary velocity field (Arsigny et al., 2006) approach, e.g, (Dalca et al., 2018; Krebs et al., 2018, 2019; Mok and Chung, 2020a). All of them use a neural network to predict a velocity field for an ordered pair of input images. The final deformation is then produced via Lie algebra exponentiation of the velocity field, that is, by integrating the velocity field over itself over unit time. Details of the exponentiation are not important here but the operation has an interesting property: By negating the velocity field to be exponentiated, the exponentiation results in inverse deformation. Denoting the Lie algebra exponential by , and using notation from Section 1, we can define such methods as
| (34) |
where is the learned neural network predicting the velocity field. As a result, the methods are inverse consistent by construction since (accuracy is limited by spatial sampling resolution). However, by changing the order of inputs to , there is no guarantee that and hence such methods are not symmetric by construction.
MICS (Estienne et al., 2021) is an example of a method which is symmetric by construction but not inverse consistent. MICS is composed of two components: encoder, say , and decoder, say , both of which are learned. The method can be defined as
| (35) |
As a result, the method is symmetric by construction since holds exactly. However, there is no architectural guarantee that and are inverses of each other, and the paper proposes to encourage that using a loss function. In the paper they use such components in multi-steps manner, and as a result the overall architecture is no longer symmetric.
Lack of topology preservation means in practice that the predicted deformation folds on top of itself. An example of such deformation is shown in Figure 11.